Материалы к спецкурсу ОС (Unix)
ЗАНЯТИЯ март-май 2020 года
В связи с эпидемией коранвируса очные занятия 23, 30 марта и 6 апреля
Здесь будет выкладываться информация на материалы для самостоятельного изучения и ссылки на записи лекций в youtube.
2020.03.23
Работа с файлами
Литература: Робачевский. ОС Unix. Глава 2. "Работа с файлами"
Чтение и запись файлов вызовами read и write. Возвращаемые значения. Признак конца файла при чтении и при записи (запись в закрытый канал связи).
lseek Перемещение головки ввода/вывода вызовом lseek. Получение текущей позиции вызовом lseek.
Понятие блокировки файлов . Вызовы locf и fcntl (эквивалентны в Linux). Кооперативная работа с блокировками (отсутствие обязательных блокировок, как в Windows).
Чтение каталога библиотечными функциями opendir(3), readdir(3) и т.д.
Самостоятельно отследить цепочку структур в ядре Linux, которые используются для выделения файлового дескриптора при открытии файла; хранения позиции головки ввода/вывода; хранения блокировок и счётчиков количества "открытий" файла при совместном использовании файла. Выдержки из кода ядра.
Тестовые вопросы (ответы мне на почту):
- Один из процессов установил блокировку целого файла на чтение вызовом fcntl (locf). Удастся ли другому процессу открыть файл на чтение вызовом open()? Удастся ли прочитать из файла вызовом read()?
- Какое значение вернет вызов read(fd, buf, 1024) если в файле, на который ссылается fd всего 2 байта? Какое значение вернёт тот же вызов если его сразу же выполнить повторно?
2020.03.30
Наследование открытых файлов. Перенаправление ввода/вывода. Каналы.
Литература: Робачевский. ОС Unix. Глава 2. "Работа с файлами"; Глава 3. "Создание процесса" (первые две страницы)
Создание нового процесса и загрузка в процесс новой программы (описание fork() и exec())
Наследование открытых файлов при порождении дочерних процессов.
Неименованный канал pipe и использование его для связи с дочерним процессом.
Правила ввода/вывода для неименованных (pipe) и именованных (FIFO) каналов.
Контрольные вопросы (мне на почту):
- В чем преимущество последовательности
fd=open("file"...); dup2(fd,0); close(fd);передclose(0); open("file"...);, что между ними общего? - Можно ли файловые дескрипторы fd1 и fd2, созданные командами
fd1=dup(fd); fd2=dup(fd), использовать для независимого доступа к файлу в разных потоках? - Что произойдёт, если единственный процесс откроет объект FIFO (например /tmp/myfifo) на чтение и попробует прочитать один байт?
3.1 ...откроет на запись и попробует записать один байт?
3.2. ...откроет на чтение и на запись и попробует записать один байт?
3.2.1 ...после чего попробует прочитать один байт?
3.2.2...после чего попробует прочитать ещё один байт?
2020.04.06
Виртуальная файловая система
Литература:
- Робачевский. ОС Unix. Глава 4. "Файловая подсистема. Архитектура виртуальной файловой системы"
- Д.Бовет, М. Чезатти Ядро Linux Глава 12. "Виртуальная файловая система"
Видео: Виртуальная файловая система, Разбор имени файла в VFS
Виртуальная файловая система как абстрактный класс
Разбор имени файла в VFS. Монтирование. Символические ссылки.
Контрольные вопросы (мне на почту):
- Может ли Unix быть запущен без монтирования хотя бы одной файловой системы?
- Что должен делать драйвер файловой системы, если какая-то возможность в ФС не может быть реализована?
Пример: вызов
chown()(смена владельца) – неприменим к FAT. - Обобщённый inode содержит поле i_no - уникальный номер inode в данной ФС. Предложите алгоритм генерации значения этого поля в FAT (компактное описание FAT начиная с раздела "Так зачем нужна таблица FAT?").
- Опишите механизм, который при разборе имени файла будет защищать от циклических символических ссылок.
2020.04.13
Процессы. Основные понятия, виртуальная память, планировщик процессов
Литература:
- Робачевский. ОС Unix. Глава 3. "Подсистема управления процессами" Разделы: "Основы управления процессом", "Структуры данных процесса", "Состояния процесса"
- Д.Бовет, М. Чезатти Ядро Linux Глава 7. "Планирование процессов"
Видео: Основные понятия, виртуальная память, многозадачность, Основы планирования процессов
Общие сведения о процессах. Особый процесс init..
Для ознакомления: Начальная загрузка Linux
Контрольные вопросы (мне на почту):
- Какие существуют варианты (причины) завершения процесса?
- Сформулируйте две основные функции процесса init (pid=1) по отношению к остальным процессам.
- Предположим, что в системе запущен всего один процесс (вопрос: чему равен его PID?), который выполни код:
fork();
fork();
3.1. Сколько процессов теперь запущено в сиcтеме? 3.2. Сколько дочерних процессов образовалось у первоначального процесса?
2020.04.20
Сигналы
Литература:
- Робачевский. ОС Unix. Глава 2. "Среда программирования Unix" Раздел: "Процессы - Сигналы"
- Д.Бовет, М. Чезатти Ядро Linux Глава 11. "Сигналы"
Дополнительно для желающих вникнуть в тонкости: Правила использования сигналов в Unix
Видео: Сигналы в Unix
Методичка: Страница "Сигналы" с подразделами, кроме "Управляющий терминал, сеанс, группы".
- Вы пишете процедуру в большой программе и хотите для отладки послать собственному процессу сигнал ABRT (завершение+дамп памяти). Что надо предпринять, чтобы сигнал был доставлен даже в том случае, когда программисты, пишущие другие части программы что-то настроили в доставке сигналов?
- Вызов alarm(nsec) заводит в ядре таймер, который вызовет посылку сигнала SIGALRM через nsec секунд. Можно ли рассчитывать, что ровно через nsec секунд будет вызван обработчик сигнала?
- Вызов pause() приводит к приостановке процесса до прихода какого-либо сигнала. Напишите функцию mysleep(nsec), которая приостановит процесс, но не более чем на nsec секунд.
- Напишите программу, которая в цикле читает строку и завершается по строке "quit". Сделайте так, чтобы по нажатию Ctrl-C выдавалась подсказка: "Для завершения введите quit". Рекомендация: не печатайте этот текст в обработчике сигнала, а используйте глобальную переменную для оповещения основного цикла.
2020.04.27
Память процесса. Страничная организация. Области памяти.
- Робачевский ОС Unix. Глава 3. "Управления процессами" Разделы: "Принципы управления памятью-Адресное пространство процесса", "Управление памятью процесса"
- Д.Бовет, М. Чезатти Ядро Linux Глава 9. "Адресное пространство процесса", Раздел "Адресное пространство процесса"
- Роберт Лав Ядро Linux: описание процесса разработки. Глава 12. "Управление памятью". Раздел "Страничная организация памяти"; Глава 15 "Адресное пространство процесса" Разделы "Адресные пространства" и "Области виртуальной памяти"
Видео: Unix. Память процесса
Методички:
Вопросы:
- Через просмотр файлов карт памяти процессов /proc/XXX/maps (где XXX - это числовой идентификатор процесса) проверьте, отображается ли стандартная библиотека языка C (libc-NN.N.so) всегда на одни и те же виртуальные адреса или адреса варьируются.
- Объясните, почему исполняемый файл программы присутствует в карте памяти трижды.
- На основе изучения карт памяти выскажите предположение, используется ли при доступе всех процессов к стандартной библиотеке языка C одна копия отображения файла в физическую память или каждый процесс держит свою собственную копию в физической памяти.
- Скомпилируйте в своём Linux тестовую программу, нарисуйте в виде таблички (или от руки на бумаге) карту адресов подобную схеме с указанием начала каждой области.
2020.05.04
Память процесса. Управление распределением памяти.
- Робачевский ОС Unix. Глава 2. "Среда программирования Unix" Разделы: "Файлы отображаемые в память", "Ограничения", "Выделение памяти"
- Д.Бовет, М. Чезатти Ядро Linux Глава 9. "Адресное пространство процесса", Разделы "Обработчик исключения "ошибка обращения к странице" и "Управление кучей"; Глава 19. "Взаимодействие процессов", Раздел "Совместно используемая память IPC"
Видео: Unix. Память процесса
Методичка:
Вопросы:
- Как в программе на Си узнать в какую сторону растёт стек? (псевдокод 3-4 строки)
- Что в файле с исполняемой программой находится в секции .text?
- Каков будет результат операции
char *ptr=(char *)sbrk(0)-1;
*ptr=1;
ptr+=2;
*ptr=1;
2020.05.11
Межпроцессное взаимодействие System V IPC
Робачевский ОС Unix. Глава 3. "Управления процессами" Раздел: "Взаимодействие процессов".
Д.Бовет, М. Чезатти Ядро Linux Глава 19. "Взаимодействие процессов", Раздел "Схема межпроцессного взаимодействия System V IPC"
Видео: System V IPC
Методичка:
Вопросы:
- Можно ли использовать вызовы read и write для чтения/записи очереди сообщений System V IPC?
- Исчезнут ли данные в общей памяти System V IPC после завершения процесса?
- Исчезнут ли семафоры System V IPC после завершения создавшего их процесса? Изменятся ли их значения?
- И ключ IPC и идентификатор IPC - это 32-битные числа. В чём между ними разница?
- Команда ipcs показывает несколько объектов с одинаковыми ключами 0x00000000 и разными идентификаторами. Что такое ключ 0x00000000?
2020.05.18
Межпроцессное взаимодействие - сокеты
- Робачевский ОС Unix. Глава 3. "Управления процессами" Раздел: "Межпроцессное взаимодействие в BSD UNIX. Сокеты".
Для расширения кругозора можно взглянуть на альтернативу сокетам в классическом Unix - Робачевский ОС Unix. Глава 5 "Подсистема ввода/вывода" Раздел "Архитектура STREAMS"
Видео: Сокеты в Unix
Методичка:
Вопросы:
- Краткая характеристика двух основных типов сокетов
- Есть ли разница между сокетами клиента и сервера для сокета датаграмм? (предполагаем, что оба вызвали bind())
- Есть ли разница между сокетами клиента и сервера для сокета потока?
- Напишите псевдокод на основе select(), который ожидает ввода данных с stdin и печатает их на stdout. а если входных данных нет, то раз в полсекунды печатает в stderr - "нет данных".
| Прикрепленный файл | Размер |
|---|---|
| 52.08 КБ |
Слабые стороны Unix
В момент своего создания в 1970-х годах Unix был очень простой ОС, созданной как один большой хак. Многие детали внутреннего устройства UNIX появились на свет просто по тому, что у авторов не было времени и желания писать сложный код там, где можно было обойтись временной "затычкой". К сожалению, в тот момент когда Unix стал популярной системой, одновременно произошли две вещи - а) стало понятно, что многие архитектурные решения, заложенные в Unix, не годятся для реальной ОС и б) уже ничего нельзя сделать не потеряв совместимости с существующими программами.
Ниже приведен конспект книги The UNIX-HATERS Handbook под редакцией Simson Garfinkel, Daniel Weise и Steven Strassmann, опубликованной IDG Books в 1994 году. За последние двадцать лет несколько из упомянутых в книге ошибок были сглажены, но в целом ситуация в мире Unix/Linux осталась прежней, поскольку слабость Unix'а заложена в самых базовых его концепциях.
"Два самых знаменитых продукта, вышедших из стен университета в Беркли, это LSD и Unix. И похоже что это не случайное совпадение" (Anonymous)
Unix это вирус - он маленький, переносимый, жрёт ресурсы хозяина, быстро мутирует.
Unix это наркотик. Как опытный наркоделец AT&T раздавала первые версии бесплатно.
Что означают названия языков C и C++? Это оценки. (В США оценки обозначаются буквами А - отлично, В - хорошо, С - так себе).
Мифы о Unix'е
- Он стандартен
- Он быстр и эффективен
- Он пригоден для любых приложений
- Он маленький простой и элегантный
- Шелловские программы и пайпы позволяют создавать сложные системы
- Он имеет электронную документацию
- Он имеет документацию
- Он написан на языке высокого уровня
- X-Window и Motif (Gnome, KDE) делают его дружественным к пользователю как Mac (Windows)
- Процессы не добавляют накладных расходов
- Он ввёл в обиход:
- иерархическую файловую систему
- электронную почту
- сетевые и интернетовские протоколы
- удалённый доступ к файлам
- секретность/пароли/права доступа к файлам
- программу finger
- единообразный подход к устройствам ввода/вывода
- Он предоставляет удобную среду программирования
- Он - современная ОС
- Он, то что нужно людям
- Исходные коды:
- доступны
- понятны
- соответствуют двоичному коду, который вы запускаете
Мистические имена
На ранних этапах разработки Unix в качестве терминала использовалась электрическая пишущая машинка - телетайп. Поскольку по клавишам приходилось бить с большой силой, программисты старались давать командам загадочные, но короткие имена - rm, cp, wc и т.п. Теперь ситуация изменилась, многие используют оконные системы и оболочки с автодополнением, но переименовать команды во что-то более осмысленное уже нельзя, не потеряв совместимость с миллионами накопленных скриптов.
Случайная порча данных в Unix'е
- Unix не поддерживает версии файлов. Случайное изменение нельзя откатить.
- Многие Unix программы (на момент написания) не проверяют коды ответов системных вызовов. Такая программа может получить ошибку при создании копии файла, но всё равно уничтожить первоисточник.
- Шелл выполняет подстановку метасимволов, таких как "*", не сохраняя для программы исходные параметры. В отличие от DOS, где команда
del *.*выдаёт предупреждение пользователю, в Unix невозможно отличитьrm *отrm file1 file2 file3... - Файлы в Unix'е удаляются мгновенно без возможности последующего восстановления.
Примеры:
Опечатка rm *>o вместо rm *.o уничтожит все файлы в каталоге и создаст пустой файл "o" . Лишний пробел в rm * .o также приведёт к печальным последствиям.
Удаление администратором подкаталога, совпадающего по имени со стандартным - опасно. Вместо rm -r ./etc легко напечатать rm -r /etc, что убьёт систему. Unix не предусматривает особой защиты для системных каталогов.
Замена rm на альяс rm -i или на что-то совсем другое (например mv $@ ~/.Deleted) не является панацеей, т.к. не влияет на команды удаления файлов, встроенные в оконную систему, среду разработки и т.п. Кроме того использование альяса может нарушить работу скриптов (скрипт начнёт запрашивать подтверждения) и сбить с толку сисадмина, который будет пытаться понять, почему у пользователя неверно работает программа.
Команда rm *, выполненная в одном каталоге, сохраняется в истории команд и может быть случайно вызвана в другом подстановкой !r (последняя команда в истории на букву r).
Удаление файла с именем "*" - отдельное искусство.
Отсутствие стиля как стиль
Программы в Unix не имеют общего стиля. Каждый волен придумать свой набор опций, свой конфигурационный файл и свою систему оповещения об ошибках. Не существует требования по использованию определённых библиотек. Так ed, sed, grep и shell имеют схожие, но различные форматы регулярных выражений.
Заявленная философия простоты и самодостаточности отдельных утилит (делает мало, но делает хорошо) в реальном Unix'е не соблюдается. Простейшая команда cat, изначально предназначенная для объединения содержимого нескольких файлов в один поток, имеет несколько опций, которые предполагают, что команда используется для просмотра содержимого файла на терминале.
С другой стороны плодятся лишние программы. Вместо программы, вырезающей несколько строк из середины файла, существуют программы head- вырезание строк из начала файла и tail - вырезание из хвоста. Программы написаны разными авторами имеют разный набор опций.
Уже упоминалось, что подстановка "*" при обработке шеллом (вместо использования стандартной функции в самой программе) приводит к потере части информации о командной строке. В сочетании с тем, что Unix не отличает в командной строке имена файлов от опций, это приводит к катастрофическим последствиям. Имена файлов, начинающиеся с "-" нельзя отличить от опций. Например, команда rm * в каталоге, содержащем файл "-r" приведёт к рекурсивному удалению подкаталогов, но сохранит сам файл "-r".
Обратная ситуация. Некоторые утилиты могут воспринимать имена файлов, начинающиеся с "-" как неверные опции и не смогут обработать такие файлы:
$ mv -file file
mv: invalid option -- l
$ rm -file
usage: rm [-rif] file ...
$ rm ?file
usage: rm [-rif] file ...
$ rm ?????
usage: rm [-rif] file ...
$ rm *file
usage: rm [-rif] file ..
(В современном Linux'е выдаётся подсказка Try 'rm ./-file' to remove the file '-file', но само поведение команды не изменилось).
MAN-страница по rm в Linux'е предлагает использовать rm -- -foo для удаления -foo, но это не является частью стандарта. Авторам оригинальной книге в MANе предложили использовать rm - -foo.
Шутка с ls. Готовим каталог и файл
% mkdir foo
% touch foo/foo~
Теперь зовём ничего не подозревающего соседа и просим объяснить результат выполнения команд
% ls foo*
foo~
% rm foo~
rm: foo~ nonexistent
% rm foo*
rm: foo directory
% ls foo*
foo~
%
Попробуйте объяснить, что делает команда cat - - - (подсказка: тройное нажатие ^D завершит её работу).
Электронная документация
Основой электронной документации в Unix являются man-страницы. К сожалению, часть команд являются исполняемыми файлами (wc,ls,rm), а часть встроенными командами шелла (fg,job,alias). man-страницы описывают внешние команды и шелл в целом. Если новичок не знает какой у него шелл, он не сможет добраться до описания встроенных команд.
Предупреждения и сообщения об ошибках в Unix - ИХ НЕТ!
Ошибка в порядке написания имён файлов cc -o prog.c prog вместо cc -o prog prog.с при запуске компилятора молча уничтожит исходные тексты. Ошибка в опциях архиватора tar cf bigarchive.tar вместо tar xf bigarchive.tarмолча уничтожит архив.
Управление терминалом
То, что ранние версии Unix'а разрабатывались на компьютере с примитивным телетайпом в качестве терминала, привело к тому, что в ядре Unix'а вообще отсутствуют средства для работы с интеллектуальными средствами взаимодействия с пользователями.
Телетайпы умели построчно печатать текст и (по приходу специального символа) переходить на следующую строку (NL \n), возвращать каретку в начало строки (CR \r) и звенеть звонком (BELL \b). После телетайпов на рынок вышли текстовые видео терминалы, которые выводили текст существенно быстрее и позволяли (с помощью управляющих последовательностей символов) проделывать разные трюки с текстом на экране. К сожалению, у разных производителей управляющие последовательности были разными.
Бил Джой во время разработки редактора vi создал базу управляющих последовательностей - termcap, которая позволяла извлекать последовательности, выполнявшие определённые функции на конкретном терминале. К сожалению termcap отражала не те функции, которые были придуманы производителями, а те которые были нужны для работы редактора vi. (В последующем набор функций был несколько расширен, но сути дела это не меняет). Кроме того, код работавший с termcap в vi так и не был оформлен в отдельную библиотеку, что заставляло программистов самостоятельно изобретать собственные API.
В конце концов Кен Арнольд написал библиотеку для управления текстовым терминалом под названием curses. К сожалению, библиотека ориентировалась на ту же урезанную базу терминальных функций termcap и к тому же была не очень профессионально написана. В результате curses стала полустандартом в мире Unix. В книге есть фраза: ...и сейчас в 1994 году стандарта управления терминалом по прежнему нет. Нет его и двадцать лет спустя.
Вместо того, чтобы включить в ядро вызовы для манипулирования с абстрактным терминалом, разработчики Unix'а вынесли всю логику в относительно стандартные библиотеки или вообще зашили работу с терминалом в код программ. В первую очередь такой подход лишил Unix-программы совместно использовать один экран. Кроме того, в Unix (отчасти из из за идеи, что всё есть последовательный файл, а отчасти из за ограничений termcap и curses) никогда не была реализована работа с "умными" терминалами, которые позволяют создавать экранные формы, рисовать изображения и т.п.
Даже в тех случаях, когда можно было программно реализовать любой механизм управления экраном, например в виртуальной консоли Linux или в графическом оконном терминале xterm, разработчики шли по пути эмуляции относительно примитивного текстового терминала vt100. И всё это лишь для того, чтобы обеспечить совместимость с редактором vi.
Ссылки на документацию по Unix
Конспект лекций к курсу ОС Unix
Робачевский А. М., Немнюгин С. А., Стесик О. Л. Операционная система UNIX. — 2-е изд., перераб. и доп. — СПб. БХВ-Петербург, 2010. - 656 с : ил. ISBN 978-5-94157-538-1
Д.Бовет, М. Чезатти Ядро Linux 3-е издание СПб. БХВ-Петербург, 2007
POSIX.1-2008. The Open Group Base Specifications Issue 7
Oracle. Solaris. Programming Interfaces Guide
SCO. Unixware 7. UnixWare 7 Documentation
Illustrated UNIX System V/BSD - книга 1992 года. Интересна тем, что в ней комментируются различия в семантике некоторых операций в различных реализациях Unix.
А.П. Полищук, С.А. Семериков СИСТЕМНОЕ ПРОГРАММИРОВАНИЕ В UNIX средствами Free Pascal Книга основана на UNIX System Programming: A programmer’s guide to software development by Keith Haviland, Dina Gray, Ben Salama. Кроме качественного перевода (пересказа) оригинала, книга расширена ссылками на особенности реализации некоторых системных вызовов в Linux и FreeBSD. Выбор нетипичного для Unix языка программирования не сильно мешает, но требует самостоятельного поиска имён стандартных функций языка C, которые подменены в примерах обёртками на Паскале.
| Прикрепленный файл | Размер |
|---|---|
| 11.07 МБ |
Inode и каталоги
В традиционной файловой системе (ФС) Unix доступный объём физического носителя делится между блоками данных и областью хранения метаданных - Inode. Количество Inode определяет максимальное число объектов (файлов, каталогов, сокетов и т.п) которые может хранить ФС. При форматировании ФС. Необходимо соблюдать баланс между данными и метаданными. При заполнении ФС мелкими файлами возможна ситуация, когда при свободной области данных исчерпывается запас Inode и создание новых файлов становится невозможным.
Просмотр числа inode в ФС - команда df -i. Просмотр числа блоков данных команда df
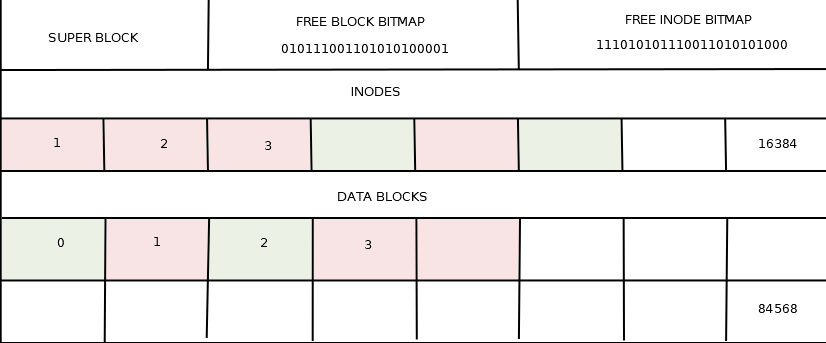
Суперблок
Суперблок хранит информацию о "геометрии" файловой системы: размещение таблицы inode на диске, число inode, число свободных inode, размещение начала блоков данных, число блоков данных, число свободных блоков и т.п.
Битовые карты
Битовые карты блоков данных и inode помечают занятые блоки/inode. 0 - элемент свободен, 1 - занят.
Inode
C каждым файлом в ОС Unix связана особая структура данных - индексный дескриптор (inode), хранящий метаинформацию файла (владелец, права доступа и т.п.).
Индексные дескрипторы в оригинальной UnixFS объединялись в последовательно нумерованный (индексированный) массив, что и дало название структуре. В современных ФС эта структура может иметь разные размеры и набор полей или отсутствовать вовсе. Соответственно, классические утилиты мониторинга ФС могут выдавать неверные данные о количестве занятых и свободных inode.
В реализации API доступа к ФС inode – это стандартизованная структура данных для обобщённого представления атрибутов файла. В оперативной памяти индексный дескриптор может быть представлен в виртуальном виде – vnode. Для ФС , не хранящих индексные дескрипторы, vnode создаётся на основе других подходящих источников данных.
