Инструменты программиста
Опции компиляторов
Компилятор G77
Компилятор G77 (GNU Fortran )основан на стандарте ANSI Fortran 77, но он включает в себя многие особенности, определенные в стандартах Fotran 90 и Fortran 95.
Синтаксис команды:
g77 [-c?-S?-E]
[-g] [-pg] [-Olevel]
[-Wwarn...] [-pedantic]
[-Idir...] [-Ldir...]
[-Dmacro[=defn]...] [-Umacro]
[-foption...] [-mmachine-option...]
[-o outfile] infile...
Все опции поддерживаемые gcc поддерживаются и g77. Компиляторы С и g77 интегрированы.
Обращение:
g77 [option | filename]...Исходные файлы:
source.f, source.for, source.FOR Значение некоторых опций:
| -c | создать только объектный файл (source.o) из исходного ( source.f, .source.for, source.FOR ) |
| -o file | создать загрузочный файл с именем file (по умолчанию создается файл с именем a.out) |
| -llibrary | использовать библиотеку liblibrary.a при редактировании связей |
| -Idir | добавить каталог dir в список поиска каталогов, содержащих include- файлы |
| -Ldir | добавить директорию dir в список поиска библиотек |
| -O | включить оптимизацию |
| -g | создать отладочную информацию для работы с отладчиком |
Для получения полного описания g77 следует смотреть документацию по GNU Fortran. Об опциях g77 можно также получить информацию с помощью команд:
info g77man g77
Компилятор GCC
GСС - это свободно доступный оптимизирующий компилятор для языков C, C++.
Программа gcc, запускаемая из командной строки, представяляет собой надстройку над группой компиляторов. В зависимости от расширений имен файлов, передаваемых в качестве параметров, и дополнительных опций, gcc запускает необходимые препроцессоры, компиляторы, линкеры.
Файлы с расширением .cc или .C рассматриваются, как файлы на языке C++, файлы с расширением .c как программы на языке C, а файлы c расширением .o считаются объектными.
Чтобы откомпилировать исходный код C++, находящийся в файле F.cc, и создать объектный файл F.o, необходимо выполнить команду:
gcc -c F.cc
Опция –c означает «только компиляция».
Чтобы скомпоновать один или несколько объектных файлов, полученных из исходного кода - F1.o, F2.o, ... - в единый исполняемый файл F, необходимо ввести команду:
gcc -o F F1.o F2.o
Опция -o задает имя исполняемого файла.
Можно совместить два этапа обработки - компиляцию и компоновку - в один общий этап с помощью команды:
gcc -o F <compile-and-link-options> F1.cc ... -lg++ <other-libraries><compile-and-link –options> - возможные дополнительные опции компиляции и компоновки. Опция –lg++ указывает на необходимость подключить стандартную библиотеку языка С++, <other-libraries> - возможные дополнительные библиотеки.
После компоновки будет создан исполняемый файл F, который можно запустить с помощью команды
./F <arguments> <arguments> - список аргументов командной строки Вашей программы.
В процессе компоновки очень часто приходится использовать библиотеки. Библиотекой называют набор объектных файлов, сгруппированных в единый файл и проиндексированных. Когда команда компоновки обнаруживает некоторую библиотеку в списке объектных файлов для компоновки, она проверяет, содержат ли уже скомпонованные объектные файлы вызовы для функций, определенных в одном из файлов библиотек. Если такие функции найдены, соответствующие вызовы связываются с кодом объектного файла из библиотеки. Библиотеки могут быть подключены с помощью опции вида -lname. В этом случае в стандартных каталогах, таких как /lib , /usr/lib, /usr/local/lib будет проведен поиск библиотеки в файле с именем libname.a. Библиотеки должны быть перечислены после исходных или объектных файлов, содержащих вызовы к соответствующим функциям.