Номер индексного дескриптора уникален в рамках одной ФС, однако, при монтировании нескольких ФС в одно дерево номера индексных дескрипторов будут повторяться. Поэтому vnode хранит номер индексного дескриптора плюс идентификатор ФС, в которой он находится. Для дисковых ФС в Linux номером ФС является число, составленное из мажора и минора блочного устройства, на котором ФС расположена. Для NFS, похоже, номер ФС определяется порядком монтирования и последовательно возрастает начиная с 1Ah.
Блоки данных
Размещение данных файла в блоках описывается ссылками, хранящимися в inode файла
| Прикрепленный файл | Размер |
|---|---|
| 16.03 КБ |
{kind=link}
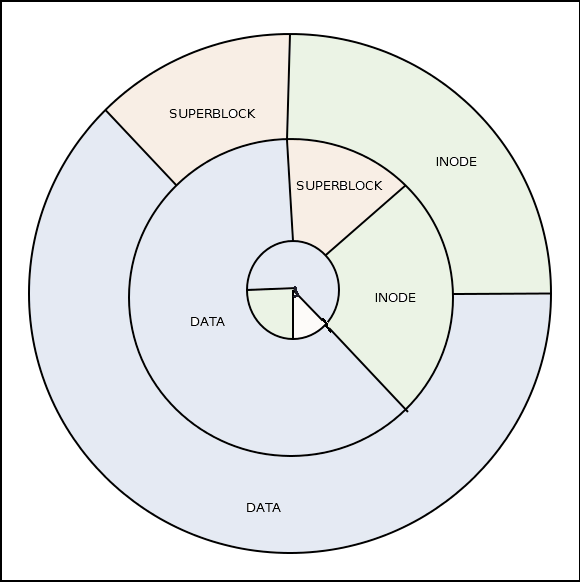
Оптимизация дискового доступа в FFS
Оригинальная файловая система Unix (UFS) имела несколько явных недостатков:
- Суперблок был единичной точкой отказа. Его физическое разрушение приводило к полной потере доступа к данным на диске.
- Inode и блоки данных хранились на разных дорожках, что требовало непрерывных перемещений магнитной головки при доступе к файлам.
Для решения этих проблем в Быстрой файловой системе (FFS) дорожки диска были разбиты на группы, каждая из которых имела структуру полной файловой системы. Таким образом суперблок дублировался во всех группах, а inode и блоки данных внутри группы размещались на соседних дорожках.
Подобное деление на группы сохранилась и в семействе ФС Extfs в Linux.
| Прикрепленный файл | Размер |
|---|---|
| 53.71 КБ |
{kind=link}
Каталоги
Каталоги
Древовидную структуру файловой системы в Unix обеспечивают каталоги, которые хранят таблицу соответствий Имя->inode. В этой таблице требуется уникальность имен, но не уникальность номеров inode. Благодаря этому, каждый объект ФС может иметь несколько имён. Счётчик имён хранится в inode объекта.
В Unix отсутствует операция удаления объекта из ФС. Есть только операция удаления имени из каталога - unlink. Объект, у которого нет имён и который не открыт ни одним процессом, удаляется автоматически.
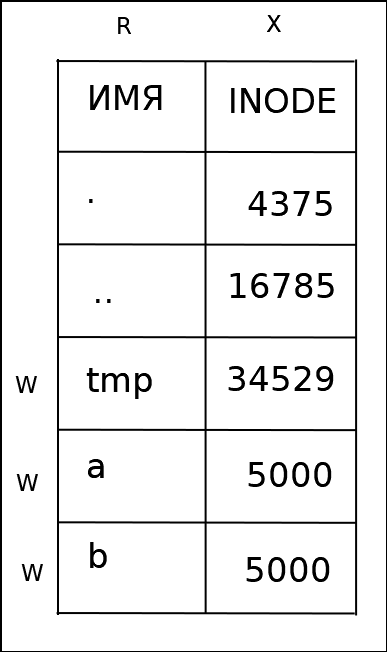
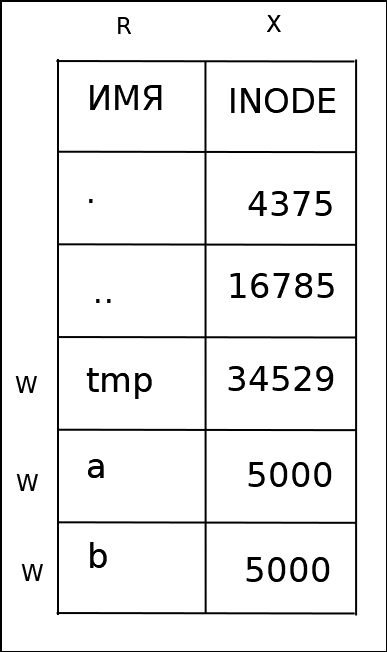
У каталогов есть одно "нормальное" имя, имя '.' в самом каталоге и имя '..' в каждом из подкаталогов. В Linux другие имена для каталога создать нельзя. Нарушение этого правила привело к тому, что в структуре файловой системы могли бы образоваться циклы, а это бы нарушило работу алгоритмов обхода дерева каталогов.
У других типов объектов (файлов, FIFO, файлов устройств, сокетов, символических ссылок) может быть много имен в одном или в нескольких каталогах. Такие имена называют "жёсткими ссылками" (hard links), поскольку они гарантированно ссылаются на существующий inode. Поскольку нумерация Inode в каждой файловой системе своя, жёсткие ссылки могут указывать только на объекты в той же файловой системе, что и каталог, в котором они опубликованы.
В противоположность этому, символические или "мягкие" ссылки (symlinks, soft links) - это особые объекты файловой системы, которые хранят, вообще говоря, произвольные текстовые строки, интерпретируемые, как пути к файлам. Мягкие ссылки могут ссылаться на несуществующие объекты и не отражаются в счетчике Inode.
В Linux обычные пользователи могут создавать жёсткие ссылки лишь на объекты, владельцами которых они являются, поскольку это требует права на запись в счётчик имён в inode.
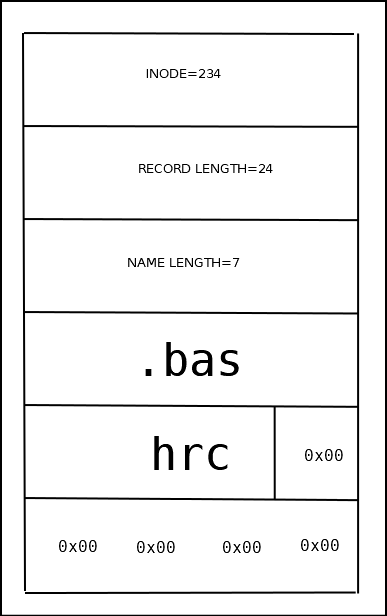
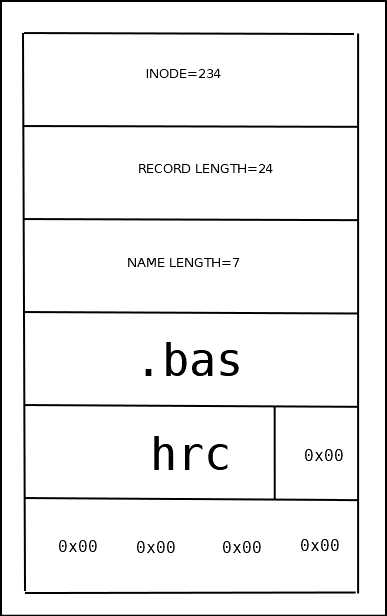
Для оптимизации операции удаления файлов в структуре каталога хранится размер записи и длина имени. При удалении записи из каталога она фактически остаётся на прежнем месте. Поле общей длины предыдущей записи увеличивается на размер удалённой записи. При создании новых записей переиспользуется место, оставшееся от удалённых записей.
| Прикрепленный файл | Размер |
|---|---|
| 11.13 КБ | |
| 8.55 КБ |
{kind=link}
{kind=link}
Выделение блоков данных под каталоги в ext2fs
При создании каталога ему выделяется 0 блоков данных и 152 байта внутри inode.
До тех пор, пока новые записи direntry помещаются в 152 байта (7 записей с именами короче 4 байт) блоки данных не выделяются. После превышения размера в 152 байта начинают выделяться блоки данных. Блоки выделяются с запасом, чтобы обеспечить отсутствие фрагментации.
При создании новой записи direntry происходит просмотр каталога блок за блоком в поисках уже существующей записи direntry в хвосте которой есть свободное место для создания новой direntry.
Если свободное место не обнаружено, то размер каталога увеличивается на один блок и новая запись direntry занимает новый блок целиком.
При удалении записей direntry из каталога блоки данных никогда не освобождаются, но могут переиспользоваться, путём размещения новых direntry на свободных местах, оставшихся после удалённых direntry.
Последняя запись direntry в блоке всегда имеет такой размер, чтобы запомнить блок до конца, поэтому размер каталога всегда кратен размеру блока.
Структура Inode
Атрибуты файла, хранящиеся в vnode, могут быть получены вызовом stat/fstat/lstat, который возвращает структуру данных
dev; /* устройство */
ino; /* индексный дескриптор */
mode; /* режим доступа */
nlink; /* количество жестких ссылок */
uid; /* идентификатор пользователя-владельца */
gid; /* идентификатор группы-владельца */
rdev; /* тип устройства */
/* (если это устройство) */
size; /* общий размер в байтах */
blocks; /* количество выделенных блоков */
blksize; /* размер блока ввода-вывода */
/* в файловой системе */
atime; /* время последнего доступа */
mtime; /* время последней модификации */
ctime; /* время последнего изменения */
Из командной строки просмотреть атрибуты можно командой stat
$ stat /bin/ping
File: `/bin/ping'
Size: 40760 Blocks: 88 IO Block: 4096 regular file
Device: fd00h/64768d inode: 113377318 Links: 1
Access: (4755/-rwsr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2014-03-17 08:38:31.000000000 +0600
Modify: 2011-05-21 03:08:42.000000000 +0600
Change: 2012-02-02 11:17:13.000000000 +0600
Метки времени
С каждым объектом ФС Unix связаны три метки времени:
- ctime – время модификации атрибутов файла (inode). Изменяется при смене прав доступа, владельца или группы файла, а также при изменении содержимого файла.
- mtime – время последней записи в файл.
- atime – время последнего доступа к файлу. В зависимости от опций ФС может оставаться неизменным (оптимизация), изменяться при открытии файла, изменяться каждые n-секунд пока файл остаётся открытым. Вызов stat не меняет atime.
Пользователь может произвольно изменить mtime и atime, в том числе на прошлое или будущее время (например, touch -t 200012311800 time.txt). При этом ctime изменится на момент выполнения операции.
Метка времени создания файлов в классическом Unix отсутствует, что довольно неудобно для администраторов.
В конкретных реализациях ФС могут быть и другие метки, но они недоступны через стандартные функции API. Например, в ex2fs есть поле для хранения времени удаления файла dtime, а в Sun StorEdge QFS хранится время создания файла creation time.
Права доступа на файлы и каталоги
В Unix права доступа к объекту ФС хранятся в битовом поле индексного дескриптора (inode). Шестнадцатиразрядное битовое поле, называемое mode, включает в себя четыре бита, определяющие тип объекта, три бита особых признаков (suid, sgid, sticky) и девять бит прав доступа. Правила интерпретации флагов mode (особенно suid, sgid, sticky) и правила манипуляции ими могут отличаться в разных ОС. В данном тексте описываются правила Linux.
Менять права доступа (записывать в inode) может владелец файла или администратор. Члены группы файла никаких особых прав на inode не имеют. Пользователь может отобрать у себя собственные права на чтение и запись в файл, но право на запись в inode (в т.ч. право на смену прав) сохраняется у владельца файла при любых обстоятельствах. Пользователь не может передать право собственности на файл другому пользователю и не может забрать право собственности на файл у другого пользователя.
При смене владельца или группы флаги suid и sgid сбрасываются. Пользователь не может установить флаг sgid на собственный файл, если файл принадлежит группе, в которую сам пользователь не входит.
При создании файла ему всегда назначается основная группа владельца. В дальнейшем владелец может назначить файлу группу, в которую входит сам. Существует как минимум два исключения из этих правил:
- Файлы, создаваемые в каталоге, которому назначен флаг sgid, наследуют группу, к которой принадлежит каталог, даже если создатель файла в эту группу не входит.
- Файлы, создаваемые программой, исполняемому файлу которой назначен флаг sgid, получают группу, которой принадлежит файл программы.
Права доступа включают право на чтение (R__ead), запись (__W__rite) и исполнение (e__X__ecute). Существует три набора прав __rwx для владельца файла (U__ser), группы файла (__G__roup) и остальных (__O__ther). Традиционно права записываются в виде строки из трёх троек __rwx. Тройки расположены слева направо в порядке ugo. Отсутствующее право помечается прочерком. Набор прав также может быть представлен в виде трёхзначного восьмеричного числа, в котором 1 соответствует наличию права, а 0 отсутствию. Например, rwxr-xr-- эквивалентно 7548. Утилита stat позволяет выдать права доступа к файлу в восьмеричном виде путём задания формата %a. Например, для каталога /tmp установлены все права для всех и sticky bit:
$> stat --format=%a /tmp
1777
Права доступа проверяются в момент выполнения системных вызовов, связанных с доступом к файлам и каталогам, таких как creat(), open(), unlink(), exec(). Из трёх наборов прав выбирается тот, который наиболее точно характеризует пользователя, пытающегося получить доступ к файлу. Права для владельца перекрывают ему права для группы и прочих, для остальных членов группы права для группы перекрывают права для прочих.
Права доступа к файлам
Для файла права rw проверяются в момент выполнения вызова ядра open(). При этом права доступа сверяются с флагами доступа, передаваемыми в open. Право x проверяется в момент выполнения вызова exec(). Для выполнения двоичных файлов право на чтение не обязательно. Защищенные от чтения исполняемые файлы нельзя запустить под отладчиком. Для скриптов запуск означает запуск программы интерпретатора, которая получает в качестве первого параметра имя файла скрипта. В этом случае интерпретатор должен открыть файл скрипта на чтение и право r необходимо.
Флаги suid и sgid в сочетании с правом на исполнение изменяют эффективные права процесса в момент выполнения программы из этого файла вызовом exec. Эффективные права соответствуют владельцу (группе владельцев) файла. При наличии права на исполнение suid и sgid отображаются буквой s в позиции флага права на исполнение. Флаг suid (sgid) может быть назначен файлу, не имеющему флага права на выполнение для владельца (группы). При отсутствии права на исполнение suid и sgid отображаются буквой S в позиции флага права на исполнение. Флаг suid без права на выполнение владельцем ни на что не влияет. Флаг sgid без права на выполнение группой используется как признак принудительной блокировки файла при выполнении системного вызова fcntl(fd, F_SETLK,...).
Флаг sticky bit не оказывает в Linux влияния на работу с файлом. Более того, системный вызов chmod() молча игнорирует попытки установить sticky bit, не выдавая ошибки, но и не выполняя действия. В старых версиях Unix sticky bit в сочетании с флагом прав на исполнение указывал, что после завершения программы её код должен быть сохранён в области свопа для быстрого повторного запуска.
Права доступа к каталогам
Каталог можно представить как таблицу, содержащую много записей, каждая из которых состоит из двух полей: имя и номер индексного дескриптора. В этой модели право на запись в каталог означает право на создание и удаление записей, т.е. создание файлов в каталоге, создание новых имен для существующих файлов (link), удаление имен файлов (возможно вместе с файлами) (unlink). Для удаления файла нет необходимости иметь право на операции с файлом, достаточно иметь право на запись в каталог, в котором хранится его последнее имя.
Право на чтение означает для каталога право на получение списка имён (левой колонки в нашей модели), а право на исполнение – доступ к номерам индексных дескрипторов (правой колонке). В норме оба права должны использоваться одновременно. Если отсутствует право на выполнение, то имеющий право на чтение получит список имен файлов в каталоге, но не сможет ни узнать их метаданные (владелец, размер и т.п.), ни получить доступ к данным. Если отсутствует право на чтение, то становится невозможно узнать имена файлов в каталоге. Однако, если имя известно из других источников, то доступ к файлу можно получить стандартным образом.
sticky бит используется для каталогов, запись в которые разрешена группе или остальным. Данный бит указывает на то, что создавать записи в каталоге может любой, имеющий право на запись, а удалять только владелец объекта, на который указывает запись или владелец каталога. sTicky бит обозначается буквой t в позиции права на исполнение для остальных, если само право есть, и буквой T, если такого права нет.
Флаг setgid, установленный на каталог, приводит к тому, что все объекты, создаваемые в этом каталоге, наследуют группу каталога. Создаваемые подкаталоги дополнительно наследуют сам бит setgid.
Флаг setuid, установленный на каталог в System V и Linux, игнорируется. В BSD системах setuid, установленный на каталог, действует аналогично setgid.
ACL
Традиционные права доступа, хранящиеся в поле mode, не позволяют задать права доступа с точностью до пользователя или до группы. Скажем, нельзя распределить права доступа так, чтобы пользователь user1 имел право только на чтение, user2 - только на запись, а user3 - только на исполнение.
Для преодоления подобных ограничений современные реализации Unix поддерживают списки доступа (Access Lists) - ACL. Для хранения списков доступа может резервироваться отдельный inode, что позволяет выделять для них место в области данных ФС, не создавая при этом отдельного видимого файла.
Списки доступа состоят из записей, содержащих тип записи (пользователь, группа, остальные, маска), идентификатор пользователя или группы, флаги прав на чтение, запись и исполнение. Права доступа, содержащиеся в inode обязательно дублируются тремя записями в ACL - владелец, группа, остальные. Маска определяет максимальные права, которые будут доступны через ACL. Если дать кому-либо права rwx, а маска равна r--, то результатом будет право r--. Действие маски не распространяется на владельца файла и на остальных.
Для индикации наличия ACL информационные утилиты добавляют символ + после стандартного списка прав доступа
Команда просмотра ACL
$ getfacl /etc
getfacl: Removing leading '/' from absolute path names
# file: etc
# owner: root
# group: root
user::rwx
group::r-x
other::r-x
Команда изменения acl
setfacl -m u:lisa:r file
устанавливает право на чтение file для пользователя lisa
setfacl -x u:lisa:r file
отбирает право на чтение file для пользователя lisa
Capabilities
В Linux кроме повышения прав программы через флаг setuid, возможно повышений прав на отдельные привилегированные функции - capabilities.
Команда просмотра capabilities
$ getcap /bin/ping
/bin/ping = cap_net_admin,cap_net_raw+p
Команда установки capabilities
setcap capabilities filename
Формат capabilities описан в man cap_from_text.
Макросы для выделения отдельных флагов
| identifier | value | comment |
|---|---|---|
| S_IFMT | F000 | format mask |
| S_IFSOCK | A000 | socket |
| S_IFLNK | C000 | symbolic link |
| S_IFREG | 8000 | regular file |
| S_IFBLK | 6000 | block device |
| S_IFDIR | 4000 | directory |
| S_IFCHR | 2000 | character device |
| S_IFIFO | 1000 | fifo |
| S_ISUID | 0800 | SUID |
| S_ISGID | 0400 | SGID |
| S_ISVTX | 0200 | sticky bit |
| S_IRWXU | 01C0 | user mask |
| S_IRUSR | 0100 | read |
| S_IWUSR | 0080 | write |
| S_IXUSR | 0040 | execute |
| S_IRWXG | 0038 | group mask |
| S_IRGRP | 0020 | read |
| S_IWGRP | 0010 | write |
| S_IXGRP | 0008 | execute |
| S_IRWXO | 0007 | other mask |
| S_IROTH | 0004 | read |
| S_IWOTH | 0002 | write |
| S_IXOTH | 0001 | execute |
Ссылки:
http://www.softpanorama.org/Access_control/Permissions/suid_attribute.shtml
Структуры данных ext2fs
С логической точки зрения ФС образуется за счёт двух элементов: массива индексных дескрипторов и системы каталогов, связывающих имена файлов с номерами индексных дескрипторов. Индексные дескрипторы хранят метаинформацию файлов и ссылки на блоки данных файлов. Каталоги объединены в дерево с двунаправленной системой ссылок между узлами.
Дисковое пространство в ext2fs разбивается на логические блоки размером 1, 2 или 4 КБ. Блоки используются под хранение нескольких служебных структур, массива индексных дескрипторов и, собственно, под хранение содержимого файлов. Для оптимизации времени доступа блоки поделены на группы. По возможности индексный дескриптор файла и его данные размещаются в пределах одной группы, что снижает время на перемещение головок по диску.
В одном из начальных блоков (со смещением 1024 байта от начала раздела) размещается Суперблок – структура данных размером 1024 байта, описывающая основные настраиваемые параметры ФС. В этих параметрах задаётся размер блока, количество индексных дескрипторов, количество блоков, отведенных под хранение данных и т.п. Размер блока влияет на потери дискового пространства в "хвостах" файлов (больше блок – больше потери) и на максимальную длину файла (больше блок – больше максимальная длина). Количество индексных дескрипторов определяет максимальное число объектов, которые могут быть размещены в данной ФС.
Для повышения надёжности Суперблок дублируется в начале каждой группы. За ним следует массив дескрипторов групп, который также дублируется во всех группах. Далее идут битовые карты свободных индексных дескрипторов и свободных блоков данных группы. Эти битовые карты нужны для быстрого создания файлов и быстрого выделения блоков хранения данных. Далее находятся область хранения индексных дескрипторов и область хранения данных.
Структура группы блоков в ext2fs
| Суперблок | Массив дескрипторов групп | Карта свободных блоков | Карта свободных индексных дескрипторов | Массив индексных дескрипторов | Блоки данных |
|---|---|---|---|---|---|
| Дублируются во всех группах блоков для надёжности | Данные, индивидуальные для каждой группы |
Суперблок
| поле | описание |
|---|---|
| s_inodes_count | Число индексных дескрипторов во всей ФС |
| s_blocks_count | Число блоков, отведённых под ФС |
| s_r_blocks_count | Число зарезервированных блоков данных |
| s_free_blocks_count | Число свободных блоков данных |
| s_free_inodes_count | Число свободных индексных дескрипторов |
| s_first_data_block | Адрес первого блока данных |
| s_log_block_size | Размер блока |
| s_log_frag_size | |
| s_blocks_per_group | Число блоков в группе |
| s_frags_per_group | |
| s_inodes_per_group | Число индексных дескрипторов в группе |
| s_mtime | Время последнего монтирования |
| s_wtime | Время последней записи |
| s_mnt_count | Количество монтирований |
| s_max_mnt_count | Количество монтирований без проверки на ошибки |
| s_magic | Магическое число ex2fs |
| s_state | Флаг "чистого" выключения |
| .... | |
| s_reserved[235] | дополнение до 1024 байтов |
Дескриптор группы
| поле | описание |
|---|---|
| bg_block_bitmap | Адрес битовой карты свободных блоков |
| bg_inode_bitmap | Адрес битовой карты свободных индексных дескрипторов |
| bg_inode_table | Адрес таблицы индексных дескрипторов |
| bg_free_blocks_count | Количество свободных блоков в группе |
| bg_free_inodes_count | Количество свободных индексных дескрипторов в группе |
| bg_used_dirs_count | Количество каталогов группе (для fsck, например) |
| bg_pad | выравнивание до удобного размера |
Поля индексного дескриптора
| поле | описание |
|---|---|
| i_mode | Тип, suid, sgid, sticky, права доступа |
| i_uid | Владелец |
| i_size | Размер |
| i_atime | Access time |
| i_ctime | Creation time |
| i_mtime | Modification time |
| i_dtime | Deletion Time |
| i_gid | Группа |
| i_links_count | Число имён |
| i_blocks | Число занимаемых блоков |
| i_flags | Флаги |
| i_reserved1 | |
| i_block[15] | Указатели на блоки данных |
| i_version | Версия (для NFS) |
| i_file_acl | File ACL |
| i_dir_acl | Directory ACL |
| .... | прочее, дополненное до удобного размера |
Указатели на блоки данных
| номер | описание |
|---|---|
| 1 | адрес блока или 0 |
| ... | ... |
| 12 | адрес блока или 0 |
| 13 | адрес блока косвенной адресации или 0 |
| 14 | адрес блока двойной косвенной адресации или 0 |
| 15 | адрес блока тройной косвенной адресации или 0 |
Блоки адресуются с единицы. Ноль в указателе означает, что блок не выделялся.
Зарезервированные номера индексных дескрипторов
| идентификатор | номер | Описание |
|---|---|---|
| EXT2_BAD_INO | 1 | Сбойные блоки |
| EXT2_ROOT_INO | 2 | Корневой каталог |
| EXT2_ACL_IDX_INO | 3 | ACL (списки доступа) |
| EXT2_ACL_DATA_INO | 4 | ACL (списки доступа) |
| EXT2_BOOT_LOADER_INO | 5 | Загрузчик |
| EXT2_UNDEL_DIR_INO | 6 | Каталог для восстановления стёртых файлов |
| EXT2_FIRST_INO | 11 | Первый нормальный inode. Часто занят каталогом lost+found |
Запись в каталоге
| поле | описание |
|---|---|
| inode | Номер индексного дескриптора |
| rec_len | Длина записи |
| name_len | Длина имени файла |
| name | Имя файла (переменной длины до 255 символов) |
Простая программа для проверки максимальной длины имени
F=""
for I in {1..1024};do
F=${F}Z
if touch $F; then
rm $F
else
echo "Maximum name length="$((I-1))
break
fi
done 2>/dev/null
Ссылки
API файловой системы
Файлы существуют в нескольких качествах:
- объекты файловой системы (ФС)
- источники кода для программ
- источники данных для процессов
Файлы в файловой системе
В файловой системе UNIX хранятся различные объекты: файлы, каталоги, символические ссылки, файлы устройств, FIFO, сокеты. Объекты в ФС адресуются именами и характеризуются правами доступа. Один объект может иметь несколько имен. Права доступа (R)ead, (W)rite, e(X)ecute определены по отдельности для трех категорий пользователей (U)ser, (G)roup, (O)ther. Дополнительно к правам доступа есть флаг смены владельца на время выполнения файла, смены группы на время выполнения файла и признак «липкости», что бы он не означал. Права доступа и флаги для разных типов объектов интерпретируются немного по-разному.
Файлы можно создавать (одновременно давая имя), добавлять новые имена, удалять старые имена, а также менять права доступа к файлу (влияет на сам файл, вне зависимости от того к какому из его имен применялась операция). Администратор может еще и поменять владельца файла.
Файл оставшийся без имени и не используемый для вода/вывода или в качестве источника данных программы – уничтожается. Вызовы ядра Unix, связанные с файловой системой можно условно поделить на несколько групп:
- работа с содержимым файла или каталога
- работа с именами объектов
- работа с символическими ссылками
- работа с FIFO и файлами устройств
- работа с метаданными
Метаданные:
int chown(const char *path, uid_t owner, gid_t group); //смена владельца и группы
int chmod(const char *path, mode_t mode); //смена прав доступа
int stat(const char *file_name, struct stat *buf); //получение всех атрибутов файла
Имена в каталогах:
int mkdir(const char *pathname, mode_t mode); //создание каталога
int rmdir(const char *pathname); //удаление каталога
int link(const char *oldpath, const char *newpath); //создание нового имени
int unlink(const char *pathname); //удаление старого имени
int rename(const char *oldpath, const char *newpath); //атомарная операция удаляющая имя oldpath и создающая newpath
Создание символических ссылок, FIFO и файлов устройств:
int symlink(const char *oldpath, const char *newpath); //создание файла ссылки newpath ссылающегося на oldpath
int mknod(const char *path, mode_t mode, dev_t dev); //создание FIFO или файла устройства (определяется mode)
Открытые файлы = файловые дескрипторы
В качестве источника данных файлы представлены в программе в виде файловых дескрипторов – целых чисел являющимися индексами в таблице открытых файлов. За файловыми дескрипторами могут скрываться файлы, FIFO и файлы устройств в ФС, неименованые каналы - pipe или сокеты. Для операций чтения и записи все эти источники данных равноценны.
По соглашениям UNIX вновь запущенная программа может рассчитывать на три открытых файла с индексами 0,1,2, соответствующие stdin, stdout, stderr. Ответственность за это возлагается на программу вызвавшую exec().
Работа с метаданными файла может происходить и по имени и по файловому дескриптору.
int fchmod(int fd, mode_t mode);
int fchown(int fd, uid_t owner, gid_t group);
int fstat(int fd, struct stat *buf);
Некоторые примеры использования API файловой системы
//Перенаправление стандартного файла ошибок
int newfd;
char *fname="file";
if( (newd = creat(fname, S_IRUSR|S_IWUSR) >=0 ) ){
dup2(newfd,2);
close(newfd);
}else{
perror("Cannot open new stderr file:");
exit(1);
}
// Создание большого "дырявого" файла, который имеет длину 10000000 байт а реально занимает 1 блок на диске
newd = open(fname, O_WRONLY|O_TRUNC);
lseek(fd,10000000,SEEK_SET);
write(fd," ",1);
//узнаем текущую позицию чтения/записи
pos=lseek(newfd,0,SEEK_CUR);
//делаем "невидимым" временный файл
int tmpfd;
char tmpname[]="/tmp/qqqXXXXXX"
mktemp(tmpname);
int tmpfs = open(tmpfname, O_CREAT|O_RDWR, S_IRUSR|S_IWUSR)
unlink(tmpfname);
//теперь файл не имеет имени и будет уничтожен по завершению нашей программы
//читать и писать в него можно без проблем
write(tmpfd,tmpname,1);
lseek(tmpfd,0,SEEK_SET);
read(tmpfd,tmpname,1);
open, read, write, close
Открытие файла
Работа с содержимым файла происходит через целочисленный файловый дескриптор, который представляет из себя номер строки в таблице ссылок на открытые файлы процесса.
При открытии файла в вызове ядра open() проверяются соответствие флагов и прав доступа к файлу.
//почти псевдокод
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int fd;
int flags;
mode_t mode;
// открытие (+создание) файла
fd=open("pathname", flags, mode);
//или
fd=creat("pathname", mode);
// при открытии существующего файла можно опустить параметр mode
fd=open("pathname", flags);
mode - права доступа к файлу, назначаемые в момент его создания. Чтобы нельзя было случайно создать файл со слишком свободным доступом, при создании файла производится побитовое умножение mode на битовую маску umask (mode & ~umask). mode и _umask__ удобно задавать в восьмеричном виде считая, что классические права доступа rwx соответствуют одной восьмеричной цифре. Например, права доступа rwxr-xr-- запишутся в восьмеричном виде как 0754. Типичная маска выглядит так ---w--w- или 022в восьмеричной записи. Такая маска отбирает права на запись у группы и остальных.
Системный вызов umask(mask) устанавливает новую маску и возвращает старую.
#include <sys/types.h>
#include <sys/stat.h>
mode_t old_mask=umask(new_mask);
Для удобства записи прав доступа существуют мнемонические макросы:
S_IRWXU 00700 User Read, Write,eXecute; S_IRUSR 00400 User Read; S_IWUSR 00200 User Write и т.д. S_IXUSR, S_IRWXG, S_IRGRP, S_IWGRP, S_IXGRP, S_IRWXO, S_IROTH, S_IWOTH, S_IXOTH.
flags - флаги уточняющие режим открытия файла. Флаги делятся на несколько групп:
- режим доступа: O_RDONLY, O_WRONLY, O_RDWR, O_WRONLY+O_APPEND(чтение,запись, чтение+запись, запись всегда в конец файла);
- режим создания - O_CREAT, O_CREAT+O_EXCL, O_TRUNC (создавать файл, создавать только если не существует, обрезать существующий до нулевой длины);
- прочие O_NOFOLLOW, O_CLOEXEC, O_NOCTTY (не открывать символические ссылки, закрывать при вызове exec, не рассматривать открытый файл как управляющий терминал CTTY=Control TeleTYpe).
При ошибке открытия файла возвращается -1 и в переменную errno заносится код ошибки. Возможные значения ошибки (не все):
- EACCES - нет прав на сам файл или на поиск в каталоге в котором он находится;
- ENOENT - файл не существует и не указан флаг O_CREAT;
- EEXIST - файл существует и указаны флаги O_CREAT+O_EXCL;
- EFAULT - плохой указатель на имя файла (например NULL);
- EISDIR - попытка открыть каталог;
- ELOOP - символические ссылки создали кольцо в структуре каталогов.
Чтение/запись файла
#include <unistd.h>
// чтение/запись определенного числа байт
int fd
char buf[SIZE];
size_t count=SIZE;
ssize_t res;
res=read (fd, buf, count);
res=write(fd, buf, count);
Чтение и запись возвращают количество прочитанных/записанных байтов или -1. -1 не всегда означает ошибку.
Возможные варианты ответа при записи:
- число от 0 до count - число реально записанных байтов;
- -1 - ошибка. Если errno при ошибке выставлено в EAGAIN, EWOULDBLOCK или EINTR , то операцию можно повторить см. ниже.
Возможные варианты ответа при чтении:
- число от 1 до count - число реально записанных байтов;
- 0 - признак конца файла
- -1 - ошибка. Если errno при ошибке выставлено в EAGAIN, EWOULDBLOCK или EINTR , то операцию можно повторить см. ниже.
Ошибки чтения/записи:
- EAGAIN или EWOULDBLOCK (только для сокетов) - не удалось провести неблокирующее чтение/запись для файла (сокета), открытого в режиме O_NONBLOCK;
- EINTR - операция чтения/записи была прервана доставкой сигнала до того, как удалось прочитать/записать хотя бы один байт;
- EBADF - плохой дескриптор файла (файл закрыт);
- EINVAL - неверный режим доступа к файлу (чтение вместо записи или наоборот);
- EFAULT - неверный указатель на буфер (например NULL).
Чтение/запись сложных объектов за один системный вызов
Чтение/запись из/в фрагментированной памяти
struct iovec {
void *iov_base; /* Starting address */
size_t iov_len; /* Number of bytes to transfer */
} iov[SIZE];
res=readv (fd, iov, SIZE);
res=writev(fd, iov, SIZE);
Чтение/запись в определенную позицию. offset - смещение в байтах относительно начала файла.
res=pread (fd, buf, count, offset);
res=pwrite(fd, buf, count, offset);
res=preadv (fd, iov, int iovcnt, offset);
res=pwritev(fd, iov, int iovcnt, offset);
Закрытие файла
// закрытие файла
int retval=close(fd);
Ошибки при закрытии файла встречаются редко, но встречаются.
- EBADF - попытка закрыть файловый дескриптор, не связанный с открытым файлом;
- EINTR - операция прервана доставкой сигнала. Может встретиться на медленных (например сетевых) ФС;
- EIO - ошибка нижележащей системы ввода/вывода. Например обрыв соединения с файловым сервером.
Установка смещения в файле
Для установки позиции/чтения записи в файле используются два параметра offset - смещение в байтах и whence - место от которого отсчитывается смещение. Возможные значения whence:
- SEEK_SET - от начала файла;
- SEEK_CUR - от текущей позиции;
- SEEK_END - от конца файла.
Пример:
#include <sys/types.h>
#include <unistd.h>
// установка позиции чтения/записи
off_t offset=100;
int whence=SEEK_END;
off_t pos=lseek(fd, offset, whence);
Возвращается установленная позиция или -1 в случае ошибки.
Сочетание offset=0 и whence=SEEK_CUR позволяет узнать текущую позицию чтения/записи.
С помощью lseek возможно перемещение указателя записи за конец файла. Многие ФС в такой ситуации не выделяют блоки хранения под пропущенные байты и создают "дырявые" файлы, занимающие на диске пространство меньше своей длины.
int fd=open("/tmp/sparse-file", O_WRONLY|O_CREAT|O_TRUNC, 0700);
off_t pos=lseek(fd, 1000000000, SEEK_SET);
int res=write(fd,"c",1);
В данном примере создаётся файл длиной примерно 1 ГБ, занимающий на диске один блок данных (например 512 Б).
В 32-х разрядных системах могут быть проблемы с большими файлами. В этом случае надо использовать вызов lseek64 и некоторые дополнительные трюки.
Манипулирование файловыми дескрипторами
Возможно создание ссылки на файловый дескриптор.
#include <unistd.h>
int fd1=dup(oldfd);
int fd2=dup2(oldfd, newfd);
dup() - выбирает в таблице открытых файлов первую свободную строку и записывает ссылку на oldfd в неё, dup2() - закрывает файл, связанный с дескриптором newfd (если он был открыт) и записывает ссылку oldfd в newfd. В случае успеха возвращается файловый дескриптор, в случае ошибки -1.
В связи с тем, что в таблицу открытых файлов вписывается именно ссылка, у файловых дескрипторов oldfd и newfd всегда будет одна и та же позиция головки чтения/записи.
Типичное применение dup2() - это подмена стандартных дескрипторов 0,1,2 (stdin,stdout,stderr). oldfd в этом случае закрывается после создания ссылки. dup2() предпочтительнее чем dup(), т.к. выполняется атомарно, что может быть важно в многопоточной среде.
int newfd=open("file",O_RDONLY);
dup2(newfd,0);
close(newfd);
вариант с dup()
int newfd=open("file",O_RDONLY);
close(0);
dup(newfd);
close(newfd);
Флаги вызова open
Флаги, влияющие на создание файла
| Флаги | файл существует | файл не существует |
|---|---|---|
| Без флагов | Нет ошибки | ENOENT |
| O_CREAT | Нет ошибки | Нет ошибки |
| O_CREAT+O_EXCL | EEXIST | Нет ошибки |
Флаги режима доступа
- O_RDONLY - чтение +O_WRONLY - запись +O_RDWR - чтение и запись +O_WRONLY+O_APPEND - запись всегда в конец файла
Флаги, влияющие на позицию записи
- O_TRUNC - обнулить размер файла и писать с начала
- O_APPEND - всегда записывать в хвост файла
Флаги оптимизации доступа
- O_SYNC - блокировка операции записи до завершения записи на диск
- O_NONBLOCK - открыть файл в неблокирующем режиме (используется с FIFO)
- O_NOATIME - не обновлять время последнего доступа
Специфические флаги
- O_NOCTTY - при открытии терминала не назначать его в качестве управляющего
Наследование файловых дескрипторов
Создание нового процесса в Unix осуществляется системным вызовом fork() который создаёт точную копию текущего процесса. Копируются все структуры данных в ядре и в пространстве пользователя, а значит и таблица открытых файлов. Таким образом дочерний процесс наследует все открытые файлы родительского процесса.
В таблице виртуальных Inode во время вызова fork() счётчики числа открытий файлов увеличиваются на количество ссылающихся на них файловых дескрипторов нового процесса.
Вызов exec("exefile",...) загружает в память существующего процесса код и данные из файла exefile. Все открытые файлы сохраняют своё состояние, кроме тех, которые помечены флагом "O_CLOEXEC". Помеченные файлы закрываются. Исполняемый файл exefile не занимает файловый дескриптор, но так же считается открытым, т.е. exec() увеличивает счётчик числа открытий в таблице виртуальных Inode.
Благодаря цепочке вызовов fork() - exec() и наследованию открытых файлов shell при запуске внешней программы создаёт новый процесс с помощью fork(), а в нём перед вызовом exec() может переназначить файлы стандартного ввод-вывода, которые будут унаследованы запускаемой программой.
Связь со стандартной библиотекой языка Си
Стандартная библиотекой языка Си использует системные вызовы для доступа к файловой системе, однако добавляет к этим вызовам некоторую дополнительную обвязку - буферизацию, преобразование символов конца строки в текстовых файлах и т.п.
Если хочется воспользоваться стандартными библиотечными функциями fprintf, fscanf и т.п. то можно создать структуру FILE на основе существующего дескриптора:
FILE *fp=fdopen(int fd, const char *mode); //mode как в fopen вида “rb” или “w” и т.п.
Совместный доступ к файлам - блокировки
Операция блокировки части файла необходима для организации совместного доступа к файлу из нескольких процессов. Главная задача блокировки - обеспечение атомарности чтения данных, т.е. гарантия того, что при чтении (возможно несколькими вызовами read()) все данные будут принадлежать одной "версии" файла и не будут перезаписаны во время чтения. Соответственно бываю эксклюзивные блокировки со стороны писателя (я пишу в этот файл, другим в это время читать и писать бессмысленно) и разделяемые блокировки со стороны читателей (мы читаем, пожалуйста, не пишите).
В Unix традиционно используются рекомендательные (advisory) блокировки. Такие блокировки требуют от всех процессов, которые хотят получить доступ к файлу, вызова специальных функций для установки и/или проверки блокировок. Вызовы open(), read() и write() про блокировки ничего не знают, и, в результате, процессы, которые явно не вызывают функции работы с блокировками не узнают об их существовании и могут нарушить логику совместной работы с файлом.
Отдельной проблемой является то, что разные способы установки блокировок никак не взаимодействуют друг с другом. Так блокировка установленная вызовом fcntl() не может быть проверена вызовом flock(). Единственным реальным сценарием применения файловых блокировок в Unix является разработка комплекса программ с заранее прописанным алгоритмом синхронизации доступа к файлам через блокировки.
Хорошая статья на английском.
Блокировка через вспомогательный файл
Самые ранние версии Unix не поддерживали блокировок, поэтому в различных программах можно встретить создание вспомогательного файла с расширением .lck или .lock. Перед записью в файл somefile.txt программа в цикле пытается создать файл somefile.txt.lck с флагами O_CREAT|O_EXCL. Если файл уже существует, то вызов open() возвращает ошибку и цикл продолжается. Если файл удалось успешно создать, то цикл завершается и можно открывать на запись основной файл. В служебный файл блокировки часто пишут PID процесса, чтобы было понятно, кто его создал.
int fd=-1;
while(fd==-1){
fd=open("somefile.lck", O_CREAT|O_EXCL|O_WRONLY,0500);
}
//Пишем в файл блокировки свой PID
char pid[6];
itoa(getpid(), pid, 10);
write(fd,pid,strlen(pid));
//этот файловый дескриптор нам больше не нужен
close(fd);
//основная работа
int mainfd=open("somefile", O_WRONLY,0500);
...
close(mainfd);
//Удаляем файл блокировки
unlink("somefile.lck");
Блокировка flock()
Следующим шагом стало появление в BSD системах вызова flock(), который позволял пометить в ядре файл как заблокированный. Этот вызов не стандартизован POSIX, но поддерживается в Linux и во многих версиях Unix. flock() не поддерживается сетевой файловой системой NFS.
#include <sys/file.h>
int flock(int fd, int operation);
Операции:
- LOCK_EX - если файл не заблокирован, то установить эксклюзивную блокировку. Иначе приостановить выполнение процесса, пока все остальные блокировки не будут сняты. По определению только один процесс может держать эксклюзивную блокировку файла.
- LOCK_SH - если файл не заблокирован эксклюзивно, то увеличить счётчик разделяемых блокировок. Иначе приостановить процесс до снятия эксклюзивной блокировки. Разделяемую блокировку на заданный файл может держать более чем один процесс.
- LOCK_UN - удалить блокировку, удерживаемую данным процессом
- LOCK_NB - (not block) флаг, применяемый вместе с LOCK_EX и LOCK_SH для проверки возможности блокировки. Если блокировка невозможна, то вместо приостановки процесса
flock()возвращает -1, а переменнаяerrnoустанавливается в значение EWOULDBLOCK.
Блокировки в POSIX fcntl()
Стандарт POSIX определяет операции с блокировками записей - участков файлов. Блокировки производятся универсальный вызов управления открытыми файлами fcntl() (file control) или через функцию locf(). В Linux locf() это библиотечная обёртка для fcntl().
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, struct flock *lock);
fcntl() - это перегруженный (в смысле C++) вызов ядра с переменным числом параметров. Его поведение определяется значением второго параметра - cmd. За блокировки отвечают команды F_SETLK, F_SETLKW и F_GETLK, которые используются для установки/снятия (SET) и чтения (GET) блокировок файла .
Параметры блокировки задаются/считываются через структуру flock. Блокируемая позиция задаётся параметром, указывающим откуда отсчитывать стартовое смещение, стартовым смещением и размером. Нулевой размер означает блокировку участка файла от стартового смещения и до бесконечности.
struct flock {
...
short l_type; /* Тип блокировки: F_RDLCK,
F_WRLCK, F_UNLCK */
short l_whence; /* Как интерпретировать l_start:
SEEK_SET, SEEK_CUR, SEEK_END */
off_t l_start; /* Начальное смещение для блокировки */
off_t l_len; /* Количество байт для блокировки */
pid_t l_pid; /* PID процесса блокирующего нашу блокировку
(F_GETLK only) */
...
};
Тип блокировки:
- F_RDLCK - разделяемая блокировка. Мы собираемся только читать файл и другие читатели могут к нам присоединиться. В это время никто не должен писать в файл.
- F_WRLCK - эксклюзивная блокировка. Мы собираемся менять файл и никто не должен его читать или в него писать.
- F_UNLCK - снятие блокировки
Команды:
- F_SETLK - установить блокировку (если l_type установлен в значение F_RDLCK или F_WRLCK) или снять блокировку (если l_type установлен в значение F_UNLCK). Если другой процесс заблокировал указанный участок или его часть, то
fcntl()вернёт -1 и установит значение errno в EACCES или EAGAIN. - F_SETLKW - (setlk + wait) тоже, что и предыдущий случай, но с приостановкой текущего процесса до освобождения внешней блокировки
- F_GETLK - проверка наличия блокировки. На вход подаётся параметры интересующего участка и тип блокировки, на выходе - l_type==F_UNLCK если конфликтов не обнаружено или параметры блокировки, которая пересекается с интересующей.
Блокировки в POSIX lockf()
Функция lockf() в Linux реализуется через fcntl() и представляет из себя упрощённый интерфейс для работы с блокировками.
#include <unistd.h>
int lockf(int fd, int cmd, off_t len);
lockf() работает с участком файла начиная с текущей позиции чтения/записи и длиною len байт если len > 0; c позиции раньше текущей на len и до текущей если len < 0; с текущей позиции до конца файла если len = 0.
Команды:
- F_LOCK - Устанавливает исключительную блокировку указанной области файла. Если эта область (или её часть) уже блокирована другим процессом, то вызов приостановит выполнение текущего процесса до тех пор, пока не будет снята предыдущая блокировка. Если эта область перекрывается с ранее заблокированной в этом процессе областью, то они объединяются. Файловые блокировки снимаются сразу после того, как установивший их процесс закрывает файловый дескриптор. Дочерние процессы не наследуют подобные блокировки.
- F_TLOCK - То же самое, что и F_LOCK, но вызов никогда не блокирует выполнение и возвращает ошибку, если файл уже заблокирован.
- F_ULOCK - Снимает блокировку с заданной области файла. Может привести к тому, что блокируемая область будет поделена на две заблокированные области.
- F_TEST - Проверяет наличие блокировки: возвращает 0, если указанная область не заблокирована или заблокирована вызвавшим процессом; возвращает -1, меняет значение errno на EAGAIN (в некоторых системах на EACCES), если блокировка установлена другим процессом.
Блокировки в shell
При программировании в shell можно воспользоваться командой
flock [options] <file|directory> <command> [command args]
Если отбросить подробности, то flock пытается установить блокировку (вызовом flock(), что почти очевидно) на указанный файл или каталог. Если блокировка уже установлена, то flock уходит в "сон". Как только файл становится доступным, flock блокирует его, выполняет указанную команду и завершается, освобождая блокировку.
Обязательные (mandatory) блокировки
В Linux и некоторых Unix возможна установка обязательных блокировок, которые приостановят вызовы read() и write() на заблокированных участках файла (документация по Linux). Для этого файловая система должна быть смонтирована с опцией-o mand, а в правах доступа к файлу должны быть одновременно выставлены флаг запрещения прав на выполнение группой и флаг смены группы процесса при выполнении SGID. В буквенной записи это выглядит так: -rw-r-Sr-- (если бы было право на исполнение группе, то была бы показана маленькая 's') .