Опции компиляции
Среди множества опций компиляции и компоновки наиболее часто употребляются следующие:
| Опция | Назначение |
| -c | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы в виде name.o. Компоновка не производится. |
| -Dname=value | Определить имя name в компилируемой программе, как значение value. Эффект такой же, как наличие строки #define name value в начале программы. Часть =value может быть опущена, в этом случае значение по умолчанию равно 1. |
| -o file-name | Использовать file-name в качестве имени для создаваемого файла. |
| -lname | Использовать при компоновке библиотеку libname.so |
| -Llib-path -Iinclude-path |
Добавить к стандартным каталогам поиска библиотек и заголовочных файлов пути lib-path и include-path соответственно. |
| -g | Поместить в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки. В сочетании –g рекомендуется использовать опцию отключения оптимизации –O0 (см.ниже) |
| -MM | Вывести зависимости от заголовочных файлов , используемых в Си или С++ программе, в формате, подходящем для утилиты make. Объектные или исполняемые файлы не создаются. |
| -pg | Поместить в объектный или исполняемый файл инструкции профилирования для генерации информации, используемой утилитой gprof. Опция должна быть указана и для компиляции, и для компоновки. Собранная с опцией -pg программа при запуске генерирует файл статистики. Программа gprof на основе этого файла создает расшифровку, указывающую время, потраченное на выполнение каждой функции. |
| -Wall | Вывод сообщений о всех предупреждениях или ошибках, возникающих во время компиляции программы. |
| -O1 -O2 -O3 |
Различные уровни оптимизации. |
| -O0 | Не оптимизировать. Если вы используете многочисленные -O опции с номерами или без номеров уровня, действительной является последняя такая опция. |
| -I | Используется для добавления ваших собственных каталогов для поиска заголовочных файлов в процессе сборки |
| -L | Передается компоновщику. Используется для добавления ваших собственных каталогов для поиска библиотек в процессе сборки. |
| -l | Передается компоновщику. Используется для добавления ваших собственных библиотек для поиска в процессе сборки. |
Компилятор GFortran
GFortran - это название компилятора языка программирования Фортран, входящего в коллекцию компиляторов GNU.
Сборка FORTRAN-программы:
Синтаксис
gfortran [-c?-S?-E]
[-g] [-pg] [-Olevel]
[-Wwarn...] [-pedantic]
[-Idir...] [-Ldir...]
[-Dmacro[=defn]...] [-Umacro]
[-foption...]
[-mmachine-option...]
[-o outfile] infile...GFortran опирается на GCC, и, следовательно, разделяет большинство его характеристик. В частности, параметры для оптимизации и генерации отладочной информации у них совпадают.
GFortran используется для компиляции исходного файла, source.f90, в объектный файл, object.o или исполняемый файл, executable. Одновременно он генерирует модуль файлов описания встречающихся модулей, так называемый nameofmodule.mod.
Для компиляции исходного файла source.f90, можно запустить: gfortran source.f90
Выходной файл будет автоматически имени source.o. Это объектный файл, который не может быть исполнен. После того как вы собрали некоторые исходные файлы, вы можете соединить их вместе с необходимыми библиотеками для создания исполняемого файла. Это делается следующим образом: gfortran -o executable object1.o object2.o..., где исполняемым будет executable, objectX.o - объектные файлы, которые могут быть созданы, как указано выше, или в равной степени другими компиляторами из источников в другом языке. Если опущено имя исполняемого файла, то исполняемый файл будет с названием a.out. Исполняемый файл может быть выполнен, как и в любой другой программе. Можно также пропустить отдельный этап компиляции и ввести такую команду: gfortran o executable source1.f90 source2.f90, которая будет осуществлять сбор исходных файлов source1.f90 и source2.f90, связь и создаст исполняемый файл. Вы также можете поместить объектные файлы в этой командной строке, они будут автоматически присоединены.
Опции компилятора GFortran
| Опция | Назначение |
| -c | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы в виде name.o. Компоновка не производится. |
| -Dname=value | Определить имя name в компилируемой программе, как значение value. Эффект такой же, как наличие строки #define name value в начале программы. Часть =value может быть опущена, в этом случае значение по умолчанию равно 1. |
| -o file-name | Использовать file-name в качестве имени для создаваемого файла. |
| -lname | Использовать при компоновке библиотеку libname.so |
| -Llib-path -Iinclude-path |
Добавить к стандартным каталогам поиска библиотек и заголовочных файлов пути lib-path и include-path соответственно. |
| -g | Поместить в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки. В сочетании –g рекомендуется использовать опцию отключения оптимизации –O0 (см.ниже) |
| -MM | Вывести зависимости от заголовочных файлов , используемых в Си или С++ программе, в формате, подходящем для утилиты make. Объектные или исполняемые файлы не создаются. |
| -pg | Поместить в объектный или исполняемый файл инструкции профилирования для генерации информации, используемой утилитой gprof. Опция должна быть указана и для компиляции, и для компоновки. Собранная с опцией -pg программа при запуске генерирует файл статистики. Программа gprof на основе этого файла создает расшифровку, указывающую время, потраченное на выполнение каждой функции. |
| -Wall | Вывод сообщений о всех предупреждениях или ошибках, возникающих во время компиляции программы. |
| -O1 -O2 -O3 |
Различные уровни оптимизации. |
| -O0 | Не оптимизировать. Если вы используете многочисленные -O опции с номерами или без номеров уровня, действительной является последняя такая опция. |
| -I | Использует для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки |
| -L | Передает компоновщику. Использует для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Использует для добавления ваших собственных библиотек поиска в процессе сборки. |
Компилятор PGCC
Компилятор Portland Group C (PGCC).