- Если на файл установлена разделяемая блокировка F_RDLCK то блокируются все вызовы, которые изменяют файл (
write(),open()с флагом O_TRUNC и т.п.) - Если на файл установлена разделяемая блокировка F_WRLCK то блокируются вызовы чтения
read()и вызовы, изменяющие содержимое файла (write()и т.д.) - Обязательная блокировка несовместима с отображением файла в память.
Файловые дескрипторы и их дублирование
файловый дескриптор ФД (созданный через вызов open или унаследованный от родительского процесса), является целочисленным индексом в таблице ссылок на структуры открытых файлов процесса. Сама структура, связанная с открытым файлом, содержит дальнейшую ссылку на виртуальный Inode файла в памяти ядра, а так же флаги доступа к файлу (чтение, запись), текущую позицию чтения/записи в файле и некоторые дополнительные данные. Информация о блокировках используется совместно несколькими процессами, а потому вынесена в виртуальный Inode.
По соглашениям, принятым в ОС Unix, в момент запуска программы должны быть открыты ФД 0, 1 и 2, которые интерпретируются как STDIN, STDOUT и STDERR соответственно. Другие ФД так же могут быть открыты, но это никак не регламентируется. При выделении нового ФД при вызове open, pipe, dup и т.п., выбирается наименьший свободный ФД.
Процесс, имея ФД, может создавать на его основе новые ФД, которые будут ссылками на ту же структуру данных в ядре, что и оригинальный ФД и соответственно те же флаги и позицию чтения/записи. Закрытие ФД уменьшает количество ссылок на открытый файл. Фактическое закрытие файла произойдёт тогда, когда на него не будет ссылаться ни один ФД.
Для создания ссылок используются вызовы dup и dup2. dup возвращает первый свободный номер ФД, а dup2 позволяет явно указать номер нового ФД. Если желаемый номер ФД окажется занятым, то он сначала будет закрыт.
int newfd=dup(oldfd)
int newfd=dup2(oldfd,1)
Самое частое использование dup2 это перенаправление стандартного ввода-вывода. Например, shell, выполняя команду:
grep str infile > outfile
может выполнить следующую последовательность действий
Вариант 1:
if (!fork() ){
// Дочерний процесс для запуска grep
// Освобождаем ФД==1 (STDOUT)
close(1);
// open должен вернуть наименьший свободный ФД т.е. 1
open("outfile", O_CREAT|OTRUNC|O_WRONLY, 0544);
// Запускаем программу grep, наследующую STDOUT -> "outfile"
execlp("grep", "str", "infile",NULL);
}
Вариант 1 в многопоточной среде может привести к гонкам за захват ФД==1, поэтому рекомендуется Варинт2:
if (!fork() ){
// Дочерний процесс для запуска grep
// open возвращает какой-то ФД
int fd= open("outfile", O_CREAT|OTRUNC|O_WRONLY, 0544);
// Связываем 1 (STDOUT) с "outfile" через fd
dup2(fd,1);
// Освобождаем fd
close(fd);
// Запускаем программу grep, наследующую STDOUT -> "outfile"
execlp("grep", "str", "infile",NULL);
}
Перенаправление через pipe выполняется аналогично.
Доступ к каталогам
Создание каталога
Для создания каталога в вызов mkdir() передаётся путь к создаваемому каталогу. Вышележащий каталог должен существовать (??) и пользователь должен иметь право на запись в него.
#include <sys/stat.h>
int mkdir(const char *path, mode_t mode);
Создание имени файла
При создании файла вызовом open() с флагом O_CREAT в указанном в пути к файлу каталоге создаётся запись с именем файла. Новое имя для файла можно создать вызовом link().
#include <unistd.h>
int link("oldpath", "newpath");
Поскольку жёсткие ссылки возможны только в рамках одной ФС, то и имена "oldpath" и "newpath" должны находиться внутри одной ФС.
Удаление имени файла
В Unix нет операции удаление файла. Есть лишь операция удаление из каталога жёсткой ссылки (имени) на объект. Каждый раз после удаления имени уменьшается счётчик имён в Inode файла. Когда счётчик имён становится равным нулю, файл становится недоступным по имени. Однако, если в этот момент файл был открыт одним или несколькими процессами, то он не удаляется из ФС. Только тогда, когда у файла ноль имён и он не открыт ни в одном процессе, его Inode и его блоки данных помечаются как свободные, т.е. происходит уничтожение файла.
Данное поведение позволяет выполнять трюк с невидимыми временными файлами. Файл создаётся, открывается, и тут же удаляется его имя. В результате невидимый файл будет существовать до завершения процесса в котором он был создан. В такой ситуации аварийное завершение процесса не оставляет нигде в ФС ненужных временных файлов.
Вызов unlink() неприменим к каталогам. unlink() символической ссылки удаляет имя символической ссылки, никак не влияя на объект, на который указывает символическая ссылка.
#include <unistd.h>
int unlink("file");
Переименование файла
Вызов rename("old", "new") эквивалентен паре вызовов link("old", "new"); unlink("old");. В отличие от этой пары rename() можно применять к каталогам, а так же он не удалит объект при переименовании его в самого себя - rename("x", "x").
Чтение каталога
Каталог в Linux можно открыть как файл с помощью open с флагом O_DIRECTORY:
struct old_linux_dirent {
long d_ino; /* inode number */
off_t d_off; /* offset to this dirent */
unsigned short d_reclen; /* length of this d_name */
char d_name [NAME_MAX+1]; /* file name (null-terminated) */
} olddirp[SIZE];
// в Linux каталог можно открыть с помощью open
int fd=open("dirname", O_DIRECTORY);
// и прочитать его внутреннюю структуру
retval=readdir(fd, olddirp, SIZE);
но так делать не надо.
Для работы с каталогами надо использовать библиотечные функции opendir(3), readdir(3) и т.д.
#include <dirent.h>
struct dirent {
ino_t d_ino; /* номер inode */
off_t d_off; /* заглушка */
unsigned short d_reclen; /* заглушка */
unsigned char d_type; /* тип файла; поле не стандартизовано */
char d_name[256]; /* имя файла */
};
// открыть каталог
DIR *dirp;
dirp=opendir("dirname");
// или
dirp=fopendir(fd);
// прочитать запись за записью
struct dirent *rec;
do{
rec=readdir(dirp);
}while(rec)
// начать сначала
rewinddir(dirp);
// закрыть каталог
closedir(dirp);
Удаление каталога
Удалять можно только пустые каталоги.
#include <unistd.h>
int rmdir("pathname");
lseek
С каждым открытым файлом в UNIX связано понятие позиции чтения-записи. Это понятие не применимо к сокетам и каналам, но обычном файле у нас есть внутренняя нумерация байт, начинающаяся с нуля, и некая условная головка чтения-записи. Позиция головки одна для чтения и записи. При открытии файла на чтение или на запись головка выставляется на начало файла. При каждой операции чтения-записи головка устанавливается на позиции за последним считанным-записанным байтом. Особый случай - это открытие файла на дозапись с флагом O_APPEND. В этом случае каждая операция записи предварительно перемещает головку в конец файла. Конец файла - это позиция равная числу байт в файле. Если мы начнем запись в конец файла, то будем писать после последнего существующего байта. Если начнем читать, то прочитаем 0 байт, что является признаком конца файла.
Иногда появляется желание переместиться по файлу вперед или назад и начать читать или писать с некой определенной позиции. Для того чтобы управлять положением головки используется вызов lseek, который изменяет положение головки чтения-записи. lseek получает файловый дескриптор и два значения: целочисленное значение смещения и макрос whence, который описывает, откуда это смещение отсчитывается. В man странице написано, что использование слова whence нарушает правила английского языка, но сохраняется по историческим причинам.
off_t pos=lseek(int fd, off_t offset, int whence);
Параметр whence может принимать три значения: + SEEK_CUR - смещение относительно текущей позиции. Если смещение положительное, то головка смещается к концу файла, если отрицательное - то ближе к началу файла. + SEEK_END - смещение вычисляется относительно текущего размера файла. + SEEK_SET - смещение от начала файла. Отрицательное смещение не имеет смысла.
В качестве результата lseek возвращает текущую позицию относительно начала файла.
Смещение 0 от текущей позиции не меняет положение головки, но возвращает текущую позицию. Нулевое смещение относительно конца файлы вернет его текущий размер и переместит головку на байт, следующий за последним в файле. Слишком большое отрицательное смещение переводит головку в нулевую позицию.
Если один файловый дескриптор создан из другого с помощью dup() или dup2(), то положение их головок всегда совпадает. Если применить lseek() к таким файловым дескрипторам из разных потоков, то это может привести к состоянию гонок и неожиданному поведению.
У вызова lseek есть проблема, связанная с разрядностью чисел.
В 32 разрядных системах максимальное значение целочисленного смещения четыре гигабайта, в то время как все современные файловые системы поддерживают файлы большего размера. Проблема в том, что мы просто не можем записать значение смещение больше 4ГБ. Тем не менее выполняя последовательные вызовы lseek мы можем перемещаться неограниченно далеко.
В таком случае lseek возвращает -1 и выставляет переменную errno в значение EOVERFLOW.
Чтобы работать со сверхбольшими файлами в 32 разрядной системе компилятор gcc и библиотека gnulibc предоставляют специальную функцию lseek64, у которой в качестве параметра offset передается структура, состоящая из двух целочисленных значений. Для ее использования необходимо открывать файл с флагом O_LARGEFILE и указывать при компиляции особые макросы -D_LARGEFILE64_SOURCE -D_FILE_OFFSET_BITS.
Виртуальная файловая система VFS
Виртуальная файловая система VFS
Для организации доступа к разнообразным файловым системам (ФС) в Unix используется промежуточный слой абстракции - виртуальная файловая система (VFS).
С точки зрения программиста VFS организована как интерфейс или абстрактный класс в объектно ориентированном языке программирования типа C++.
VFS объявляет API доступа к файловой системе, а реализацию этого API отдаёт на откуп драйверам конкретных ФС, которые можно рассматривать, как производные классы, наследующие интерфейс VFS.
Виртуальные методы VFS
Каждый драйвер ФС должен реализовать вызовы для работы с файлами, inode и с ФС в целом, описанные в заголовочном файле ядра linux/fs.h. При монтировании ФС соответствующие структуры заполняются указателями на соответствующие реализации в драйвере.
Если какая-нибудь функция отсутствует в драйвере, то указатель ссылается на функцию заглушку, которая возвращает ошибку "не реализовано" - ENOSYS.
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
...
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *);
int (*create) (struct inode *,struct dentry *,int);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
...
struct super_operations {
int (* ) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
...
Для файловой системы ext2fs объявление соответствующих функций выглядит так:
extern struct dentry *ext2_lookup (struct inode *, struct dentry *);
extern int ext2_create (struct inode *,struct dentry *,int);
extern int ext2_mkdir (struct inode *,struct dentry *,int);
extern int ext2_rmdir (struct inode *,struct dentry *);
extern int ext2_unlink (struct inode *,struct dentry *);
...
Вызовы remount_fs() и umount_begin() можно использовать как конструктор
и деструктор класса, которые вызываются в момент монтирования файловой системы
и в момент размонтирования.
Виртуальный inode
Кроме виртуальных функций VFS описывает обобщённые структуры superblock, dentry (directory entry запись в каталоге),inode (в некоторых ОС называется vnode). Эти структуры содержит все основные структуры данных суперблока ФС, каталогов и inode из классической ФС Unix. Кроме того структура file содержит информацию, необходимую для работы с открытыми файлами Поскольку VFS является интерфейсом, то перечисленные структуры не содержат технических подробностей, таких как информации о размещении блоков данных файла или IP адреса сервера сетевой ФС. Для хранения деталей реализации, драйверу ФС в каждой из структур предоставляется дополнительное поле для хранения указателя на специфические для ФС структуры данных. В inode в Linux это поле выглядит так:
union {
struct pipe_inode_info pipe_i;
struct minix_inode_info minix_i;
struct ext2_inode_info ext2_i;
...
void *generic_ip;
} u;
На основе перечисленных
Драйвер ФС должен уметь конвертировать атрибуты файла, фактически хранящиеся в ФС, в поля inode. Например, драйвер NTFS должен уметь преобразовывать SID пользователя Windows в UID пользователя Unix и наоборот.
Если ФС не позволяет хранить необходимые атрибуты inode, то при монтировании драйверу можно передать некоторые дополнительные параметры, содержащие фиксированные значения для этих атрибутов. Драйвер FAT позволяет задать:
- uid, gid - владелец и группа для всех файлов
- dmask, fmask - маски прав доступа для файлов и каталогов, которые вычитается из rwxrwxrwx.
- codepage, iocharset - кодовые таблицы для преобразования имён файлов на национальных алфавитов в UTF-8 или иную, используемую в Unix кодировку.
- tz=UTC - указание, что метки времени в ФС хранятся в UTC. DOS и Windows хранят метки времени в локальном времени часового пояса.
Procfs /proc
Благодаря VFS в Unix возможно представление в виде ФС любых иерархических структур данных. Самый известный пример, это файловая система Procfs , которая отображает в виде дерева каталогов внутренние структуры ядра. Чаще всего, она смонтирована в каталог /proc, но может быть смонтирована и в другой каталог или не смонтирована вовсе.
В каталоге /proc в Linux присутствуют, по сути, два дерева ФС. В основном
дереве, каждый каталог имеет числовое имя и соответствует процессу,
с соответствующим PID. Файлы в этих каталогах соответствуют структурам данных,
связанных с процессом. Каталог /proc/self в Linux является символической
ссылкой, указывающей на каталог процесса, который к ней обратился.
Например, cat /proc/self/cmdline покажет аргументы запуска cat т.е.
cat /proc/self/cmdline, а ls -l /proc/self/exe покажет ссылку на
исполняемый файл ls - /proc/self/exe -> /usr/bin/ls.
В дереве /proc/sys отображаются внутренние переменные ядра. Операции чтения/записи в каталоге /proc/sys позволяют настраивать такие параметры ядра как маршрутизация - /proc/sys/net/ipv4/ip_forward или максимальный объём разделяемой между процессами памяти /proc/sys/kernel/shmmax. В исторических Unix, таких как Solaris 5 такие настройки делались через отладчик, который подключался к ядру как к программе и менял значения переменных.
В последних версиях ядра Linux прослеживается тенденция вынесения доступа к новым переменным в отдельную ФС Sysfs, которая монтируется в каталог /sys.
ФС вне ядра - fuse
В Linux (а в последнее время и в Windows) есть возможность зарегистрировать в VFS свой драйвер ФС без написания кода в ядре. Адаптер fuse транслирует вызовы из ядра в обычный пользовательский процесс. Благодаря этому механизму возможно написание драйверов, написанных на любом языке программирования: C++, python, Java и т.д. Главное, написать соответствующий набор функций и через API fuse зарегистрировать их в ядре.
Известные примеры: sshfs - монтирование дисков через sftp, NTFS-3G - драйвер NTFS через fuse, различные ФС на основе баз данных.
Разбор имён файлов в VFS
Файловые системы (ФС) в Unix доступны через промежуточный слой абстракции - виртуальную файловую систему (VFS). VFS организована в виде дерева, в котором узлы ветвления это всегда каталоги, а листья - любые допустимые в VFS объекты (файлы, каталоги, символические ссылки, сокеты, и т.д.). Чтобы подключить в VFS новый носитель данных, выполняется операция монтирования, которая сопоставляет одному из каталогов, уже присутствующему в дереве, ссылку на корневой каталог в ФС на носителе. Доступ к ранее существовавшему содержимому каталога до отмены операции монтирования прекращается. Говорят, что в результате монтирования носитель становится смонтированным в каталог. Корневой каталог всей VFS также должен быть смонтирован на корневой каталог какой-либо конкретной ФС.
Имена объектов в VFS - это байтовые строки с завершающим нулевым байтом. Интерпретацией кодировки символов VFS не занимается. При записи путей символ "слэш" "/" используется как разделитель каталогов и потому не может быть использован в именах объектов VFS. Кроме слэша внутри имён объектов не может присутствовать нулевой байт '\0'. Длина имени не должна превышать NAME_MAX (определена в файле linux/limits.h как 255 байт). В остальном в VFS ограничений на имена нет, но такие ограничения могут быть обусловлены реализацией конкретной файловой системы.
В каждом каталоге существует два зарезервированных имени "." и "..", обозначающие текущий и вышележащий каталоги соответственно. Если ФС на носителе не поддерживает такие имена, то они должны быть сэмулированы драйвером. При выполнении монтирования значение "." берётся из корневого каталога на носителе, а ".." из того каталога, в который было произведено монтирование. В корневом каталоге (см. ниже) ".." ссылается на сам каталог как и ".".
Разбор пути
С каждым процессом в Unix связано два каталога:
- текущий рабочий (current work directory, cwd)
- корневой (root directory, rtd)
Эти каталоги используются при разборе путей в VFS теми системными вызовами,
которые получают пути в качестве аргументов
(open("path", ...), unlink("path") и т.п.). Если путь начинается с символа
"слэш" "/" то он называется абсолютным и отсчитывается от корневого каталога
процесса, а если начинается с любого другого символа, то называется
относительным и отсчитывается от текущего рабочего каталога.
Разбор пути идет по следующим правилам (man path_resolution):
- Если длина пути превышает PATH_MAX (4096 байт вместе с завершающим нулевым байтом - определено в linux/limits.h)то возвращается ошибка ENAMETOOLONG. Такая же ошибка может появиться в дальнейшем при рекурсивном разборе символических ссылок.
- В зависимости от первого символа разбор пути начинается с корневого или с текущего рабочего каталога;
- В текущем разбираемом каталоге ищется имя следующего компонента пути. Если на чтение каталога не хватает прав, то возвращается ошибка EACCES; если имя не найдено, то возвращается ошибка ENOENT
- Если найденное имя является символической ссылкой, то её содержимое разбирается в рекурсивном вызове. Внутри рекурсии увеличивается счётчик вложенности. Если счётчик вложенности при разборе символических ссылок превышает максимальное допустимое число, то разбор останавливается и возвращается ошибка ELOOP. Если разбор символической ссылки вернул каталог, то он делается текущим для разбора. Разбор продолжается с п.2.
- Если найденное имя является каталогом, то проверяется, не используется ли этот каталог как точка монтирования. Если нет, то он устанавливается текущим для разбора. Если каталог используется для монтирования, то текущим для разбора устанавливается корневой каталог смонтированной ФС. Разбор продолжается с п.2. Если найденное имя это каталог ".." то, по правилам формирования этого имени, в корневом каталоге он сошлётся снова на корневой каталог, а в каталоге, используемым для монтирования, прозрачно позволит перейти из одной ФС в другую
- Если найденное имя последнее в пути, то соответствующий объект обрабатывается системным вызовом по своим правилам. Если найденное имя не последнее в пути и, при этом, указывает не на каталог и не на символическую ссылку, то выдаётся ошибка ENOTDIR
Текущий и корневой каталоги процесса
Смена текущего каталога выполняется вызовом chdir(const char *dir)
или fchdir(int fd). Второй способ требует предварительно получить файловый
дескриптор, ссылающийся на каталог.
Смена корневого каталога процесса выполняется вызовом
chroot(const char *dir). В новом корневом каталоге имя ".."
указывает на него самого, что не позволяет с помощью абсолютных путей
подняться по дереву выше корневого каталога процесса. После выполнения этого
вызова вся файловая система "выше" указанного корневого каталога становится
невидимой для последующих системных вызовов, но открытые файлы за пределами
видимости остаются доступными. Более того, текущий каталог может оказаться
за пределами корневого, так что при практическом применении, например
для ограничения доступа процесса к ФС, надо сочетать
chroot() и chdir().
Chroot в shell
Чтобы запустить программу с переопределённым корневым каталогом используется программа
chroot NEWROOT [COMMAND [ARG]...]
Если команда COMMAND не указана, то выполняется shell, указанный в файле passwd для текущего пользователя.
Внутри chroot выполняются следующая последовательность вызовов:
chroot("NEWROOT");
chdir("/");
execve("COMMAND", ...);
Последний вызов означает, что исполняемый файл COMMAND и динамические библиотеки необходимые для его выполнения должны находиться внутри нового корневого каталога.
Если мы хотим запереть пользователя внутри chroot нам необходимо скопировать
вовнутрь /bin/bash, /lib/libc.so, /etc/passwd, /dev/tty и ещё ряд важных
файлов, полный состав которых зависит от версии ОС и набора решаемых в "тюрьме"
задач.
Структуры VFS, описывающие открытый файл в Linux
Сокращенный вариант структур данных в ядре Linux 2.2.26. Структуры описаны в include/linux/{sched.h,fs.h,dcache.h}.
ФД -файловый дескриптор, ФС - файловая система
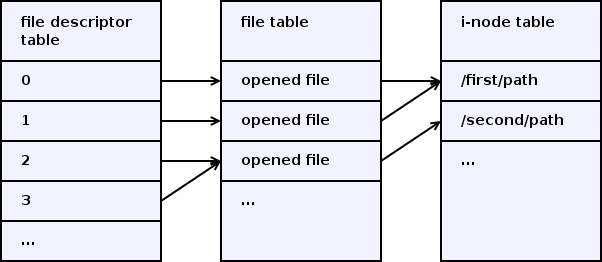
Данные о процессе в ядре
struct task_struct {
...
struct files_struct *files; //информация об открытых файлах процесса
...
}
Информация об открытых файлах процесса
struct files_struct {
atomic_t count; //количество открытых файлов
int max_fds; //максимальное доступное количество ФД
int max_fdset; //максимальный номер использованного ФД
int next_fd; //минимальный свободный номер ФД
fd_set *close_on_exec; //битовая карта ФД, которые необходимо закрыть при вызове exec()
fd_set *open_fds; //битовая карта открытых ФД
struct file * fd_array[NR_OPEN_DEFAULT]; //массив указателей на открытые файлы
...
};
Свойства открытого в процессе файла
struct file {
struct dentry *f_dentry; //ссылка на запись в каталоге (имя и inode файла)
struct file_operations *f_op; //указатели на функции драйвера ФС для работы с файлом
atomic_long_t f_count; //количество открытых файловых дескрипторов процесса, указывающих на файл
unsigned int f_flags; //флаги, указанные при открытии
loff_t f_pos; //позиция головки ввода/вывода
fmode_t f_mode; //права доступа в момент открытия
struct fown_struct f_owner; //uid,gid файла в момент открытия
...
void *private_data; //место для хранения специфичных для драйвера данных
};
Запись в каталоге
struct dentry {
struct inode *d_inode;
struct qstr d_name;
...
}
Inode
struct inode {
...
kdev_t i_dev; //номер устройства, на котором расположен inode
unsigned long i_ino; //номер inode
umode_t i_mode;//права доступа
nlink_t i_nlink; //число имён
uid_t i_uid;
gid_t i_gid;
...
struct super_block *i_sb; // ссылка на суперблок ФС
...
unsigned int i_count; //общее число ФД, ссылающихся на этот файл
struct file_lock * i_flock; //блокировки файла
...
}
Указатели на операции с файлом в драйвере ФС
struct file_operations {
int (*open) (struct inode *, struct file *);
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
...
}
| Прикрепленный файл | Размер |
|---|---|
| 10.19 КБ |
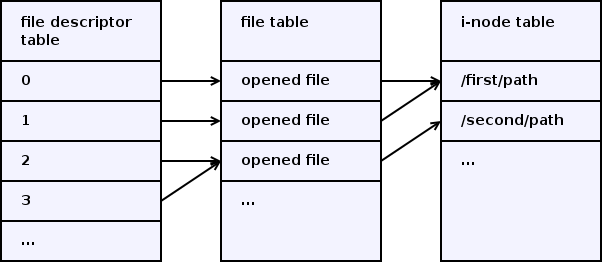{kind=link}
Каналы (pipe,fifo)
Каналы - неименованные (pipe) и именованные (fifo) - это средство передачи данных между процессами.
Можно представить себе канал как небольшой кольцевой буфер в ядре операционной системы. С точки зрения процессов, канал выглядит как пара открытых файловых дескрипторов – один на чтение и один на запись (можно больше, но неудобно). Мы можем писать в канал до тех пор пока есть место в буфере, если место в буфере кончится – процесс будет заблокирован на записи. Можем читать из канала пока есть данные в буфере, если данных нет – процесс будет заблокирован на чтении. Если закрыть дескриптор отвечающий за запись, то попытка чтения покажет конец файла. Если закрыть дескриптор отвечающий за чтение, то попытка записи приведет к доставке сигнала SIGPIPE и ошибке EPIPE.
При использовании канала в программировании на языке shell
ls | grep abc
блокировки чтения/записи обеспечивают синхронизацию скорости выполнения двух программ и их одновременное завершение.
Понятия позиции чтения/записи для каналов не существует, поэтому запись всегда производится в хвост буфера, а чтение с головы.
Для архитектуры i386 размер буфера, связанного с каналом устанавливают кратным размеру страницы (4096 байт). В Linux в версиях до 2.6.11 использовалась одна страница (4 КБ), после - 16 страниц (65 КБ), с возможностью изменения через fcntl. POSIX определяет значение PIPE_BUF, задающего максимальный размер атомарной записи. В Linux PIPE_BUF равен 4096 байт.
Неименованные каналы
Неименованный канал создается вызовом pipe, который заносит в массив int [2] два дескриптора открытых файлов. fd[0] – открыт на чтение, fd[1] – на запись (вспомните STDIN == 0, STDOUT == 1). Канал уничтожается, когда будут закрыты все файловые дескрипторы ссылающиеся на него.
В рамках одного процесса pipe смысла не имеет, передать информацию о нем в произвольный процесс нельзя (имени нет, а номера файловых дескрипторов в каждом процессе свои). Единственный способ использовать pipe – унаследовать дескрипторы при вызове fork (и последующем exec). После вызова fork канал окажется открытым на чтение и запись в родительском и дочернем процессе. Т.е. теперь на него будут ссылаться 4 дескриптора. Теперь надо определиться с направлением передачи данных – если надо передавать данные от родителя к потомку, то родитель закрывает дескриптор на чтение, а потомок - дескриптор на запись.
int fd[2];
char c;
pipe(fd);
if( fork() ) { //родитель
close(fd[0]);
c=0;
while(write(fd[1],&c,1) >0) {
c++;
}
} else { //дочерний процесс
dup2(fd[0],0); //подменили STDIN
close(fd[0]);
close(fd[1]);
execl("prog","prog",NULL); //запустили новую программу для которой STDIN = pipe
}
Оставлять оба дескриптора незакрытыми плохо по двум причинам:
Родитель после записи не может узнать считал ли дочерний процесс данные, а если считал то сколько. Соответственно, если родитель попробует читать из pipe, то, вполне вероятно, он считает часть собственных данных, которые станут недоступными для потомка.
Если один из процессов завершился или закрыл свои дескрипторы, то второй этого не заметит, так как pipe на его стороне по-прежнему открыт на чтение и на запись.
Если надо организовать двунаправленную передачу данных, то можно создать два pipe.
Именованные каналы
Именованный канал FIFO доступен как объект в файловой системе. При этом, до открытия объекта FIFO на чтение, собственно коммуникационного объекта не создаётся. После открытия открытия объекта FIFO в одном процессе на чтение, а в другом на запись, возникает ситуация полностью эквивалентная использованию неименованного канала.
Объект FIFO в файловой системе создаётся вызовом функции int mkfifo(const char *pathname, mode_t mode);,
Основное отличие между pipe и FIFO - то, что pipe могут совместно использовать только процессы находящиеся в отношении родительский-дочерний, а FIFO может использовать любая пара процессов.
Правила обмена через канал
При обмене данными через канал существуют два особых случая:
- Попытка чтения при отсутствии писателей
- Попытка записи при отсутствии читателей
Первый случай интерпретируется как конец файла и вызов read вернёт 0. Второй случай не имеет аналогов при работе с обычными файлами, а потому вызывает доставку сигнала SIGPIPE. Программы-фильтры, которые работают с STDOUT по сигналу SIGPIPE обычно завершают работу. Если программа расcчитана на работу с каналами, то для корректной обработки этой ситуации она должна явно изменить стандартный обработчик SIGPIPE, установив его в игнорирование сигнала или переназначив на свою функцию.
Для защиты от этих особых случаев при открытии именованного канала FIFO вызов open() на чтение или на запись блокируется, пока кто-нибудь не откроет канал с другой стороны. Если открывать FIFO с опцией O_NONBLOCK, то одиночное открытие на чтение пройдёт успешно, а попытка открыть на запись FIFO без читателей вернёт ошибку ENXIO (устройство не существует). Открытие FIFO одновременно на чтение и на запись в POSIX не определено. В Linux такой вариант сработает и в блокирующем и в неблокирующем режимах.
Правила обмена через канал
Чтение:
- При чтении числа байт, меньшего чем находится в канале, возвращается требуемое число байтов, остаток сохраняется для последующих чтений.
- При чтении числа байт, большего чем находится в канале, возвращается доступное число байт.
- При чтении из пустого канала, открытого каким либо процессом на на запись при сброшенном флаге O_NONBLOCK произойдёт блокировка процесса, а при установленном флаге O_NONBLOCK будет возвращено -1 и установлено значение
errnoравное EAGAIN. - Если канал пуст и ни один процесс не открыл его на запись, то при чтении из канала будет получено 0 байтов - т.е конец файла.
Запись:
- Если процесс пытается записать данные в канал, не открытый ни одним процессом на чтение, то процессу отправляется сигнал SIGPIPE. Если не установлена обработка сигнала, то процесс завершается, в противном случае вызов write() возвращает -1 с установкой ошибки EPIPE.
- Запись числа байт меньше чем PIPE_BUF выполняется атомарно. При записи из нескольких процессов данные не перемешиваются.
- При записи числа байт больше чем PIPE_BUF атомарность операции не гарантируется.
- Если флаг O_NONBLOCK не установлен, то запись может быть заблокирована, но в конце концов будет возвращено значение, указывающее, что все байты записаны.
- Если флаг O_NONBLOCK установлен и записывается меньше чем PIPE_BUF, то возможны два варианта: если есть достаточно свободного места в буфере, то производится атомарная запись, если нет, то возвращается -1, а errno выставляется в EAGAIN.
- Если флаг O_NONBLOCK установлен и записывается больше чем PIPE_BUF то возможны два варианта: если в буфере есть хотя бы один свободный байт, то производится запись доступного числа байт, если нет, то возвращается -1, а errno выставляется в EAGAIN.
Процессы
Процессы – действующее начало. В общем случае с процессом связаны код и данные в виртуальной оперативной памяти, отображение виртуальной памяти на физическую, состояние процессора (регистры, текущая исполняемая инструкция и т.п.). Кроме того в Unix с процессом связана информация о приоритете (в том числе понижающий коэффициент nice), информация об открытых файлах и обработчиках сигналов. Программа, выполняемая внутри процесса, может меняться в течение его существования.
Создание процессов fork()
Новые процессы создаются вызовом int pid=fork(), который создаёт точную копию вызвавшего его процесса. Пара процессов называются "родительский" и "дочерний" и отличаются друг от друга тремя значениями:
- уникальный идентификатор процесса PID
- идентификатор родительского процесса PPID
- значение, возвращаемое вызовом
fork(). В родительском это PID дочернего процесса или ошибка (-1), в дочернемfork()всегда возвращает 0.
После создания, дочерний процесс может загрузить в свою память новую программу (код и данные) из исполняемого файла вызовом execve(const char *filename, char *const argv [], char *const envp[]);
Дочерний процесс связан с родительским значением PPID. В случае завершения родительского процесса PPID меняется на особое значение 1 - PID процесса init.
Процесс init
В момент загрузки ядра создаётся особый процесс с PID=1, который должен существовать до перезагрузки ОС. Все остальные процессы в системе являются его дочерними процессами (или дочерними от дочерних и т.д.). Обычно, в первом процессе исполняется программа init поэтому в дальнейшем я буду называть его "процесс init".
В Linux процесс init защищен от вмешательства других процессов. К нему нельзя подключиться отладчиком, к его памяти нельзя получить доступ через интерфейс procfs, ему не доставляются сигналы, приводящие к завершению процесса. kill -KILL 1 - не сработает. Если же процесс init всё таки завершится, то ядро также завершает работу с соответствующим сообщением.
В современных дистрибутивах классическая программа init заменена на systemd, но сущности процесса с PID=1 это не меняет.
При загрузке Linux ядро сначала монтирует корневую файловую систему на образ диска в оперативной памяти - initrd, затем создаётся процесс с PID=1 и загружает в него программу из файла /init. В initrd из дистрибутива CentOS начальный /init - это скрипт для /bin/bash. Скрипт загружает необходимые драйверы, после чего делает две вещи, необходимые для полноценного запуска Linux:
- Перемонтирует корневую файловую систему на основной носитель
- Загружает командой exec в свою память основную программу init
Для того, чтобы выполнить эти два пункта через загрузчик в начального init два параметра:
- основной носитель корневой ФС. Например: root=/dev/sda1
- имя файла с программой init. Например: init=/bin/bash
Если второй параметр опущен то ищется имя зашитое в начальный init по умолчанию.
Если вы загрузите вместо init /bin/bash, как в моём примере, то сможете завершить первый и единственный процесс командой exit и пронаблюдать сообщение:
Kernel panic - not syncing: Attempted to kill init!
Этот пример так же показывает, как получить права администратора при физическом доступе к компьютеру.
PID
Каждый процесс имеет уникальный на данный момент времени идентификатор PID. Поменять PID процесса невозможно.
Значения PID 0 и 1 зарезервированы. Процесс с PID==0 не используется, PID==1 - принадлежит программе init.
Максимальное значение PID в Linux равняется PID_MAX-1. Текущее значение PID_MAX можно посмотреть командой:
cat /proc/sys/kernel/pid_max
По умолчанию это 2^16 (32768) однако в 64-разрядных Linux его можно увеличить до 2^22 (4194304):
echo 4194303 > /proc/sys/kernel/pid_max
*PID* назначаются последовательно. При создании нового процесса вызовом fork ищется *PID*, больший по значению, чем тот, который был возвращён предыдущим вызовом fork. Если при поиске достигнуто значение pid_max, то поиск продолжается с PID=2. Такое поведение выбрано потому, что некоторые программы могут проверять завершение процесса по существованию его PID. В этой ситуации желательно, чтобы PID не использовался некоторое время после завершения процесса.
UID и GID
С процессом связано понятие "владельца" и "группы", определяющие права доступа процесса к другим процессам и файлам в файловой системе. "Владелец" и "группа", это числовые идентификатор UID и GID, являющийся атрибутами процесса. В отличие от файла, процесс может принадлежать нескольким группам одновременно. Пользователь в диалоговом сеансе имеет право на доступ к своим файлам поскольку диалоговая программа (shell), которую он использует, выполняется в процессе с тем же UIDом, что и UID, указанный в атрибутах файлов.
Процесс может поменять своего владельца и группу в двух случаях:
- текущий UID равен 0 (соответствует пользователю root) и процесс обратился к системному вызову
setuid(newuid). В этом случае процесс полностью меняет владельца. - процесс обратился к вызову
exec(file)загрузив в свою память программу из файла в атрибутах которого выставлен флаг suid или sgid. В этом случае владелец процесса сохраняется, но права доступа будут вычисляться на основе UID и GID файла.
| Прикрепленный файл | Размер |
|---|---|
| 25.8 КБ |
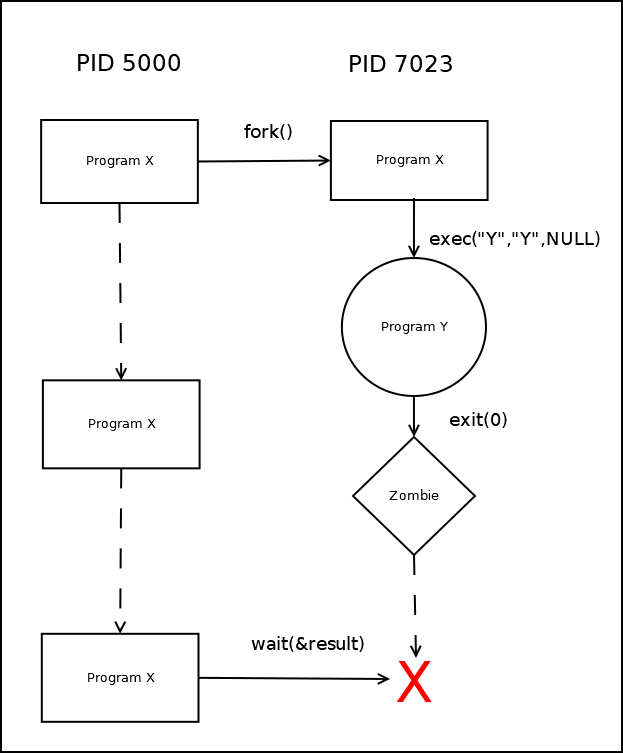{kind=link}
Жизненный цикл процесса
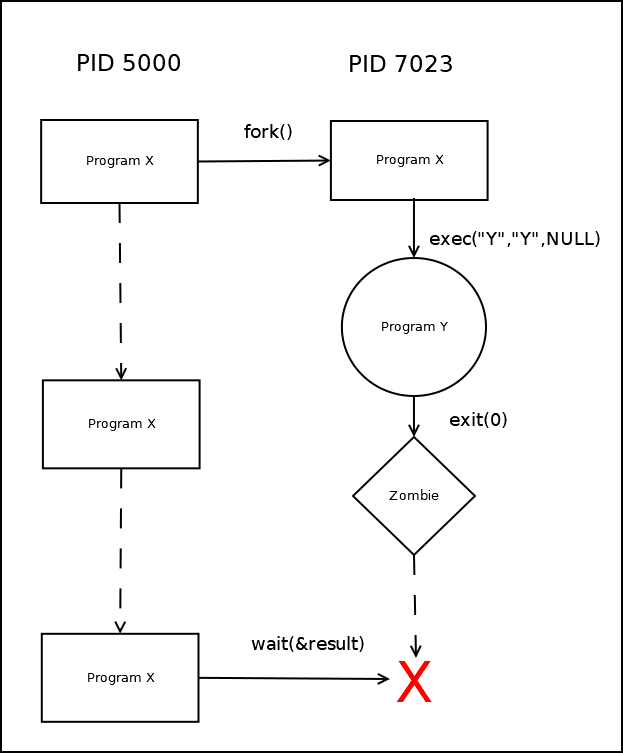
Создание процесса
Вызов newpid=fork() создает новый процесс, являющейся точной копией текущего и отличающийся лишь возвращаемым значением newpid. В родительском процессе newpid равно PID дочернего процесса, в дочернем процессе newpid равно 0. Свой PID можно узнать вызовом mypid=getpid(), родительский – вызовом parentpid=getppid().
Типичный пример
int pid, cpid;
int
int status;
pid=fork()
if( pid > 0 ){
cpid=waitpid(&status);
if( cpid > 0 ){
printf("Я старый процесс (pid=%i) создал новый (pid=%i) завершившийся с кодом %i\n",
getpid(),pid,WEXITSTATUS(status) );
}
}else if( pid == 0 ){
printf("Я новый процесс (pid=%i) создан старым (pid=%i)\n",getpid(),getppid());
}else{
perror("Страшная ошибка:");
}
Запуск программы
В оперативной памяти процесса находятся код и данные, загруженные из файла. При запуске программы из командной строки, обычно создается новый процесс и в его память загружается файл с программой. Загрузка файла делается вызовом одной из функций семейства exec (см. man 3 exec). Функции отличаются способом передачи параметров, а также тем, используется ли переменная окружения PATH для поиска исполняемого файла. Например execl в качестве первого параметра принимает имя исполняемого файла, вторым и последующими – строки аргументы, передаваемые в argv[], и, наконец, последний параметр должен быть NULL, он дает процедуре возможность определить, что параметров больше нет.
int pid=fork();
if( pid > 0 ){
waitpid(NULL);
}else if( pid == 0 ) {
if(-1 == execl("/bin/ls","ls","-l",NULL) ) {
exit(1);
}
}
Пример exec с двумя ошибками:
if( 0 == execl("/bin/ls","-l",NULL) ){
printf("Программа ls запущена успешно\n");
}else{
printf("Программа ls не запущена\n");
}
Ошибка 1: Первый аргумент передаваемый программе это имя самой программы. В данном примере в списке процессов будет видна программа с именем -l, запущенная без параметров.
Ошибка 2:
Поскольку код из файла /bin/ls будет загружен в текущий процесс, то старый код и данные, в том числе printf("Программа ls запущена успешно\n"), будет затерты. Первый printf не сработает никогда.
Завершение процесса
Процесс может завершиться, получив сигнал или через системный вызов _exit(int status). status может принимать значения от 0 до 255. По соглашению, status==0 означает успешное завершение программы, а ненулевое значение - означает ошибку. Некоторые программы (например kaspersky для Linux) используют статус для возврата некоторой информации о результатах работы программы.
_exit() может быть вызван несколькими путями.
return status;в функцииmain(). В этом случае_exit()выполнит некая служебная функция, вызывающаяmain()- через библиотечную функцию
exit(status), которая завершает работу библиотекиlibcи вызывает_exit() - явным вызовом
_exit()
Удаление завершенного процесса из таблицы процессов
После завершения процесса его pid остается занят - это состояние процесса называется "зомби". Чтобы освободить pid родительский процесс должен дождаться завершения дочернего и очистить таблицу процессов. Это достигается вызовом:
pid_t cpid=waitpid(pid_t pid, int *status, int options)
//или
pid_t cpid=wait(int *status)
Вызов wait(&status); эквивалентен waitpid(-1, &status, 0);
waitpid ждет завершения дочернего процесса и возвращает его PID. Код завершения и обстоятельства завершения заносятся в переменную status. Дополнительно, поведением waitpid можно управлять через параметр options.
- pid < -1 - ожидание завершения дочернего процесса из группы с pgid==-pid
- pid == -1 - ожидание завершения любого дочернего процесса
- pid == 0 - ожидание завершения дочернего процесса из группы, pgid которой совпадает с pgid текущего процесса
- pid > 0 - ожидание завершения любого дочернего процесса с указанным pid
Опция WNOHANG - означает неблокирующую проверку завершившихся дочерних процессов.
Статус завершения проверяется макросами:
- WIFEXITED(status) - истина если дочерний процесс завершился вызовом _exit(st)
- WEXITSTATUS(status) - код завершения st переданный в _exit(st)
- WIFSIGNALED(status) - истина если дочерний процесс завершился по сигналу
- WTERMSIG(status) - номер завершившего сигнала
- WCOREDUMP(status)истина если дочерний процесс завершился с дампом памяти
- WIFSTOPPED(status) истина если дочерний процесс остановлен
- WSTOPSIG(status) - номер остановившего сигнала
- WIFCONTINUED(status) истина если дочерний процесс перезапущен
Основы планирования процессов
Для обеспечения многозадачности каждый пользовательский процесс периодически прерывается, его контекст сохраняется, а управление передаётся другому процессу. Прерывание выполнения процесса может происходить по таймеру или во время обработки системного вызова. В зависимости от обстоятельств прерванный процесс ставится в очередь процессов на исполнение, в список процессов ожидающих ресурсы (например, ожидание пользовательского ввода или завершения вывода на физический носитель) или в список остановленных процессов.
Прерывания по таймеру происходят в соответствии с квантом времени, выделенному процессу. В Linux квант времени по умолчанию (DEF_TIMESLICE) равен 0,1 секунды, но может быть пересчитан планировщиком процессов (sheduler).
Системный вызов может завершиться с немедленным возвратом в пользовательскую программу, завершиться одновременно с исчерпание кванта времени или перейти в состояние ожидания ресурса .
В момент возврата в пользовательскую программу происходит доставка сигналов - т.е. вызов процедуры обработчика сигнала, остановка, перезапуск или завершение процесса. Некоторые сигналы (SIGSTOP) - приводят к тому, что процесс включается в список остановленных процессов, которые не поступают в очередь процессов на исполнение. Сигнал SIGCONT возвращает остановленный процесс в очередь процессов на исполнение, сигнал SIGKILL завершает остановленный процесс.
После завершения процесса вызовом _exit() или по сигналу все его ресурсы (память, открытые файлы) освобождаются, но запись в таблице процессов остаётся и занимает PID. Такой процесс называется "зомби" и должен быть явно очищен из таблицы процессов вызовом wait() в родительском процессе. Если родительский процесс завершился раньше дочерних, то всем его дочерним процессам приписывается значение PPID (parent pid) равное 1, возлагая обязательства по очистке от них таблицы процессов на особый процесс init с PID=1.
На диаграмме показаны различные состояния процесса
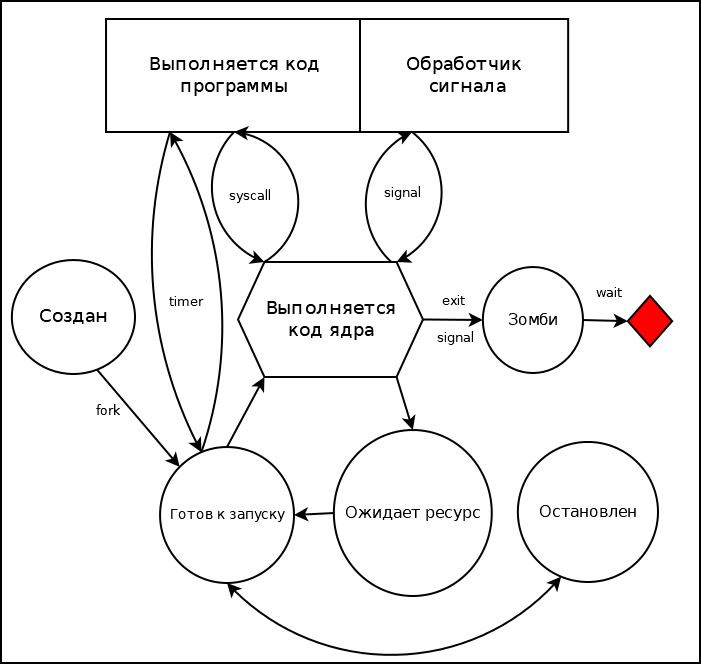
В Linux команда ps использует следующие обозначения состояния процесса:
- R выполняется (в том числе в обработчике сигнала) или стоит в очереди на выполнение
- S системный вызов ожидает ресурс, но может быть прерван
- D системный вызов ожидает ресурс, и не может быть прерван (обычно это ввод/вывод)
- T остановлен сигналом
- t остановлен отладчиком
- Z "Зомби" - завершён, но не удалён из списка процессов родительским процессом.
Планировщик процессов
Задачей планировщика процессов процессов является извлечение процессов, готовых на выполнение, в соответствии с некоторыми правилами. Планировщик старается распределить процессорные ресурсы так, чтобы ни один из процессов не простаивал длительное время, и чтобы процессы, считающиеся приоритетными, получали процессорное время в первую очередь. В многопроцессорных системах желательно, чтобы в последовательных квантах времени процесс запускался на одном и том же процессоре, чтобы максимально использовать процессорный кэш. При этом сам планировщик должен выполнять выбор как можно быстрее.
Простейшая реализация очереди в виде FIFO очень быстра, но не поддерживает приоритеты и многопроцессорность. В Linux 2.6 воспользовались простотой FIFO, добавив к ней несколько усовершенствований:
- Было определено 140 приоритетов (100 реального времени + 40 назначаемых динамически), каждый из которых получил свою очередь FIFO. На запуск выбирается первый процесс в самой приоритетной очереди.
- В многопроцессорных системах для каждого ядра был сформирован свой набор из 140 очередей. Раз в 0,2 секунды просматриваются размеры очередей процессоров и, при необходимости балансировки, часть процессов переносится с загруженных ядер на менее загруженные
- Динамический приоритет назначается процессу в зависимости от отношении времени ожидания ресурсов к времени пребывания в состоянии выполнения. Чем дольше процесс ожидал ресурс, тем выше его приоритет. Таким образом, диалоговые задачи, которые 99% времени ожидают пользовательского ввода, всегда имеют наивысший приоритет.