Компилятор PGCC для процессоров AMD64 и IA32/EM64T производит компиляцию программ C и линкует согласно опциям в командной строке.
Синтаксис команды:
pgcc [ -параметры ]... sourcefile...
- Параметры могут отсутствовать или содержать опции копилятора
- Суффиксы
sourcefileуказывают на вид файла:
.c - файл на C; обрабатывается препроцессором перед компиляцией; компилируется
.i - файл на C после обработки препроцессора; компилируется
.s - ассемблерный файл; передаётся ассемблеру
.S - ассемблерный файл; обрабатывается препроцессором; передаётся ассемблеру
.o -объектный файл; передаётся компоновщику
.a - библиотечный файл; передаётся компоновщику
Полный список опций компилятора можно посмотреть по команде man pgcc.
Некоторые важные опции компиляции для PGCC приведены ниже:
| Опция | Назначение |
| -с | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы. |
| -C | Включает проверки выхода индекса за границы массива |
| -O0 | Отключает оптимизацию. |
| -О1 | Оптимизация по размеру. Не использует методов оптимизации, которые могут увеличить размер кода. Создает в большинстве случаев самый маленький размер кода. |
| -O2 или -O | Оптимизация устанавливаемая по умолчанию. |
| -O3 | Задействует методы оптимизации из -O2 и, дополнительно, более агрессивные методы оптимизации, которые подходят не для всех программ. |
| -Os | Включает оптимизацию по скорости, но при этом отключает некоторые оптимизации, которые могут привести к увеличению размеров кода при незначительном выигрыше в скорости. |
| -fast | Включает в себя -O2 и ряд других опций, таких как использование векторизации с поддержкой SSE инструкций. Использование -fast понижает точность вычислений. |
| -g | Включает информацию об отладке. |
| -fastsse | То же самое что и -fast -Mipa=fast - включает межпроцедурный анализ. |
| -I | Использует для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки. |
| -L | Передает компоновщику. Использует для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Использует для добавления ваших собственных библиотек поиска в процессе сборки. |
Компилятор PGFortran
Компилятор The Portland Group Inc. Fortran (PGFortran).
Компилятор PGFortran для процессоров AMD64 и IA32/EM64T производит компиляцию программ на Фортране и линкует согласно опциям в командной строке. PGFortran является интерфейсом для компиляторов pgf90 и pgf95.
Синтаксис команды:
pgfortran [ -параметры ]... sourcefile...- Параметры могут отсутствовать или содержать опции копилятора
- Суффиксы
sourcefileуказывают на вид файла:
.f - файл на Фортране с фиксированным форматом; компилируется
.F - файл на Фортране с фиксированным форматом; после обработки препроцессором - компилируется
.f90 - файл на Фортране в свободном формате; компилируется
.F90 - файл на Фортране в свободном формате; после обработки препроцессором - компилируется
.f95 - файл на Фортране в свободном формате; компилируется
.F95 - файл на Фортране в свободном формате; после обработки препроцессором - компилируется
.for - файл на Фортране с фиксированным форматом; компилируется
.FOR - файл на Фортране с фиксированным форматом; после обработки препроцессором - компилируется
.fpp - файл на Фортране с фиксированным форматом; после обработки препроцессором - компилируется
.s - ассемблерный файл; передаётся ассемблеру
.S - ассемблерный файл; обрабатывается препроцессором; передаётся ассемблеру
.o - объектный файл; передаётся компоновщику
.a - библиотечный файл; передаётся компоновщику
Полный список опций компилятора можно посмотреть по команде man pgfortran.
Некоторые важные опции компиляции для PGFortran приведены здесь.
Опции компилятора PGFortran
| Опция | Назначение |
| -o file |
Использует file как имя выходного исполняемого файла программы, вместо имени по умолчанию - a.out. Если используется совместно с опцией -с или -S и с одним входным файлом, то file используется в качестве имени объектного или ассемблерного выходного файла. |
| -S |
Пропускает этапы ассемблирования и линкования. Для каждого файла с именем, например, file.f создает при выходе из компиляции файл с именем file.s . См. также -о. |
| -fastsse |
Выбирает основные оптимальные установки для процессора, который поддерживает SSE инструкции (Pentium 3 / 4, AthlonXP / MP, Opteron) и SSE2 (Pentium 4, Opteron). Используйте в pgf90 -fastsse -help чтобы просмотреть установки. |
| -C | Включает проверки выхода индекса за границы массива также как и -Mbounds |
| -i2 | Целые и логические переменные длиной 2 байта . |
| -i4 | Целые и логические переменные длиной 4 байта . |
| -i8 | Целые и логические переменные длиной 8 байт . Устанавливается по умолчанию. Для операций над целыми числами отводится 64 бита. |
| -O[N] | Устанавливает уровень оптимизации равным N. -O0 до -O4, по умолчанию устанавливается -O2. Если не указана опция -O и если не заказана -g, то устанавливается -O1 , но если заказана -g, то устанавливается -O0. Когда номер у -O не указан, то устанавливается -O2. |
| -O0 | Без оптимизации. |
| -О1 |
Оптимизация в рамках основных блоков. Выполняется некоторое распределение регистров. Глобальная оптимизация не выполняется. |
| -O2 | Выполняется оптимизация -O1. Кроме того, выполняются традиционные скалярные оптимизации, такие как признание индукции и инвариант цикла движения глобального оптимизатора. |
| -O3 |
Задействует методы оптимизации из -O1 и -O2 и, дополнительно, более агрессивные методы оптимизации циклов и доступа к памяти, такие как подстановка скаляров, раскрутка циклов. Эти агрессивные методы оптимизации могут, в ряде случаев, и замедлить работу приложений . |
| -O4 | Выполняет все уровни оптимизации -O1,-O2, -O3, кроме того, выполняет оптимизацию выражений с плавающей точкой. |
| -fpic |
Передаёт компилятору для генерации позиционно-независимого кода, который может быть использован при создании общих объектных файлов (динамически связываемых библиотек). |
| -gopt |
Сообщает компоновщику включение отладочной информации без отключения оптимизации |
| -s |
Использует линковщик; таблицы символьной информации, оптимизации. Использование может привести к неожиданным результатам при отладке с оптимизацией, она предназначена для использования с другими опциями , которые используют отладочную информацию. |
| -pg | Устанавливает профилирование; влечёт установку -Mframe |
| -r4 | Переменные DOUBLE PRECISION рассматриваются как REAL. |
| -r8 | Переменные REAL рассматриваются как DOUBLE PRECISION . Это тоже самое, что и указать -Mr8 и -Mr8intrinsics. |
| -fast | Обеспечивает ускоренный метод нескольких оптимизаций на время выполнения программы. Устанавливает параметры для повышения производительности в размере не менее 2, см.-O. Используйте pgf90 -fast -help для просмотра эквивалентных переключателей. |
| -g | Создаёт отладочную информацию. Опция устанавливает уровень оптимизации до нуля, если только заказана опция -O . Процесс может привести к неожиданным результатам, если заказан уровень оптимизации отличный от нуля. Сгенерированный код будет работать медленнее при -O0, чем при других уровнях оптимизации. |
| -I | Добавляет ваши собственные каталоги поиска заголовочных файлов в процессе сборки |
| -L | Передает компоновщику. Добавляет ваши собственные каталоги поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Добавляет ваши собственные библиотеки поиска в процессе сборки. |
Опции компилятора ICC
icc -команда для вызова компилятора Intel(R) (C или C++).
Синтаксис команды:
icc [параметры] file1 [file2] ...
- параметры могут отсутствовать или содержать опции компилятора
fileN– это файлы на языке C или C++, сборочные файлы, объектные файлы, библиотеки объектов или другие линкуемые файлы
Полный список опций можно посмотреть по команде man icc .