Ссылка: Планировщик задач Linux
Прикладной программист может дополнительно понизить приоритет процесса функцией int nice(int inc); (в Linux nice() - интерфейс к вызову setpriority()). Большее значение nice означает меньший приоритет. В командной строке используется "запускалка" с таким же именем:
nice -n 50 command
Процесс Idle
Если нет процессов готовых для выполнения, то планировщик вызывает нить (процесс) Idle. В Linux 2.2 однопроцессорная кроссплатформенная версия Idle выглядела так:
int cpu_idle(void *unused) {
for(;;)
idle();
}
В аппаратно-зависимую реализацию idle() может быть вынесено управление энергосбережением.
В ранних версиях Linux процесс Idle имел PID=0, но, вообще говоря, Idle как самостоятельный процесс не существует.
Вычисление средней загрузки
Средняя загрузка (Load Average, LA) - усредненная мера использования ресурсов компьютера запущенными процессами. Величина LA пропорциональна числу процессоров в системе и на ненагруженной системе колеблется от нуля до значения, равного числу процессоров. Высокие значения LA (10*число ядер и более) говорят о чрезмерной нагрузке на систему и потенциальных проблемах с производительностью.
В классическом Unix LA имеет смысл среднего количества процессов в очереди на исполнение + количества выполняемых процессов за единицу времени. Т.е. LA == 1 означает, что в системе считается один процесс, LA > 1 определяет сколько процессов не смогли стартовать, поскольку им не хватило кванта времени, а LA < 1 означает, что в системе есть незагруженные ядра.
В Linux к к количеству процессов добавили ещё и процессы, ожидающих ресурсы. Теперь на рост LA значительно влияют проблемы ввода/вывода, такие как недостаточная пропускная способность сети или медленные диски.
LA усредняется по следующей формуле LAt+1=(LAcur+LAt)/2. Где LAt+1 - отображаемое значение в момент t+1, LAcur - текущее измеренное значение, LAt - значение отображавшееся в момент t. Таким образом сглаживаются пики и после резкого падения нагрузки значение LA будет медленно снижаться, а кратковременный пик нагрузки будет отображен половинной величиной LA.
Ссылка: Как считается Load Average
Выдача команды top
Выдача команды top в Linux на компьютере с 36 ядрами:
top - 19:43:53 up 4 days, 5:54, 1 user, load average: 34.07, 33.75, 33.80
Tasks: 550 total, 12 running, 538 sleeping, 0 stopped, 0 zombie
%Cpu(s): 93.9 us, 0.5 sy, 0.0 ni, 5.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
На компьютере запущена многопоточная счётная задача, которая занимает почти все ядра и не использует ввод/вывод. LA немного меньше 36, что согласуется с распределением времени процессора: 93.9 us - пользователь, 0.5 sy - ядро, 5.5 id - Idle, 0.0 wa - ожидание устройств.
| Прикрепленный файл | Размер |
|---|---|
| 58.86 КБ |
{kind=link}
Эффективные права процесса
С каждым процессом Unix связаны два атрибута uid и gid - пользователь и основная группа. В принципе они могли бы определять права доступа процесса к ФС и другим процессам, однако существует несколько ситуаций, когда права процесса отличаются от прав его владельца. Поэтому кроме uid/gid (иногда называемых реальными ruid/rgid) с процессом связаны атрибуты прав доступа - эффективные uid/gid - euid/egid, чаще всего совпадающие с ruid/rgid. Кроме того, с uid связан список вспомогательных групп, описанных в файле /etc/group . euid/egid и список групп определяют права доступа процесса к ФС. Вновь создаваемые файлы наследуют атрибуты uid/gid от euid/egid процесса. Кроме того euid определяет права доступа к другим процессам (отладка, отправка сигналов и т.п.).
euid равный нулю используется для обозначения привилегированного процесса, имеющего особые права на доступ к ФС и другим процессам, а так же на доступ к административным функциям ядра, таким как монтирование диска или использование портов TCP с номерами меньше 1024. Процесс с euid=0 всегда имеет право на чтение и запись файлов и каталогов. Право на выполнение файлов предоставляется привилегированному процессу только в том случае, когда у файла выставлен хотя бы один атрибут права на исполнение.
Примечание: в современных ОС особые привилегии процесса определяются через набор особых флагов - capabilities и не обязательно привязаны к euid=0.
(re)uid/(re)gid, а также вспомогательные группы, наследуются от родительского процесса при вызове fork(). При вызове exec() ruid/rgid сохраняются, а euid/egid могут быть изменены если у исполняемого файла выставлен флаг смены владельца. Для скриптов флаг смены владельца игнорируется т.к. фактически запускается интерпретатор, а скрипт передаётся ему в качестве параметра. В момент входа пользователя в систему программа login считывает из файлов /etc/passwd и /etc/group необходимые величины и устанавливает их перед загрузкой командного интерпретатора.
Список вспомогательных групп можно считать в массив функцией int getgroups(int size, gid_t list[]). Будет ли при этом в списке основная группа неизвестно - это зависит от реализации конкретной ОС. Максимальное число вспомогательных групп можно получить так: long ngroups_max = sysconf(_SC_NGROUPS_MAX); или из командной строки getconf NGROUPS_MAX. В моём Linux'е максимальное число групп - 65536.
Для инициализации вспомогательных групп в Linux можно воспользоваться функцией int initgroups(const char *user, gid_t group); эта функция разбирает файл /etc/group, а за тем обращается к системному вызову int setgroups(size_t size, const gid_t *list);.
Существуют несколько функций для управление атрибутами uid/gid. Для экономии места далее перечисляются только функции для работы с uid. Получить значения атрибутов можно с помощью функций getuid(), geteuid() Установить значения можно с помощью
setuid(id); - установить ruid и euid в id
seteuid(id); - установить euid в id
setreuid(rid,eid); - установить ruid и euid в rid и eid. -1 в качестве параметра означает, что значение не меняется
В Linux, HP-UX и некоторых других ОС дополнительно поддерживаются атрибут сохраненных прав процесса suid/sgid (не путать с одноименными атрибутами файла). Соответственно есть функция для установки всех трёх атрибутов setresuid(rid,eid,sid);
Если euid=0 или ruid=0 то ruid и euid могут меняться произвольно. Т.е. можно сделать euid<>0 или ruid<>0, а затем вернуться в состояние euid=ruid=0. Если оба атрибута не равны нулю, то возможно лишь изменение euid в ruid (отказ от дополнительных прав). Программа su получает euid=0 благодаря соответствующему атрибуту файла и использует возможности привилегированного процесса для запуска программ от имени произвольного пользователя (в том числе root). Веб-сервер apache, наоборот, стартует с ruid=euid=0, но затем отбирает у себя лишние права меняя ruid и euid на непривилегированные значения.
Сигналы, группы, сеансы
Сигналы в Unix указывают ядру, что надо прервать нормальное планирование процесса и завершить/остановить его, или, вместо продолжения выполнения процесса с места остановки, выполнить функцию - обработчик сигнала, и лишь затем продолжить выполнение основного кода.
Сигналы, предназначенные процессу, создаются (отправляются) в нескольких ситуациях: при аппаратных сбоях, при срабатывании особого таймера, при обработке спецсимволов (Ctrl C, Ctrl Z) драйвером управляющего терминала, с помощью системного вызова kill(). В зависимости от причины, отправляются сигналы разных типов. Тип сигнала обозначается целым числом (номером). В Linux сигналы нумеруются от 1 до 64. Сигнал может быть отправлен отдельной нити процесса, процессу в целом или группе процессов.
Для каждого номера сигнала в процессе (нити) предусмотрено некоторое действие (действие по умолчанию, игнорирование или вызов пользовательской функции). Доставка сигнала заключается в выполнении этого действия.
Между отправкой сигнала и его доставкой проходит некоторое непредсказуемое время, поскольку, обычно, сигналы обрабатываются (доставляются) при выходе из системных вызовов или в тот момент, когда планировщик назначает процесс на выполнение. Исключением является доставка сигнала SIGKILL остановленным процессам. Для большинства сигналов можно явно приостановить доставку с помощью установки маски блокирования доставки sigprocmask(), и, в случае необходимости, удалить сигнал без обработки с помощью sigwait().
Сигналы SIGKILL и SIGSTOP не могут быть заблокированы или проигнорированы и на них нельзя установить свой обработчик.
Действия по умолчанию:
- SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU - остановка процесса
- SIGCONT - запуск остановленного процесса
- SIGCHLD - игнорируется
- SIGQUIT, SIGILL, SIGTRAP, SIGABRT, SIGFPE, SIGSEGV - сохранение дампа памяти и завершение (Linux)
- остальные - завершение процесса
Ссылка: ПРАВИЛА ИГРЫ В СИГНАЛЫ UNIX
Сигнал, маска, обработчик
В упрощенном виде структуру в ядре, обеспечивающую доставку сигналов процессу, можно представить как таблицу:
| Номер | Есть Сигнал? | Маска | Обработчик |
|---|---|---|---|
| 1 | 1 | 1 | SIG_DFL |
| 2 | 0 | 0 | SIG_IGN |
| 3 | 0 | 0 | sig_func() |
| ... | ... | ... | ... |
- Есть сигнал? - битовое поле, указывающее наличие недоставленного сигнала
- Маска - битовое поле, указывающее временный запрет на доставку сигнала
- Обработчик - указатель на действие, выполняемое при доставке сигнала. Может принимать значения: SIG_DFL - действие по умолчанию, SIG_IGN - игнорирование сигнала или указатель на функцию - обработчика сигнала.
Традиционно, при отправке процессу нескольких однотипных обычных сигналов, обработчик будет вызван лишь раз. Начиная с POSIX 1003.1, кроме обычных сигналов, поддерживаются сигналы реального времени, для которых создаётся очередь недоставленных сигналов, которая кроме номера сигнала, содержит значение (целое или адрес), которое уникально для каждого экземпляра сигнала.
Примеры использования сигналов
SIGKILL, SIGTERM, SIGINT, SIGHUP - завершение процесса. SIGKILL - не может быть проигнорирован, остальные могут. SIGTERM - оповещение служб о завершении работы ОС, SIGINT - завершение программы по нажатию Ctrl C, SIGHUP - оповещение программ, запущенных через модемное соединение, об обрыве связи (в настоящее время практически не используется).
SIGILL, SIGFPE, SIGBUS, SIGSEGV - аппаратный сбой. SIGILL - недопустимая инструкция CPU, SIGFPE - ошибка вычислений с плавающей точкой (деление на ноль), SIGBUS - физический сбой памяти, SIGSEGV - попытка доступа к несуществующим (защищенным) адресам памяти.
SIGSTOP, SIGCONT - приостановка и продолжение выполнения процесса
SIGPIPE - попытка записи в канал или сокет, у которого нет читателя
SIGCHLD - оповещение о завершении дочернего процесса.
Список сигналов
Особый сигнал с номером 0 фактически не доставляется, а используется в вызове kill() для проверки возможности доставки сигнала определённому процессу.
В Linux используется 64 сигнала. Список можно посмотреть в терминале командой kill -l
Posix.1-1990
Источник - man 7 signal
Signal Value Action Comment
-------------------------------------------------------------------------
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
SIGCHLD 20,17,18 Ign Child stopped or terminated
SIGCONT 19,18,25 Cont Continue if stopped
SIGSTOP 17,19,23 Stop Stop process
SIGTSTP 18,20,24 Stop Stop typed at tty
SIGTTIN 21,21,26 Stop tty input for background process
SIGTTOU 22,22,27 Stop tty output for background process
Отправка сигнала
int kill(pid_t pid, int signum);
Для отправка сигнала необходимо, чтобы uid или euid текущего процесса был равен 0 или совпадал с uid процесса получателя.
Получатель сигнала зависит от величины и знака параметра pid:
- pid > 0 - сигнал отправляется конкретному процессу
- pid == 0 - сигнал отправляется всем членам группы
- pid == -1 - сигнал отправляется всем процессам кроме init (в Linux'е еще кроме себя)
- pid < -1 - сигнал отправляется группе с номером -pid
Если signum == 0 - сигнал не посылается, но делается проверка прав на посылку сигнала и формируются код ответа и errno.
int sigqueue(pid_t pid, int sig, const union sigval value);
Аналогично kill(), но выполняется по правилам сигналов реального времени. Сигнал и связанная с ним дополнительная информация (целое или адрес) value помещаются в очередь сигналов (FIFO). Таким образом процессу можно отправить несколько однотипных сигналов с разными значениями value.
raise(int signum);
Отправка сигнала текущему процессу. Эквивалент kill(getpid(),signum);
abort();
Убирает из маски сигналов сигнала SIGABRT и отправляет его текущему процессу . Если сигнал перехватывается или игнорируется, то после возвращения из обработчика abort() завершает программу. Выхода из функции abort() не предусмотрено. Единственный способ продолжить выполнение - не выходить из обработчика сигнала.
alarm(time);
Отправка сигнала SIGALRM себе через time секунд. Возвращает 0 если ранее alarm не был установлен или число секунд остававшихся до срабатывания предыдущего alarma. Таймер управляющий alarm'ами один. Соответственно установка нового alarm'а отменяет старый. Параметр time==0 позволяет получить оставшееся до alarm'а время без установки нового.
Исторический способ обработки сигнала - signal
Установка реакции на сигнал через функцию signal() не до конца стандартизована и сохраняется для совместимости с историческими версиями Unix. Не рекомендуется к использованию. В стандарте POSIX signal() заменен на вызов sigaction(), сохраняющий для совместимости эмуляцию поведения signal().
signal(SIGINT,sighandler);
sighandler - адрес функции обработчика void sighandler(int) или один из двух макросов: SIG_DFL (обработчик по умолчанию) или SIG_IGN (игнорирование сигнала).
signal(...) возвращает предыдущее значение обработчика или SIG_ERR в случае ошибки.
В Linux и SysV при вызове sighandler обработчик сбрасывается в SIG_DFL и возможна доставка нового сигнала во время работы sighandler. Такое поведение заставляет первой строкой в sighandler восстанавливать себя в качестве обработчика сигнала, и, даже в этом случае, не гарантирует от вызова обработчика по умолчанию. В BSD системах сброс не происходит, доставка новых сигнала блокируется до выхода из sighandler.
Пример кода:
#include <signal.h>
void sighandler(int signum) {
signal(signum,sighandler);
...
}
main() {
signal(SIGINT,sighandler);
signal(SIUSR1,SIG_IGN);
signal(SIUSR2,SIG_DFL);
}
Реакция на сигнал - sigaction
Параметры для установки обработчика сигнала через sigaction()
struct sigaction {
void (*sa_handler)(int); // Обработчик сигнала старого стиля
void (*sa_sigaction)(int, siginfo_t *, void *); // Обработчик сигнала нового стиля
// Обработчик выбирается на основе флага SA_SIGINFO
// в поле sa_flags
sigset_t sa_mask; // Маска блокируемых сигналов
int sa_flags; // Набор флагов
// SA_RESETHAND - сброс обработчика на SIG_DFL после выхода из назначенного обработчика.
// SA_RESTART - восстановление прерванных системных вызовов после выхода из обработчика.
// SA_SIGINFO - вызов sa_sigaction вместо sa_handler
void (*sa_restorer)(void); // Устаревшее поле
}
Данные, передаваемые в обработчик сигнала sa_sigaction()
siginfo_t {
int si_signo; // Номер сигнала
int si_code; // Способ отправки сигнала или уточняющее значение
// SI_USER сигнал отправлен через вызов kill()
// SI_QUEUE сигнал отправлен через вызов sigqueue()
// FPE_FLTDIV - уточнение для сигнала SIGFPE - деление на ноль
// ILL_ILLOPC - уточнение для сигнала SIGILL - недопустимый опкод
// ...
pid_t si_pid; // PID процесса отправителя (дочернего процесса при SIGCHLD)
uid_t si_uid; // UID процесса отправителя
int si_status; // Статус завершения дочернего процесса при SIGCHLD
sigval_t si_value; // Значение, переданое через параметр value при вызове sigqueue()
void * si_addr; // Адрес в памяти
// SIGILL, SIGFPE - адрес сбойной инструкции
// SIGSEGV, SIGBUS - адрес сбойной памяти
}
В Linux структура siginfo_t содержит больше полей, но они служат для совместимости и не заполняются.
Код
#include <signal.h>
void myhandler(int sig) {
...
}
void myaction(int signum, siginfo_t * siginfo, void *code) {
...
}
main() {
struct sigaction act,oldact;
act.sa_sigaction=myaction;
act.sa_flags=SA_SIGINFO;
sigaction(signum, &act, &oldact);
}
Блокирование сигналов
Все функции блокирования сигналов работают с маской сигналов типа sigset_t. В Linux это 64 бита, т.е. два слова в 32х разрядной архитектуре или одно в 64х разрядной. Выставленный бит в маске сигналов означает, что доставка сигнала с соответствующим номером будет заблокирована. Сигналы SIGKILL и SIGSTOP заблокировать нельзя.
Манипулирование маской
#include <signal.h>
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum);
int sigismember(const sigset_t *set, int signum);
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); Изменить маску сигналов
Параметр how определяет операцию над текущей маской. Значения SIG_BLOCK, SIG_UNBLOCK, SIG_SETMASK.
Проверка наличия заблокированных сигналов
int sigpending(sigset_t *set); // Получить список недоставленных из-за блокировки сигналов.
int sigsuspend(const sigset_t *mask); //Установить новую маску и "уснуть" до получения и обработки разрешенного в ней сигнала.
Очистка заблокированных сигналов
sigwait ожидает блокировки какого-либо из сигналов, указанных в маске, удаляет этот сигнал и возвращает его номер в параметр sig. Если реализация сигналов предусматривает очередь сигналов, то удаляется только один элемент из очереди.
int sigwait(const sigset_t *set, int *sig);
Управляющий терминал, сеанс, группы
Управляющий терминал, сеанс, группы
Для организации диалоговой работы пользователей в Unix вводится понятие терминальной сессии. С точки зрения пользователя - это процесс работы с текстовым терминалом с момента ввода имени и пароля и до выхода из системы командой logout (exit, нажатие ^D в пустой строке). Во время терминальной сессии может быть запущено несколько программ, которые будут параллельно выполнятся в фоновом режиме и между которыми можно переключаться в диалоговом режиме. После завершения терминальной сессии возможно принудительное завершение всех запущенных в ней фоновых процессов.
С точки зрения ядра - терминальная сессия - это группа процессов, имеющих один идентификатор сеанса sid. С идентификатором sid связан драйвер управляющего терминала, доступный всем членам сеанса как файл символьного устройства /dev/tty. Для каждого сеанса существует свой /dev/tty. Управляющий терминал взаимодействует с процессами сеанса с помощью отправки сигналов.
В рамках одного сеанса могут существовать несколько групп процессов. С каждым процессом связан идентификатор группы pgid. Одна из групп в сеансе может быть зарегистрирована в драйвере управляющего терминала как группа фоновых процессов. Процессы могут переходить из группы в группу самостоятельно или переводить из группы в группу другие процессы сеанса. Перейти в группу другого сеанса нельзя, но можно создать свой собственный сеанс из одного процесса со своей группой в этом сеансе. Вернуться в предыдущий сеанс уже не получится.
Группа процессов
Группа процессов - инструмент для доставки сигнала нескольким процессам, а также способ арбитража при доступе к терминалу. Идентификатор группы pgid равен pid создавшего её процесса - лидера группы. Процесс может переходить из группы в группу внутри одного сеанса.
#include <unistd.h>
int setpgid(pid_t pid, pid_t pgid); // включить процесс pid в группу pgid.
// pid=0 означает текущий процесс,
// pgid=0 означает pgid=pid текущего процесса
// pid=pgid=0 - создание новой группы с pgid=pid текущего процесса
// и переход в эту группу
pid_t getpgid(pid_t pid); // получить номер группы процесса pid.
// pid=0 - текущий процесс
int setpgrp(void); // создание группы, эквивалент setpgid(0.0);
pid_t getpgrp(void); // запрос текущей группы, эквивалент getpgid(0);
Сеанс
Сеанс - средство для контроля путем посылки сигналов над несколькими группами процессов со стороны терминального драйвера. Как правило соответствует диалоговой пользовательской сессии. Идентификатор сеанса sid равняется идентификатору pid, создавшего его процесса - лидера сеанса. Одновременно с сеансом создаётся новая группа с pgid равным pid лидера сеанса. Поскольку переход группы из сеанса в сеанс невозможен, то создающий сеанс процесс не может быть лидером группы.
#include <unistd.h>
pid_t setsid(void); //Создание новой группы и нового сеанса. Текущий процесс не должен быть лидером группы.
pid_t getsid(pid_t pid); //Возвращает номер сеанса для указанного процесса
Создание собственного сеанса рекомендуется начать с fork, чтобы гарантировать, что процесс не является лидером группы.
if( fork() ) exit(0);
setsid();
Фоновая группа сеанса
Процессы в фоновой группе выполняются до тех пор, пока не попытаются осуществить чтение или запись через файловый дескриптор управляющего терминала. В этот момент они получают сигнал SIGTTIN или SIGTTOU соответственно. Действие по умолчанию для данного сигнала - приостановка выполнения процесса.
Назначение фоновой группы:
#include <unistd.h>
pid_t tcgetpgrp(int fd); // получить pgid фоновой группы, связанной с управляющим терминалом,
// на который ссылается файловый дескриптор fd
int tcsetpgrp(int fd, pid_t pgrp); // назначить pgid фоновой группы терминалу,
// на который ссылается файловый дескриптор fd
Управляющий терминал
Некоторые сочетания клавиш позволяют посылать сигналы процессам сеанса:
- ^C - SIGINT - завершение работы
- ^Z - SIGTSTP - приостановка выполнения.
bashотслеживает остановку дочерних процессов и вносит их в списки своих фоновых процессов. Остановленный процесс может быть продолжен командойfg n, где n - порядковый нрмер процесса в списке фоновых процессов
Открыть управляющий терминал сеанса
#include <stdio.h>
char name[L_ctermid];
int fd;
ctermid(name); // если name=NULL, то используется внутренний буфер
// ctermid возвращает указатель на буфер
// L_ctermid - библиотечная константа
fd = open(name, O_RDWR, 0);
Память процесса
Самые первые версии Unix работали на компьютерах без аппаратной поддержки виртуальной памяти, однако очень скоро такая поддержка появилась в большинстве процессорных архитектур и стала обязательным условием для возможности запуска Unix/Linux на соответствующей платформе. В линейке Intel аппаратная поддержка виртуальной памяти появилась в процессорах i286. С выходом этих процессоров на рынок связано появление лицензионной версии Unix для ПК - Xenix от Microsoft.
Страничная организация памяти
Несмотря на то, что современные процессоры адресуют память с точностью до байта, основными единицами управления памятью в Unix являются страницы.
Страница - это минимальная единица отображения непрерывного диапазона адресов виртуальной памяти на непрерывный диапазон адресов физической памяти. Соответственно, выделение физической память для данных процессов и ядра, а так же буферов дискового кеша и буферов для получения данных с устройств по DMA всегда выполняется страницами.
Страничная организация памяти поддерживается специализированным аппаратным устройством - модулем управления памятью (MMU, Memory Management Unit), которое выполняет преобразование виртуальных адресов в физические. MMU может быть интегрировано в процессор или входить в чипсет.
Размеры страниц отличаются для различных аппаратных платформ.Можно считать, что для 32-разрядных аппаратных платформ размер страницы равен 4 Кбайта, а для 64-разрядных платформ - 8 Кбайт. Современные процессоры от Intel позволяют выбирать размер страницы, и, соответственно, ядро Linux позволяет управлять этим выбором.
Отображение виртуальной памяти в физическую осуществляется через таблиц страниц, в которых каждой виртуальной странице ставится в соответствие физический адрес. Таблицы страниц хранятся в ОЗУ, а физический адрес текущей таблицы страниц заносится в специальный регистр процессора.
Для каждого процесса в момент его создания инициализируется своя таблица страниц. Таким образом одни и те же адреса в виртуальной памяти различных процессов ссылаются на различные адреса физической памяти. Благодаря этому, физические страницы памяти одного процесса становятся недоступными для других процессов. Таблица страниц ядра отображает часть адресов на физическую память, в которой расположено само ядро, а вторую часть - на страницы памяти какого-либо процесса. Такая таблица позволят ядру получить доступ к физической памяти процессов для копирования входных/выходных данных системных вызовов. Например, при вызове read(fd,buf,size) код в ядре имеет доступ к буферу buf для заполнения его данными, прочитанными из файла.
Таблица страниц процесса не отображается в его виртуальную память, а команда процессора, загружающая адрес таблицы страниц в соответствующий регистр, является привилегированной и не может быть выполнена в коде пользовательского процесса. Это не даёт процессам возможности хоть как-то повлиять на таблицы страниц. В момент переключения на выполнение кода ядра (по аппаратному прерыванию или при системном вызове) процессор переключается в привилегированный режим, после чего код в ядре может указать в регистре свою таблицу страниц, которая включает отображение всей физической памяти, после чего ядро может поменять таблицу страниц любого процесса.
Интересное замечание: существуют процессорные архитектуры, в которых физическая память может быть больше виртуальной. Так серверные материнские платы на процессорах x32 позволяют устанавливать больше чем 4 Гбайта оперативной памяти, в этом случае ядру приходится модифицировать часть собственной таблицы страниц, чтобы получить доступ к нужным участкам физической памяти.
Часть ссылок в таблице страниц может иметь специальное значение, указывающее на то, что страница не отображается на физическую память. Данный механизм используется для реализации файлов подкачки (swap). При попытке обращения к такой "несуществующей" странице, возникает аппаратное прерывание, которое обрабатывается в ядре. Код ядра может выделить процессу свободную страницу физической памяти, загрузить в неё данные из файла подкачки, поменять таблицу страниц так, чтобы требуемая виртуальная память отображалась на свежеподготовленную физическую ти вернуть управления процессу. Выполнение процесса начнётся с той же инструкции доступа к памяти, на которой возникло прерывание, но теперь эта инструкция выполнится нормально, поскольку изменилась ТС.
В некоторых случаях возможно отображение одной физической страницы памяти в виртуальную память нескольких процессов. Такое совместное использование физической памяти называется разделяемой памятью (shared memory). Данный механизм используется для обмена данными между процессами и требует аппаратной или программной поддержки в виде семафоров, для синхронизации параллельного доступа к памяти.
Часть физической памяти используется для хранения файлового кеша. В кеше хранится блоки данных файла размерами кратными странице памяти. При операциях считывания/записи в ядре происходит копирование нужного числа страниц между памятью процесса и кешем, а операции с файловой системой откладываются по времени. Если физическую память требуется освободить, то она сохраняется в файл, если кто-то обращается к странице, отсутствующей в кеше, она считывается из файла. Как правило, страницы кеша доступны только ядру, однако существует несколько случаев, когда они отображаются непосредственно в виртуальную память процессов. Механизм отображения страниц кеша в память процесса называется отображением файлов в память (memory mapped file). Данный механизм может использоваться как альтернатива разделяемой памяти (анонимные файлы в памяти), а так же как механизм совместного использования кода программ, путём отображения секции кода из исполняемого файла в виртуальное адресное пространство процессов, которые этот код исполняют.
При создании нового процесса вызовом fork() (в Linux фактически вызывается clone()) таблица страниц копируется в дочерний процесс и некоторое время родительский и дочерний процесс совместно используют общую физическую память. В дальнейшем, при изменении какой-либо страницы в одном из двух процессов для этого процесса создаётся копия страницы в физической памяти и соответственно изменяется таблица страниц. Данный механизм позволяет экономить время при создании нового процесса. Этот механизм называется "копирование при записи" (Copy on write, COW).
Созданиие новых потоков в Linux вызовом clone() аналогично созданию нового процесса, но дочерний процесс наследует от родительского процесса таблицу страниц. Таким образом, потоки в Linux можно рассматривать как дочерние процессы, использующие общую с родительским процессом виртуальную память. Главным отличием между процессами является размещение стека в виртуальной памяти.
Вызов execve("prog_file"), загружающий в память процесса новую программу, полностью изменяет таблицу страниц, освобождая занятую физическую память и выделяя новую, которая инициализируется в соответвии с данными, хранящимися в исполняемом файле.
Области памяти
Вся виртуальная память процесса в Linux поделена на несколько областей (сегментов), различного назначения. Выделяются следующие области:
- сегмент кода, содержащий инструкции процессора, который отображается на соответствующие области исполняемого файла. Традиционно обозначается как text.
- сегмент инициализированных глобальных переменных, которые изначально загружаются из исполняемого файла. Обозначаются как data.
- сегмент неинициализированных глобальных переменных, который изначально заполнен нулями. Традиционно обозначается BSS (Block Started by Symbol). Поскольку хранить в исполняемом файле нули не имеет смысла, то в нём хранится имя переменной (symbol) и её размер, а выделение памяти и инициализация нулями, происходит в момент запуска программы.
- сегмент стека - Stack.
- область кучи, для динамического выделения памяти функциями malloc(), new() и т.п. - Heap.
- дополнительные сегменты кода, данных и BSS для каждой разделяемой между процессами библиотеки, такой как библиотека libc. Динамические библиотеки в Linux имеют суффикс в имени файла - .so, что означает shared object.
- область для отображения в память файлов.
- область для отображения разделяемой памяти (shared memory).
- в современном Linux в отдельные области памяти vsyscall и vdso (virtual dynamic shared object) вынесен часто вызываемый код ядра, не требующий системных полномочий. В качестве примера такого обычно приводят вызов gettimeofday(). Вынесение кода в виртуальную память пространства помогает сэкономить время, расходуемое на изменение таблицы страниц во время системного вызова.
Каждая область памяти описывается структурой, которая хранит начало и конец области в виртуальном пространстве процесса, позицию в файле, если область является отображением файла в память, права доступа и флаги, описывающие свойства области.
Флаги, описывающие права доступа к страницам, входящих в область:
- VM_READ - страницы памяти можно читать
- VM_WRITE - в страницы памяти можно писать
- VM_EXEC - можно выполнять код, хранящийся в страницах памяти
- VM_SHARED - изменения страницы памяти будут видны всем процессами, которые совместно используют эту страницу. Если этот флаг не выставлен, то память считается "приватной" и, при первой записи в неё, процессу будет создана персональная копия страницы в физической память.
Просмотреть список областей процесса можно в файле /proc/
Пример вывода программой cat собственных областей памяти. Буква p в флагах доступа означает private. Если бы область использовалась совместно, то стояла бы буква s -shared.
$ cat /proc/self/maps
00400000-0040b000 r-xp 00000000 fd:01 134395423 /usr/bin/cat
0060b000-0060c000 r--p 0000b000 fd:01 134395423 /usr/bin/cat
0060c000-0060d000 rw-p 0000c000 fd:01 134395423 /usr/bin/cat
017f1000-01812000 rw-p 00000000 00:00 0 [heap]
7f5f529df000-7f5f58f08000 r--p 00000000 fd:01 67442653 /usr/lib/locale/locale-archive
7f5f58f08000-7f5f590cb000 r-xp 00000000 fd:01 201328510 /usr/lib64/libc-2.17.so
7f5f590cb000-7f5f592ca000 ---p 001c3000 fd:01 201328510 /usr/lib64/libc-2.17.so
7f5f592ca000-7f5f592ce000 r--p 001c2000 fd:01 201328510 /usr/lib64/libc-2.17.so
7f5f592ce000-7f5f592d0000 rw-p 001c6000 fd:01 201328510 /usr/lib64/libc-2.17.so
7f5f592d0000-7f5f592d5000 rw-p 00000000 00:00 0
7f5f592d5000-7f5f592f7000 r-xp 00000000 fd:01 201328504 /usr/lib64/ld-2.17.so
7f5f594e8000-7f5f594eb000 rw-p 00000000 00:00 0
7f5f594f5000-7f5f594f6000 rw-p 00000000 00:00 0
7f5f594f6000-7f5f594f7000 r--p 00021000 fd:01 201328504 /usr/lib64/ld-2.17.so
7f5f594f7000-7f5f594f8000 rw-p 00022000 fd:01 201328504 /usr/lib64/ld-2.17.so
7f5f594f8000-7f5f594f9000 rw-p 00000000 00:00 0
7ffc13623000-7ffc13644000 rw-p 00000000 00:00 0 [stack]
7ffc13785000-7ffc13787000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
| Прикрепленный файл | Размер |
|---|---|
| 33.08 КБ |
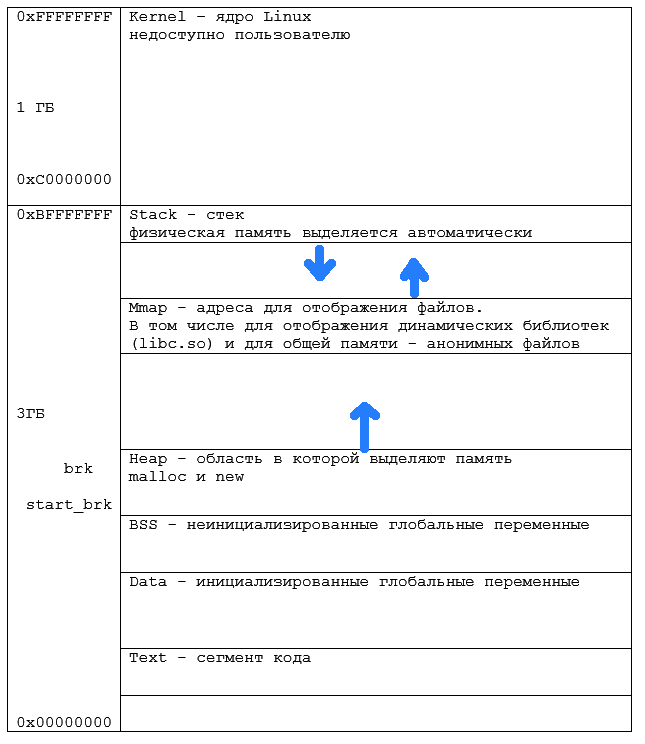{kind=link}
Распределение адресов в памяти процесса Linux i386
Адресация в архитектуре i386
Подробности связанные с аппаратной поддержкой управления памятью в процессорах, совместимых с i386, можно посиотреть по ссылке. Ссылка: Исследование модели памяти Linux
Распределение адресов в памяти процесса Linux i386
Размеры сегментов text, data и bss исполняемого файла можно посмотреть командой size:
$ size /bin/ls
text data bss dec hex filename
103119 4768 3360 111247 1b28f /bin/ls

В новых версиях Linux положение стека и кучи рандомизируется случайными смещениями, а область Mmap растёт вниз. Ссылка: Организация памяти процесса
Тестовая программа
Тестовая программа
#include <unistd.h>
#include <malloc.h>
#include <stdio.h>
#include <sys/mman.h>
int bss, data=10;
int main(int argc, char *argv[])
{
int stack;
void *heap, *brk, *mmp;
heap=malloc(1);
brk=sbrk(0);
mmp=mmap(0,1,PROT_READ,MAP_SHARED|MAP_ANONYMOUS,-1,0);
printf("Text=%p\nData=%p\nBSS=%p\nHeap=%p\nBrk=%p\nlibc.so=%p\nMmap=%p\nStack=%p\nArgv=%p\n ",main,&data,&bss,heap,brk,printf,mmp,&stack,argv);
sleep(100);
return 0;
}
Вывод тестовой программы
$ ./testmap
Text =0x0045c690
Data =0x0045e02c
BSS =0x0045e034
Heap =0x01435008
Brk =0x01456000
libc.so=0xb75bb940
Mmap =0xb773a000
Stack =0xbfe8f850
Argv =0xbfe8f924
Распределение памяти тестовой программы
$ ./testmap >/dev/null &
[1] 6662
$ cat /proc/6662/maps
0042a000-0042b000 r-xp 00000000 08:01 305009 /home/student/testmap
0042b000-0042c000 r--p 00000000 08:01 305009 /home/student/testmap
0042c000-0042d000 rw-p 00001000 08:01 305009 /home/student/testmap
00ece000-00eef000 rw-p 00000000 00:00 0 [heap]
b7603000-b77b4000 r-xp 00000000 08:01 151995 /lib/i386-linux-gnu/libc-2.24.so
b77b4000-b77b5000 ---p 001b1000 08:01 151995 /lib/i386-linux-gnu/libc-2.24.so
b77b5000-b77b7000 r--p 001b1000 08:01 151995 /lib/i386-linux-gnu/libc-2.24.so
b77b7000-b77b8000 rw-p 001b3000 08:01 151995 /lib/i386-linux-gnu/libc-2.24.so
b77b8000-b77bb000 rw-p 00000000 00:00 0
b77cb000-b77cc000 r--s 00000000 00:05 100324 /dev/zero (deleted)
b77cc000-b77ce000 rw-p 00000000 00:00 0
b77ce000-b77d0000 r--p 00000000 00:00 0 [vvar]
b77d0000-b77d2000 r-xp 00000000 00:00 0 [vdso]
b77d2000-b77f5000 r-xp 00000000 08:01 138298 /lib/i386-linux-gnu/ld-2.24.so
b77f5000-b77f6000 r--p 00022000 08:01 138298 /lib/i386-linux-gnu/ld-2.24.so
b77f6000-b77f7000 rw-p 00023000 08:01 138298 /lib/i386-linux-gnu/ld-2.24.so
bff5d000-bff7e000 rw-p 00000000 00:00 0 [stack]
$ uname -a
Linux antix-1 4.9.87-antix.1-486-smp #1 SMP Tue Mar 13 12:29:54 EDT 2018 i686 GNU/Linux
Управление областями памяти
Стек процесса
Вообще говоря, стеков в процессе может быть много и размещаться они могут в разных областях виртуальной памяти. Вот несколько примеров:
Cтек основной нити.
Он же стек процесса в однопоточном приложении. Начальный адрес выделяется ядром. Размер стека может быть изменён в командной строке до запуска программы командой ulimit -s <размер в килобайтах> или вызовом setrlimit
#include <sys/resource.h>
...
struct rlimit rl;
int err;
rl.rlim_cur = 64*1024*1024;
err = setrlimit(RLIMIT_STACK, &rl);
Стек обработчика сигналов
Стек обработчика сигналов может быть расположен в любой области памяти, доступной на чтение и запись. Альтернативный стек создаётся вызовом sigaltstack(new, old), которому передаются указатели на структуры, описывающие стек:
typedef struct {
void *ss_sp; /* Base address of stack */
int ss_flags; /* Flags */
size_t ss_size; /* Number of bytes in stack */
} stack_t;
После создания альтернативного стека можно задавать обработчик сигнала, указав в параметрах функции sigaction() флаг SS_ONSTACK.
Стек нити
При создании новой нити для всегда создаётся новый стек. Функция инициализации нити pthread_attr_init(pthread_attr_t *attr) позволяет вручную задать базовый адрес стека нити и его размер через поля attr.stackaddr и attr.stacksize. В большинстве случаев рекомендуется предоставить выбор адреса и размера стека системе, задав attr.stackaddr=NULL; attr.stacksize=0;.
Выделение памяти из кучи
Динамическое выделение памяти в куче (heap) реализовано на уровне стандартных библиотек C/C++ (функция malloc() и оператор new соответственно). Для распределения памяти из кучи процесс должен сообщить ядру, какой размер виртуальной памяти должен быть отображён на физическую память. Для этого выделяется участок виртуальной памяти, расположенный между адресами start_brk и brk. Величина start_brk фиксирована, а brk может меняться в процессе выполнения программы. Brk (program break - обрыв программы) - граница в виртуальной памяти на которой заканчивается отображение в физическую память. В современном Linux за этой границей могут быть отображения файлов и кода ядра в память процесса, но в оригинальном Unix это был "край" памяти программы. Начальное значение brk - start_brk устанавливается в момент загрузки программы из файла вызовом execve() и указывает на участок после инициализированных (data) и неинициализированных (BSS) глобальных переменных.
Для того, чтобы изменить размер доступной физической памяти, необходимо изменить верхнюю границу области кучи.
#include <unistd.h>
int brk(void *addr); //явное задание адреса
void *sbrk(intptr_t increment); //задание адреса относительно текущего значения
// возвращает предыдущее значение адреса границы
Вызов brk() устанавливает максимальный адрес виртуальной памяти, для которого в сегменте данных выделяется физическая память. Увеличение адреса равноценно запросу физической памяти, уменьшение - освобождению физической памяти.
Вызов sbrk(0) позволяет узнать текущую границу сегмента памяти.
В Linux вызов brk() транслируется в вызов функции ядра do_mmap(), изменяющий размер анонимного файла, отображаемого в память.
do_mmap(NULL, oldbrk, newbrk-oldbrk,
PROT_READ|PROT_WRITE|PROT_EXEC,
MAP_FIXED|MAP_PRIVATE, 0)
Файлы, отображаемые в память
Отображение содержимого файла в виртуальную память mmap() задействует кэш файловой системы. Некоторые страницы виртуальной памяти отображаются на физические страницы кэша. В тех ситуациях, когда обычные физические страницы сохраняются в своп, страницы, отображенные в файлы сохраняются в сами файлы. Отображение файлов в память может использоваться, в частности, для отображения секций кода исполняемых файлов и библиотек, в соответствующие сегменты памяти процесса.
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int msync(void *addr, size_t length, int flags);
int munmap(void *addr, size_t length);
Функция mmap() отображает length байтов, начиная со смещения offset файла, заданного файловым дескриптором fd, в память, начиная с адреса addr. Параметр addr является рекомендательным, и обычно бывает выставляется в NULL. mmap() возвращает фактический адрес отображения или значение MAP_FAILED (равное (void *) -1) в случае ошибки.
Аргумент prot описывает режим доступа к памяти (не должен конфликтовать с режимом открытия файла).
- PROT_EXEC данные в отображаемой памяти могут исполняться
- PROT_READ данные можно читать
- PROT_WRITE в эту память можно писать
- PROT_NONE доступ к этой области памяти запрещен.
Параметр flags указывает, видны ли изменения данных в памяти другим процессам, отобразившим этот фрагмент файла в свою память, и влияют ли эти изменения на сам файл.
- MAP_SHARED запись в эту область памяти будет эквивалентна записи в файл и изменения доступны другим процессам. Файл может не обновляться до вызова функций
msync()илиmunmap(). - MAP_PRIVATE неразделяемое отображение с механизмом copy-on-write. Запись в эту область приводит к созданию для процесса персональной копии данных в памяти и не влияет на файл.
- MAP_ANONYMOUS память не отображается ни в какой файл, аргументы fd и offset игнорируются. Совместно с MAP_SHARED может использоваться для создания общей памяти, разделяемой с дочерними процессами
- MAP_FIXED память обязательно отображается с адреса
addrили возвращается ошибка. Не рекомендуется к использованию, так как сильно зависит от архитектуры процессора и конкретной ОС.
msync() сбрасывает изменения сделанные в памяти в отображенный файл. Параметры addr и length позволяют синхронизировать только часть отображенной памяти.
munmap() отменяет отображение файла в память и сохраняет сделанные в памяти изменения в файл.
Разделяемая память в System V IPC
В подсистеме межпроцессного взаимодействия System V IPC (System five interprocess communication - названо в по имени версии Unix, в которой эта подсистема появилась) для совместной работы с памятью используется резервирование физической памяти на уровне ядра. После резервирования процессы могут отображать зарезервированную память в своё виртуальное адресное пространство используя для идентификации зарезервированного участка идентификатор, генерируемый специальным образом.
Данное резервирование не привязано к какому-либо процессу и сохраняется даже тогда, когда ни один процесс эту физическую память не использует. Таким образом выделение памяти для совместного использования становится "дорогим" с точки зрения использованных ресурсов. Программа, резервирующая области памяти для совместного доступа и не освобождающая их, может либо исчерпать всю доступную память, либо занять максимально доступное в системе количество таких областей.
У областей совместно используемой памяти, как и других объектов System V IPC есть атрибуты "пользователь-владелец", "группа-владельца", "пользователь-создатель", "группа-создателя", а так же права на чтение и запись для владельца, группы-владельца и остальных, аналогичные файловым. Например: rw- r-- ---.
Пример вызовов для работы общей памятью:
// создание ключа на основе inode файла и номера проекта
// файл не ложен удаляться до завершения работы с общей памятью
key_t key=ftok("/etc/hostname", 456);
// получение идентификатора общей памяти на основе ключа
// размером size байт с округлением вверх
// до размера кратного размеру страницы
//
// опция IPC_CREAT - говорит, что если память ещё не зарезервирована
// то должна быть выполнена резервация физической памяти
size=8000
int shmid=shmget(key, size, IPC_CREAT);
// подключение зарезервированной памяти к виртуальному адресному пространству
// второй параметр - желаемый начальный адрес отображения
// третий параметр - флаги, такие как SHM_RDONLY
int *addr=(int *)shmat(shmid, NULL, 0);
// можно работать с памятью по указателю
addr[10]=23;
// отключение разделяемой памяти от виртуального адресного пространства
int err;
err=shmdt(addr);
// освобождение зарезервированной памяти
err=shmctl(shmid, IPC_RMID, NULL);
Список всех зарезервированных областей памяти в системе можно просмотреть командой lspci -m:
lsipc -m
KEY ID PERMS OWNER SIZE NATTCH STATUS CTIME CPID LPID COMMAND
0xbe130fa1 3112960 rw------- root 1000B 11 May03 7217 9422 /usr/sbin/httpd -DFOREGROUND
0x00000000 557057 rw------- usr74 384K 2 dest Apr28 17752 7476 kdeinit4: konsole [kdeinit]
0x00000000 5898243 rw------- usr92 512K 2 dest 12:05 5265 9678 /usr/bin/geany /home/s0392/1_1.s
0x00000000 4521988 rw------- usr75 384K 2 dest May06 22351 16323 sview
0x00000000 3276805 rw------- usr15 384K 1 dest May05 24835 15236
0x00000000 4587530 rw------- usr75 2M 2 dest May06 19404 16323 metacity
OOM Killer
Выделение физической памяти в Linux оптимистично. В момент вызова brk() проверяется лишь то факт, что заказанная виртуальная память не превышает общего объёма физической памяти + размер файла подкачки. Реальное выделение памяти происходит при первой записи. В этом случае может оказаться, что вся доступная физическая память и своп уже распределены между другими процессами.
При нехватке физической памяти Linux запускает алгоритм Out of memory killer (OOM killer) который относительно случайно выбирает один из процессов и завершает его, освобождая тем самым физическую память.
Формат исполняемых файлов
Тестовая программа
Программа size выдает размер секций исполняемого файла. По умолчанию выдаётся суммарный размер по типам в формате Berkley:
$ size /bin/ls
text data bss dec hex filename
103119 4768 3360 111247 1b28f /bin/ls
Опция -A выдает все секции в формате SystemV:
$ size -A /bin/ls
/bin/ls :
section size addr
.interp 28 4194872
.note.ABI-tag 32 4194900
...
.init 26 4202832
.plt 1808 4202864
.plt.got 24 4204672
.text 65866 4204704
.fini 9 4270572
...