Некоторые важные опции компиляции для ICC приведены ниже:
| Опция | Назначение |
| -с | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы. |
| -C | Включает проверки выхода индекса за границы массива. |
| -O0 | Отключает оптимизацию. |
| -О1 | Оптимизация по размеру. Не использует методов оптимизации, которые могут увеличить размер кода. Создает в большинстве случаев самый маленький размер кода. |
| -O2 или -O | Оптимизация устанавливаемая по умолчанию. |
| -O3 | Задействует методы оптимизации из -O2 и, дополнительно, более агрессивные методы оптимизации, которые подходят не для всех программ. |
| -Os | Включает оптимизацию по скорости, но при этом отключает некоторые оптимизации, которые могут привести к увеличению размеров кода при незначительном выигрыше в скорости. |
| -fast | Обеспечивает ускоренный метод для нескольких оптимизаций на время выполнения программы. Устанавливает -xT -O3 -ipo -no-prec-div -static параметры для повышения производительности: • -O3 (см. выше) • -ipo (включает межпроцедурную оптимизацию между файлами) • -static (предотвращает линкование с общими библиотеками). Параметры задаются списком и не могут быть заданы по отдельности. |
| -g | Включает информацию об отладке. |
| -I | Используется для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки. |
| -L | Передается компоновщику. Используется для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передается компоновщику. Используется для добавления ваших собственных библиотек в процессе сборки. |
Опции компилятора Intel Fortran
ifort -команда для вызова компилятора Intel(R) Fortran.
Синтаксис команды:
ifort [параметры] file1 [file2] ...- параметры могут отсутствовать или содержать опции компилятора
fileN– это файлы на языке Fortran, сборочные файлы, объектные файлы, библиотеки объектов или другие линкуемые файлы
Полный список опций можно посмотреть по команде man ifort .
Команда ifort интерпретирует входные файлы по суффиксу имени файла следующим образом:
Имена файлов с суффиксом .f90 интерпретируются как файлы в свободной форме записи на Fortran 95/90.
Имена файлов с суффиксом .f, .for или .ftn интерпретируются как фиксированная форма записи для Fortran 66/77 файлов.
В Fortran 90/95, наряду с фиксированным форматом исходного текста программы, разрешен свободный формат. Свободный формат допускает помещение более одного оператора в строке, при этом в качестве разделителя используется точка с запятой. Признак продолжения оператора на строку продолжения - символ & - указывается в конце той строки, которую надо продолжить. Комментарии записываются после символа восклицательный знак в начале строки или в любой позиции строки после оператора. В свободном формате пробелы являются значащими.
Некоторые важные опции компиляции для Intel Fortran приведены ниже:
| Опция | Назначение |
| -free | Указывает, что исходные файлы находятся в свободном формате. По умолчанию, формат исходного файла определяется суффиксом файла |
| -fixed | Указывает, что исходные файлы находятся в фиксированном формате. По умолчанию, формат исходного файла определяется суффиксом файла |
| -с | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы |
| -C | Включает проверки выхода индекса за границы массива |
| -i2 | Целые и логические переменные длиной 2 байта (тоже, что и опция -integer-size 16). По умолчанию целочисленный размер равен 32 разряда. |
| -i4 | Целые и логические переменные длиной 4 байта (тоже, что и опция -integer-size 32 ). Это значение устанавливается по умолчанию. |
| -i8 | Целые и логические переменные 8 байт (тоже , что и опция -integer-size 64). По умолчанию целочисленный размер равен 32 разряда. |
| -O0 | Отключает оптимизацию |
| -О1 | Оптимизация по размеру. Не использует методов оптимизации, которые могут увеличить размер кода. Создает в большинстве случаев самый маленький размер кода. |
| -O2 или -O | Максимизация скорости. Как правило, создает более быстрый код, чем -O1. Эта опция устанавливается по умолчанию для оптимизации, если не указана -g |
| -O3 | Задействует методы оптимизации из -O2 и, дополнительно, более агрессивные методы оптимизации циклов и доступа к памяти, такие как подстановка скаляров, раскрутка циклов, подстановка кода для избегания ветвлений, блокирование циклов для обеспечения более эффективного использования кэш-памяти и, только на системах архитектуры IA-64, дополнительная подготовка данных. Данная опция особенно рекомендуется для приложений, где есть циклы, которые активно используют вычисления с плавающей точкой или обрабатывают большие порции данных. Эти агрессивные методы оптимизации могут в ряде случаев, и замедлить работу приложений других типов по сравнению с использованием -O2. |