.data 576 6402976
.bss 3360 6403552
.gnu_debuglink 16 0
.gnu_debugdata 3296 0
Total 114559
Заголовок ELF
$ objdump -f ./mmp
./mmp: file format elf32-i386
architecture: i386, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x080483e0
Заголовки секций
$ objdump -h ./mmp
./mmp: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .interp 00000013 08048154 08048154 00000154 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
1 .note.ABI-tag 00000020 08048168 08048168 00000168 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .note.gnu.build-id 00000024 08048188 08048188 00000188 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .gnu.hash 00000024 080481ac 080481ac 000001ac 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .dynsym 00000090 080481d0 080481d0 000001d0 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
5 .dynstr 00000063 08048260 08048260 00000260 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
6 .gnu.version 00000012 080482c4 080482c4 000002c4 2**1
CONTENTS, ALLOC, LOAD, READONLY, DATA
7 .gnu.version_r 00000020 080482d8 080482d8 000002d8 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
8 .rel.dyn 00000008 080482f8 080482f8 000002f8 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
9 .rel.plt 00000030 08048300 08048300 00000300 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
10 .init 00000023 08048330 08048330 00000330 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
11 .plt 00000070 08048360 08048360 00000360 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
12 .plt.got 00000008 080483d0 080483d0 000003d0 2**3
CONTENTS, ALLOC, LOAD, READONLY, CODE
13 .text 00000242 080483e0 080483e0 000003e0 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
14 .fini 00000014 08048624 08048624 00000624 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
15 .rodata 00000058 08048638 08048638 00000638 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
16 .eh_frame_hdr 0000002c 08048690 08048690 00000690 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
17 .eh_frame 000000b0 080486bc 080486bc 000006bc 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
18 .init_array 00000004 08049f08 08049f08 00000f08 2**2
CONTENTS, ALLOC, LOAD, DATA
19 .fini_array 00000004 08049f0c 08049f0c 00000f0c 2**2
CONTENTS, ALLOC, LOAD, DATA
20 .jcr 00000004 08049f10 08049f10 00000f10 2**2
CONTENTS, ALLOC, LOAD, DATA
21 .dynamic 000000e8 08049f14 08049f14 00000f14 2**2
CONTENTS, ALLOC, LOAD, DATA
22 .got 00000004 08049ffc 08049ffc 00000ffc 2**2
CONTENTS, ALLOC, LOAD, DATA
23 .got.plt 00000024 0804a000 0804a000 00001000 2**2
CONTENTS, ALLOC, LOAD, DATA
24 .data 00000008 0804a024 0804a024 00001024 2**2
CONTENTS, ALLOC, LOAD, DATA
25 .bss 00000008 0804a02c 0804a02c 0000102c 2**2
ALLOC
26 .comment 0000002d 00000000 00000000 0000102c 2**0
CONTENTS, READONLY
System V IPC
Интерфейс межпроцессного взаимодействия System V IPC позволяет манипулировать классическими набором объектов, таких как: очередь сообщений, семафор и разделяемая память.
Объекты System V IPC идентифицируется 32-битным ключом IPC, играющего роль, аналогичную имени файла. При создании объекта IPC ему присваивается уникальный 32-битный идентификатор IPC, аналогичный inode файла. Идентификаторы IPC назначаются ядром, ключи IPC произвольно выбираются программистами.
У каждого объект IPC есть атрибуты "пользователь-владелец", "группа-владельца", "пользователь-создатель", "группа-создателя", а так же права на чтение и запись для владельца, группы-владельца и остальных, аналогичные файловым. Например: rw- r-- ---.
Впервые System V IPC появился во внутренних версиях Unix, использовавшихся в компании Bell Laboratories, но массовое распространение получил вместе с самой продаваемой версией Unix - System V, что и отражено в названии.
System V IPC имеет некоторые недостатки, в частности, плохую масштабируемость, в связи с тем, что создаваемые объекты не привязаны к процессам, и потому могут оставаться в памяти до перезагрузки ОС .
В последующем, System V IPC с небольшими изменениями вошёл в стандарт POSIX. Логика работы с объектами сохранилась, однако была проведена некоторая унификация вызовов System V IPC с вызовами файловой системы. Соответственно, поменялись имена функций.
Примеры отличий System V IPC и POSIX
В System V IPC для именования объекта создаётся особый 32-битный ключ, часто формируемый из inode существующего файла и целого числа, в POSIX имена объектов имитируют имена файловой системы в формате /object_name.
Набор функций для работы с разделяемой памятью из shmget(), shmat(), shmdt(), shmctl() превратился в shm_open(), mmap(), shm_unlink().
shmget() возвращает идентификатор IPC, а shm_open() возвращает файловый дескриптор.
shmat(), shmdt() работают только с разделяемой памятью, а mmap() одинаково успешно работает как с объектом "разделяемая память", так и с файлами, отображаемыми в память.
Размер сегмента разделяемой памяти System V IPC неизменен, а в POSIX может изменяться вызовом ftruncate() с последующим обновлением отображения в память процесса вызовами munmap() и mmap() .
Наличие сообщений в очередях POSIX может мониториться через callback, который устанавливается вызовом mq_notify().
Классический API System V IPC
Пространство имён
Объекты System V IPC идентифицируется 32-битным ключом IPC, играющего роль, аналогичную имени файла. При создании объекта IPC ему присваивается уникальный 32-битный идентификатор IPC, аналогичный inode файла. Идентификаторы IPC назначаются ядром, ключи IPC произвольно выбираются программистами.
Особое значение ключа IPC_PRIVATE адресует объект, доступный только данному процессу и его потомкам. Данное значение позволяет избежать случайного доступа к посторонним объектам из-за конфликта ключей.
В случае совпадения идентификаторов несколько программ будут пытаться получить доступ к одному и тому же объекту. Не существует механизма, гарантирующего выбор уникального ключа IPC, поэтому была создана специальная функция ftok(), генерирующая ключ на основе уникального имени файла в файловой системе (точнее номера его Inode) и дополнительного байта (номера проекта). При выборе файла, для формирования ключа, необходимо обеспечить достаточную длительность его жизни. Если файл удалён, то новые процессы не смогут сгенерировать ключи доступа к объектам IPC на основе данного файла. Удаление файла и создание нового с тем же именем так же нарушит доступ к объектам IPC поскольку новый файл будет иметь отличный номер Inode.
#include <sys/types.h>
#include <sys/ipc.h>
key_t ftok("/home/bob/key_base", 'Z');
Реализация ftok() в glibc
if (__xstat64 (_STAT_VER, pathname, &st) < 0)
return (key_t) -1;
key = ((st.st_ino & 0xffff) | ((st.st_dev & 0xff) << 16)
| ((proj_id & 0xff) << 24));
return key;
Создание и удаление объектов
Объекты IPC создаются функциями msgget(), semget(), shmget().
При создании используются флаги
- IPC_CREAT - Создать объект если он не существовал
- IPC_EXCL - Совместно с IPC_CREAT - вернуть ошибку если объект существует
и права доступа. Права доступа аналогичны файлам (mode - rw-rw-rw-)
Управление объектами SysV IPC (в том числе их уничтожение) производится c помощью функций msgctl(), semctl(), shmctl(). Параметр cmd этих функций может принимать значения:
- IPC_RMID - удалить объект
- IPC_SET - изменить свойства объекта
- IPC_STAT - получить свойства объекта
Флаги операций
Во всех операциях с объектами может быть указан дополнительный флаг
- IPC_NOWAIT - возвратить ошибку если операция не может быть выполнена немедленно
Очередь сообщений
При создании очереди она ассоциируется с буфером размером MSGMNB (16384 байт в Linux).
Сообщение состоит из заголовка фиксированной длины и текста переменной длины. Размер текста не должен превышать MSGMAX (8192 байта в Linux).
Каждое сообщение поступает в очередь, где хранится до тех пор, пока кто-нибудь не прочитает его. После прочтения сообщение удаляется из очереди сообщений. Следовательно, только один процесс может получить конкретное сообщение.
Сообщение может быть помечено целочисленным значением (типом сообщения), которое позволяет процессу избирательно извлекать сообщения из очереди. Правила чтения по типам:
- если msgp равен нулю, то используется первое сообщение из очереди;
- если msgp больше нуля, то из очереди берется первое сообщение типа msgp (если только в параметре msgflg не выставлен флаг MSG_EXCEPT. В этом случае из очереди берется первое сообщение, тип которого не равен msgp).
если msgp меньше нуля, то из очереди берется первое сообщение со значением, меньшим, чем абсолютное значение msgp.
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h>
int msgget(key_t key, int msgflg); int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
struct msgbuf { long mtype; /* message type, must be > 0 / char mtext[1]; / message data */ };
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
Семафоры
Каждый семафор IPC представляет собой набор из одного или нескольких целочисленных счётчиков. Таким образом один семафор может защищать несколько объектов. Обычно, нулевое значение счётчика означает, что объект свободен, положительное - занят, но можно договориться о других значениях. Механизм семафоров ничего не знает про их использование, а только обеспечивает атомарные операции изменения значений.
Существуют ограничения как на количество семафоров (по умолчанию 128), так и на количество счётчиков внутри одного семафора (по умолчанию 250). Эти данные в Linux доступны в /proc/sys/kernel/sem.
При завершении процесса все операции, которые он проводил над семафорами сбрасываются, что позволяет избежать неприятностей в случае краха процесса, изменившего значения счётчиков.
Операции над семафорами в вызове semop():
- Если величина sembuf[n].semop положительна, то текущее значение счётчика n увеличивается на эту величину.
- Если значение sembuf[n].semop равно нулю, процесс ожидает, пока счётчик n не обнулится.
Если величина sembuf[n].semop отрицательна, процесс ожидает, пока значение счётчика n не станет большим или равным абсолютной величине sembuf.semop. Затем абсолютная величина sembuf[n].semop вычитается из значения счётчика n.
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h>
int semget(key_t key, int nsems, int semflg); int semop(int semid, struct sembuf *sops, unsigned nsops);
struct sembuf { unsigned short sem_num; /* semaphore number / short sem_op; / semaphore operation / short sem_flg; / operation flags */ }
int semctl(int semid, int semnum, int cmd, ...);
Общая память
Вызов shmget() резервирует участок физической памяти (фала подкачки)
Вызов shmat() (attach) отображает зарезервированный участок физической памяти в виртуальное адресное пространство процесса.
Вызов shmdt() (detach) разрывает связь между зарезервированным участок физической памяти и виртуальным адресным пространством процесса.
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
void *shmat(int shmid, const void *shmaddr, int shmflg);
int shmdt(const void *shmaddr);
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
Утилиты командной строки
Просмотр информации о подсистеме System V IPC
lsipc
Создание объекта
# Допустимые опции
# -Q - создание очереди
# -M size - создание разделяемой памяти
# -S number - создание семафора
ipcmk -Q
Просмотр объектов
ipcs
Удаление объектов
ipcrm --shmem-id 9601039
ipcrm --all
Сокеты
Сокет - универсальный интерфейс для создания каналов для межпроцессного взаимодействия.
Сокеты объединили в едином интерфейсе потоковую передачу данных подобную каналам pipe и FIFO и передачу сообщений, подобную очередям сообщений в System V IPC. Кроме того, сокеты добавили возможность создания клиент-серверного взаимодействия (один со многими).
Интерфейс сокетов скрывает механизм передачи данных между процессами. В качестве нижележащего транспорта могут использоваться как внутренний транспорт в ядре Unix, так и практически любые сетевые протоколы. Для достижения такой гибкости используется перегруженная функция назначения сокету имени - bind(). Данная функция принимает в качестве параметров идентификатор пространства имён и указатель на структуру, которая содержит имя в соответствующем формате. Это могут быть имена в файловой системе Unix, IP адрес + порт в TCP/UDP, MAC-адрес сетевой карты в протоколе IPX.
Классификация сокетов
Stream
Поток байтов без разделения на записи, подобный чтению-записи в файл или каналам в Unix. Процесс, читающий из сокета, не знает, какими порциями производилась запись в сокет пишущим процессом. Данные никогда не теряются и не перемешиваются.
- Непрерывный поток байтов
- Упорядоченный приём данных
- Надёжная доставка данных
Datagram
Передача записей ограниченной длины. Записи на уровне интерфейса сокетов никак не связанны между собой. Отправка записей описывается фразой: "отправил и забыл". Принимающий процесс получает записи по отдельности в непредсказуемом порядке или не получает вовсе.
- Деление потока данных на отдельные записи
- Неупорядоченный приём записей
- Возможна потеря записей
Sequential packets
Надёжная упорядоченная передача с делением на записи. Использовался в Sequence Packet Protocol для Xerox Network Systems. Не реализован в TCP/IP, но может быть имитирован в TCP через Urgent Pointer.
- Деление потока данных на отдельные записи
- Упорядоченная передача данных
- Надёжная доставка данных
Raw
Данный тип сокетов предназначен для управление нижележащим сетевым драйвером. В Unix требует администраторских полномочий. Примером использования Raw-сокета является программа ping, которая отправляет и принимает управляющие пакеты управления сетью - ICMP. Файл /usr/bin/ping в старых версиях Linux имел флаг смены полномочий suid, а в новых версиях - флаги дополнительных полномочий - cap_net_admin и cap_net_raw.
Имена сокетов
Имена сокетов на сервере назначаются вызовом bind(), а на клиенте, как правило, генерируются ядром.
- Inet - сокеты именуются с помощью IP адресов и номеров портов
- Unix - сокетам даются имена объектов типа socket в файловой системе
- IPX - имена на основе MAC-адресов сетевых карт
- ... - возможны и другие варианты
TCP/IP
Для передачи данных с помощью семействе протоколов TCP/IP реализованы два вида сокетов Stream и Datagram. Все остальные манипуляции с сетью TCP/IP осуществляются через Raw-сокеты.
- TCP = Stream
- UDP = Datagram
- ICMP = RAW
- Sequential packets - были экспериментальные реализации в 1990-х, которые не вышли за рамки научных исследований
API Сокетов
Создание сокета
#include <sys/types.h>
#include <sys/socket.h>
int s = socket(int domain, int type, int protocol);
domain - семейство протоколов, которое будет использоваться для передачи данных. Имена макросов, задающих домен, начинаются с PF - protocol family/
- PF_UNIX - внутреннее межпроцессное взаимодействие
- PF_INET - стек TCP/IP
type - тип сокета
- SOCK_DGRAM - ненадежная передача данных с сохранением границ сообщений (соответствует протоколу UDP),
- SOCK_STREAM - надежная передача данных без сохранения границ сообщений (соответствует протоколу TCP),
- SOCK_SEQ - надежная передача данных с сохранением границ сообщений (в стеке TCP/IP не поддерживается),
- SOCK_RAW - низкоуровневый доступ к протоколу (уровень IP, ICMP).
protocol Поскольку в семействе протоколов TCP/IP протокол однозначно связан с типом сокета, а в домене Unix понятие протокола вообще отсутствует, то этот параметр всегда равен нулю, что соответствует автовыбору.
В домене Unix возможно создание пары соединённых между собой безымянных сокетов, которые буду вести себя подобно неименованному каналу pipe. В отличие от неименованных каналов, оба сокета открыты и на чтение и на запись.
int result;
int sockfd[2];
result=socketpair(AF_UNIX, SOCK_STREAM, 0, sockfd);
Назначение имени
Для того, чтобы клиенты могли подключаться к серверу, сервер должен иметь заранее известное имя. Вызов bind() обеспечивает назначение имени серверному сокету. Сервер получит имя клиентского сокета в момент соединения (stream) или получения сообщения (datagram), поэтому на клиентской стороне имя сокету, как правило, назначается ядром ОС, хотя и явное присвоение с помощью bind() остаётся доступным.
#include <sys/types.h>
#include <sys/socket.h>
int bind(int sockfd, struct sockaddr *localaddr, int addrlen);
Второй параметр функции bind() - адрес - формально описан как указатель на структуру sockaddr с удобным размером 16 байт. sockaddr можно рассматривать как суперкласс (без методов) от которого наследуются реально используемые классы sockaddr_un, sockaddr_in и т.д. Все они наследуют поле sa_family - тип адреса, благодаря которому bind() корректно интерпретирует переданную ему структуру данных. Для того, чтобы избежать предупреждений компилятора, рекомендуется явно преобразовывать тип второго параметра к struct sockaddr *.
Макросы, которые присваиваются полю sa_family по своему числовому значению совпадают с соответствующими макросами определяющими семейство протоколов, но начинаются с AF - address family.
struct sockaddr {
u_short sa_family;
char sa_data[14];
};
Имя в домене Unix - строка с именем сокета в файловой системе.
struct sockaddr_un {
short sun_family; /* AF_UNIX */
char sun_path[108];
};
Имя в домене Internet - IP-адрес и номер порта, которые хранятся в виде целых числе в формате BIG ENDIAN. Для заполнения структуры они должны быть преобразованы из локального представления в сетевое функциями htonl() и htons() для длинных и коротких целых соответственно. Упаковка IP-адреса в дополнительную структуру связана, скорее всего, с какими-то историческими причинами.
struct sockaddr_in {
short sin_family; /* AF_INET */
u_short sin_port; /* Port Number */
struct in_addr sin_addr;/* Internet address */
char sin_zero[8]; /*Not used*/
}
struct in_addr {
unsigned long int s_addr;
}
Соединение с сервером (в основном Stream)
Для сокета типа Stream вызов connect() соединяет сокет клиента с сокетом сервера, создавая поток передачи данных. Адрес сервера servaddr заполняется по тем же правилам, что и адрес, передаваемый в bind().
Для сокета типа Datagram вызов connect() запоминает адрес получателя, для отправки сообщений вызовом send(). Можно пропустить этот вызов и отправлять сообщения вызовом sendto(), явно указывая адрес получателя для каждого сообщения.
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sockfd, struct sockaddr *servaddr, int addrlen);
Прослушивание сокетов сервером (только Stream)
Вызов listen() на стороне сервера превращает сокет в фабрику сокетов, которая будет с помощью вызова accept() возвращать новый транспортный сокет на каждый вызов connect() со стороны клиентов.
#include <sys/types.h>
#include <sys/socket.h>
int listen(int sockfd, int backlog);
backlog - количество запросов клиентов connect(), которые будут храниться в очереди ожидания, пока сервер не вызовет accept().
Обработка запроса клиента.
Клиентский connect() будет заблокирован до тех пор, пока сервер не вызовет accept(). accept() возвращает транспортный сокет, который связан с сокетом для которого клиент вызвал connect(). Этот сокет используется как файловый дескриптор для вызовов read(), write(), send() и recv().
В переменную clntaddr заносится адрес подключившегося клиента.
#include <sys/types.h>
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *clntaddr, int *addrlen);
Чтение/запись данных
Для операций чтения-записи данных через сокеты могут применяться стандартные вызовы read() и write(), однако существуют и более специализированные вызовы:
#include <sys/types.h>
#include <sys/socket.h>
ssize_t write(int fildes, const void *buf, size_t nbyte);
ssize_t send(int sockfd, const char *msg, int len, int flags);
ssize_t sendto(int sockfd, const char *msg, int len, int flags,const struct sockaddr *toaddr, int tolen) ;
ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags);
ssize_t read(int fildes, const void *buf, size_t nbyte);
ssize_t recv(int sockfd, char *buf, int len, int flags);
ssize_t recvfrom(int sockfd, char *buf, int len, int flags, struct sockaddr *fromaddr, int *fromlen);
ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);
Все вызовы применимы и к потоковым сокетам и к сокетам датаграмм. При попытке прочитать датаграмму в слишком маленький буфер, её хвост будет утерян.
write(fd,buf,size) == send(fd,buf,size,0) == sendto(fd,buf,size,0,NULL,0)
send() может применяться только к тем сокетам, для которых выполнен connect().
При использовании sendto() с потоковым сокетом адрес toaddr игнорируется если был выполнен connect(). Если же connect() не был выполнен - в errno возвращается ошибка ENOTCONN.
sendmsg() и recvmsg() близки к вызовам writev() и readv(), поскольку позволяют одним вызовом отправить/принять несколько буферов данных.
Флаги send():
- MSG_DONTWAIT - неблокирующая отправка. В случае невозможности отправить порцию данных возвращается -1, а переменная errno выставляется в EAGAIN.
- MSG_OOB - отправка внеочередных данных (out-of-band) если они поддерживаются протоколом
Флаги recv():
- MSG_DONTWAIT - неблокирующее чтение
- MSG_OOB - приём внеочередных данных
- MSG_PEEK - "подглядывание" - чтение данных без удаления их из канала
Управление окончанием соединения (в основном Stream)
Вызов close() закрывает сокет и освобождает все связанные с ним структуры данных.
Для контроля над закрытием потоковых сокетов используется вызов shutdown(), который позволяет управлять окончанием соединения.
int shutdown () (int sock, int cntl);
Аргумент cntl может принимать следующие значения:
- 0: больше нельзя получать данные из сокета;
- 1: больше нельзя посылать данные в сокет;
- 2: больше нельзя ни посылать, ни принимать данные через этот сокет.
Асинхронные операции - select
Для реализации клиент-серверной архитектуры на основе сокетов необходимо предоставить разработчику сервера инструмент для параллельной работы с несколькими клиентами. Возможные варианты:
- создание нового процесса для каждого клиента. Плохо масштабируется, поскольку требует дополнительных ресурсов на создание и последующее планирование процессов. Нити масштабируются лучше, но в ранних реализациях Unix они отсутствовали.
- вызов callbackов при поступлении данных от пользователя - в Unix не реализовано
- бесконечный цикл с попытками неблокирующего чтения-записи. Занимает процессорное время.
- блокирующая операция, ожидающая появления сокетов, доступных для чтения-записи.
Последний вариант является наиболее часто используемым в Unix и реализуется вызовами select() и poll().
Вызовы отличаются по формату параметров, но эквивалентны по своему назначению. Они приостанавливают выполнение процесса, до появления данных от клиента, появления возможности отправить данные клиенту, появления ошибки приёма-передачи или до истечения таймаута. Если точнее, то для операций чтения-записи проверяется, что они не будут заблокированы.
Реализация этих вызовов позволяет использовать их для отслеживания состояния любых файловых дескрипторов, а не только сокетов.
SELECT
Вызов select() получает три битовых набора флагов (чтение, запись, ошибка) размером с максимальное доступное число открытых файловых дескрипторов. Флаг в какой-то позиции означает что мы наблюдаем за соответствующим файловым дескриптором.
Параметр nfds задает номер максимального выставленного флага и служит для оптимизации.
#include <sys/select.h>
int select(int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
Для манипуляции флагами используется следующие функции, которые позволяют очистить набор флагов, установить флаг, сбросить флаг, проверить состояние флага:
void FD_ZERO(fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
При изменении состояния каких-либо интересующего нас файловых дескрипторов select() сбрасывает все флаги и выставляет те, которые обозначают, какие события и на каких файловых дескрипторах произошли. Возвращается значение, указывающее сколько флагов возвращено. Если событий не было и возврат из select() произошёл по таймауту, все наборы флагов обнуляются и возвращается ноль.
В случае ошибки возвращается -1. Значение флагов не определено.
Таймаут задаётся структурой timeval, содержащей секунды и микросекунды
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
Поскольку вызов sleep() работает с точностью до секунды, то для приостановки процесса на более короткие промежутки времени часто используют select() с указателями NULL вместо указателей на флаги.
POLL
Вызов poll() функционально эквивалентен select. Его параметры как бы "вывернуты наизнанку" по сравнению с select(). Вместо трёх наборов битовых файлов в poll() массив интересующих файловых дескрипторов размером nfds. С каждым файловым дескриптором связаны две переменные: флаги интересующих событий и флаги случившихся событий. Время таймаута задаётся в миллисекундах.
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
Структура pollfd
struct pollfd { int fd; /* file descriptor / short events; / requested events / short revents; / returned events */ };
Битовые флаги в events определяются макросами:
#define POLLIN 0x0001 /* Можно считывать данные */
#define POLLPRI 0x0002 /* Есть срочные данные */
#define POLLOUT 0x0004 /* Запись не будет блокирована */
#define POLLERR 0x0008 /* Произошла ошибка */
#define POLLHUP 0x0010 /* Обрыв связи */
#define POLLNVAL 0x0020 /* Неверный запрос: fd не открыт */
Диаграмма взаимодействия сокетов datagram
Ниже представлена временная диаграмма соединения клиента и сервера через сокет типа Datagram
| Сервер | Клиент | |
|---|---|---|
| Создание сокета socket() | Создание сокета socket() | |
| Присвоение имени bind() | ||
| Начало цикла работы с клиентами | ||
| Прием сообщения с адресом отправителя recvfrom() | <= | Отправка сообщения по адресу sendto() |
| Извлечение адреса клиента из ответа recvfrom() | ||
| Отправка сообщения по адресу sendto() | => | Приём сообщения recv() |
| Закрытие сокета close() | ||
| Конец цикла работы с клиентами | ||
| Закрытие сокета close() |
Диаграмма взаимодействия сокетов stream
Ниже представлена временная диаграмма соединения клиента и сервера через сокет типа Stream
| Сервер | Клиент | |
|---|---|---|
| Создание сокета socket() | Создание сокета socket() | |
| Присвоение имени bind() | ||
| Создание очереди запросов listen() | ||
| Начало цикла работы с клиентами | ||
| Выбор соединения из очереди accept() | <= | Установка соединения connect() |
| read() | <= | write() |
| write() | => | read() |
| Закрытие транспортного сокета close() | Закрытие сокета close() | |
| Конец цикла работы с клиентами |