| -OpenMP | Включает поддержку стандарта OpenMP 2.0 Распараллеливает программу. Позволяет параллелизацию для создания многопоточного кода на основе команд OpenMP. Этот опция может быть выполнена в параллельном режиме на однопроцессорных и многопроцессорных системах. OpenMP-опция работает как с-O0 (без оптимизации) и c любым уровнем оптимизации -O. Указание с-O0 помогает для отладки OpenMP приложений. |
| -OpenMP-stubs | Включает выполнение программ OpenMP в последовательном режиме. Директивы OpenMP игнорируются, если стоят заглушки (stubs) для OpenMP |
| -p | Порождает дополнительный код для записи профилирующей информации, подходящей для анализирующей программы PROF. Вы должны использовать эту опцию при компиляции исходного файла, о котором вы хотите получить информацию, и вы также должны использовать ее при линковке. |
| -parallel | Включает автоматическое распараллеливание циклов, для которых это безопасно. Чтобы использовать эту опцию, вы также должны указать-O2 и-O3. |
| -r8 | Вещественные и комплексные переменные длиной 8 байт. Переменные REAL рассматриваются как DOUBLE PRECISION (REAL(KIND=8)) и комплексные рассматриваются в качестве DOUBLE COMPLEX (COMPLEX(KIND=8)). Это тоже самое, что и указать -real-size 64 или -autodouble. |
| -r16 | Вещественные и комплексные переменные длиной 16 байт. Переменные REAL рассматриваются как REAL (REAL(KIND=16), COMPLEX и DOUBLE COMPLEX рассматривается как COMPLEX (COMPLEX(KIND=16)). Это тоже самое, что и указать -real-size 128. |
| -save | Сохраняет переменные, за исключением тех, которые объявлены, как AUTOMATIC, в статической памяти (тоже, что и noauto-noautomatic). По умолчанию используется –autoscalar, однако, если Вы укажите -recursive или -OpenMP, то по умолчанию используется AUTOMATIC |
| -stand | Заставляет компилятор выдавать сообщения компиляции для нестандартных элементов языка. |
| -fast | Обеспечивает ускоренный метод для нескольких оптимизаций на время выполнения программы. Устанавливает следующие параметры для повышения производительности: • -O3 • -ipo (включает межпроцедурную оптимизацию между файлами) • -static (предотвращает линкование с общими библиотеками). |
| -g | Помещает в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки. В сочетании –g рекомендуется использовать опцию отключения оптимизации –O0 |
| -check bounds | Выполняет динамическую проверку выхода индекса за границы массива. Проверка может увеличить время выполнения программы. |
| -I | Использует для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки |
| -L | Передает компоновщику. Использует для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Использует для добавления ваших собственных библиотек поиска в процессе сборки. |
Использование CUDA
Запуск задач на графических процессорах в системе SLURM задается опцией --gres=gpu:N, где N - число GPU.
Свежая версия библиотеки CUDA находится в каталоге /opt/cuda/.
/opt/cuda/include/ — заголовочные файлы;
/opt/cuda/lib /— библиотека CUDA;
/opt/cuda/doc/ — документация.
Чтобы использовать библиотеку CUDA, необходимо при компиляции программы заказать данную библиотеку, например:
gcc mytest.c -o mytest -lcuda -L/opt/cuda/lib -I/opt/cuda/includeМожно использовать компилятор nvcc:
nvcc <имя файла для компиляции> -o <имя выходного файла> На кластере "Уран" при выполнении данной команды по умолчанию подключается библиотека CUDA . Можно компилировать программы на языках C и C++ (файлы с расширением .c и .cpp) и программы, написанные с использованием технологии CUDA (файлы с расширением .cu), например:
u9999@umt:~$ nvcc main.c -o gputest
Пример
Пусть файл cuda_test.cu (из домашнего каталога) содержит программу на CUDA:
#include <cuda.h>
#include <stdio.h>
int main() {
int GPU_N;
int dev;
cudaGetDeviceCount(&GPU_N);
printf("Device count: %d\n", GPU_N);
for(dev=0;dev<GPU_N;dev++) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("PCI Bus id: %d\n",deviceProp.pciBusID);
}
return 0;
}Тогда компиляция программы и запуск задачи на кластере могут иметь вид:
u9999@umt:~$ nvcc cuda_test.cu -o cuda_test
u9999@umt:~$ srun --gres=gpu:1 ./cuda_test
Device count: 1
PCI Bus id: 8
u9999@umt:~$ srun --gres=gpu:2 ./cuda_test
Device count: 2
PCI Bus id: 10
PCI Bus id: 26
Поддержка CUDA есть в компиляторе Portland Group.
Инструкции по использованию CUDA в Фортране можно найти на сайте Portland Group (http://www.pgroup.com/resources/cudafortran.htm).
Для компиляции Fortran-программы с CUDA следует установить переменные окружения командой module или mpiset, выбрав связку MVAPICH+PGI, например:
module switch mpi/default mvapich2/pgi_12.10или соответственно
mpiset 7и откомпилировать программу компилятором pgfortran с опцией -Mcuda, указав при необходимости оптимизированные библиотеки, например:
pgfortran -o mytest test.cuf -Mcuda -lcublasСсылки на руководства по CUDA
Сообщество пользователей CUDA ВМК МГУ (выложены лекции в виде слайдов и есть активный форум, на котором можно задавать вопросы по CUDA. В работе форума активно участвуют сотрудники Nvidia)
https://sites.google.com/site/cudacsmsusu/home
CUDA zone: сборник приложений на CUDA, многие с документацией и исходными кодами
http://www.nvidia.ru/object/cuda_apps_flash_new_ru.html#state=home
Записи семинаров по CUDA:
a) введение в CUDA
http://www.gotdotnet.ru/blogs/parallel-computing/9966/
b) библиотеки с поддержкой CUDA
http://www.gotdotnet.ru/blogs/parallel-computing/10070/
c) отладка и профилировка CUDA приложений
http://www.gotdotnet.ru/blogs/parallel-computing/10362/
Чтобы быстро задействовать GPU (хотя и с меньшей эффективностью) можно использовать директивные средства распараллеливания, а именно PGI Accelerator, доступ к триальной версии которого можно получить на месяц бесплатно
http://www.nvidia.ru/object/openacc-gpu-directives-ru.html
вот ссылки на записи презентаций по применению данного ПО для C и Fortran кодов
http://youtu.be/5tDhWkSc4BI
http://youtu.be/MjGEcZ7LHAQ
25 июня по 7 июля 2012 в Москве в МГУ будет проходить Международная Летняя Суперкомпьютерная Академия, на которой будут курсы по CUDA.
http://academy.hpc-russia.ru/
PGI Accelerator и OpenACC
Компиляторы PGI (pgcc/pgCC/pgf77/pgfortran) позволяют создавать приложения для запуска на GPU (см. [1-3]). Поддержка стандарта OpenACC [4] добавлена в 2012 году с версии 12.6 (см. [5]; в частности, о переходе на OpenACC в [6]). Приложения могут быть запущены на узлах с графическими ускорителями кластера "Уран" (umt).
Настроиться на компиляторы PGI можно с помощью команды mpiset
(на текущую рабочую версию)
mpiset 7
или, загрузив модуль с нужной версией, с помощью команды module. Например, в начале сеанса
module switch mpi/default mvapich2/pgi_12.10
Для компиляции тогда можно использовать, например, команду pgcc или mpicc
mpicc -o exam_pgi exam.c -ta=nvidia -Minfo=accel -fast
где опция -ta=nvidia подключает компиляцию на GPU,
а необязательная опция -Minfo=accel служит для выдачи дополнительной информации о генерации кода для GPU (accelerator kernel).
Для версий компилятора с поддержкой OpenACC можно вместо опции -ta=nvidia использовать опцию -acc.
Опция -ta=nvidia,time (где time - подопция) используется для выдачи времени, потраченного на инициализацию GPU (init), перемещение данных (data) и вычисления на GPU (kernels).
Использование же -ta=nvidia,host задаст генерацию единого кода для host (CPU) и GPU: при наличии GPU программа будет выполняться на GPU, иначе на host.
Например,
mpicc -o exam_gh exam.c -ta=nvidia,host -Minfo
Можно узнать, выполняется ли программа на GPU, если установить переменную окружения ACC_NOTIFY в 1
export ACC_NOTIFY=1
и запустить программу. При каждом вызове функции GPU (kernel) будет выдаваться сообщение вида
launch kernel file=...
что полезно при разработке и отладке программы.
Примеры C и Fortran программ есть на umt, например в каталоге
/opt/pgi/linux86-64/11.1/EXAMPLES/accelerator
и рассматриваются в [2].
Замечания.
- Помните, что в С, по умолчанию, все константы с плавающей точкой имеют тип
double. Поэтому в [2, First Program] для вычислений с одинарной точностью используется 2.0f вместо 2.0. - Для безопасного распараллеливания в С программах (см. [2]) объявления указателей, ссылающихся на распределенную с помощью malloc() память, содержат квалификатор
restrict. Такие указатели ссылаются на непересекающиеся области памяти.
Запуск приложения на счет с использованием GPU можно осуществить с помощью команды
srun --gres=gpu:1 exam_pgi
Опция -C k40m (или -C m2090) позволяет указать желаемый тип GPU (см. Кластер "Уран"), например,
srun --gres=gpu:1 -C k40m exam_pgi
С помощью программы pgaccelinfo [2, Setting Up] можно получить информацию о технических характеристиках GPU конкретного узла, указав опцию -w, например
srun -w tesla52 --gres=gpu:1 pgaccelinfo
Возможно совместное использование OpenMP и GPU.
Общие замечания.
- Использование GPU может дать значительное ускорение для задач, где активно задействованы стандартные математические функции (sin, cos, …, см. [1]). При этом надо иметь в виду, что точность вычислений на GPU не та же самая, что на CPU (в частности, и для тригонометрических функций).
Рекомендуется (см., например, [2, 3]): - До первого запуска kernel осуществлять начальную инициализацию GPU с помощью вызова функции acc_init(acc_device_nvidia).
- Копировать массивы целиком (память host <---> память GPU).
Компилятор стремится минимизировать объём перемещаемых данных, не заботясь о количестве команд пересылки данных. Во многих случаях издержки на инициирование/завершение команд пересылки оказываются больше, чем экономия на времени самой пересылки, и более эффективно посылать один большой непрерывный кусок. - Если посчитанные GPU данные не используются в дальнейшем на host, то следует явно указать компилятору, что соответствующие переменные не надо передавать обратно. Компилятор обычно возвращает на host все модифицированные данные.
- Постараться избавиться от диагностики вида ‘Non-stride-1 accesses for array 'X'’, изменив или структуру массива, или порядок заголовков циклов, или параметры преобразования циклов (loop schedule). Эта диагностика означает, что для соответствующего массива не обеспечен непрерывный доступ к данным и может возникнуть задержка при выполнении групп нитей (threads in groups), которые NVIDIA называет warps. Упрощённо можно думать, что warp выполняется в SIMD или векторном виде с доступом к памяти порциями определённого размера.
- GPU Programming with the PGI Accelerator Programming Model
by Michael Wolfe/ PGI GPU Programming Tutorial. Mar 2011 - The PGI Accelerator Programming Model on NVIDIA GPUs. Part 1
by Michael Wolfe/ June 2009 - The PGI Accelerator Programming Model on NVIDIA GPUs. Part 2 Performance Tuning
by Michael Wolfe/ August 2009 - The OpenACC™ Application Programming Interface. Version 1.0. November, 2011
- PGI Accelerator Compilers with OpenACC Directives
- PGI Accelerator Compilers with OpenACC
by Michael Wolfe/ March 2012, revised in August 2012
Параллельный Matlab
Система Matlab (Matrix Laboratory) - разработка компании The MathWorks, предназначенная для выполнения математических расчетов при решении научных и инженерных задач.
Достоинства Matlab – это, прежде всего, простота матричных операций и наличие многочисленных пакетов программ (Toolbox-ов), среди которых
Parallel Computing Toolbox, расширяющий Matlab на уровне языка операциями параллельного программирования.
Parallel Computing Toolbox достаточно для написания и запуска параллельной Matlab программы на локальной машине (Product Documentation).
Вычисления с Matlab на кластере требуют уже 2 продукта:
Parallel Computing Toolbox и
Matlab Distributed Computing Server
В ИММ имеются все 3 основных продукта для параллельных вычислений с Matlab на кластере "Уран" (версия Matlab R2011b и старше):
1) Matlab: 10 лицензий,
2) Parallel Computing Toolbox: 10 лицензий
(прежнее название Distributed Computing Toolbox),
3) Matlab Distributed Computing Server: 1000 лицензий
(прежнее название Matlab Distributed Computing Engine);
а также большое количество специализированных Toolbox-ов: по 10 лицензий на SIMULINK, Signal_Blocks, Image_Acquisition_Toolbox, Image_Toolbox, MAP_Toolbox, Neural_Network_Toolbox, Optimization_Toolbox, PDE_Toolbox, Signal_Toolbox, Statistics_Toolbox, Wavelet_Toolbox и 2 лицензии на Filter_Design_Toolbox.
Список всех установленных на кластере продуктов Matlab и количество доступных лицензий на них можно уточнить командой
/opt/matlab-R2010a/etc/lmstat -aНазвание текущей рабочей версии Matlab можно узнать, набрав, например, в командной строке
echo 'exit' | matlab -nodisplayили выполнив в окне Matlab команду ver.
Замечания.
1. При работе в Matlab следует ориентироваться на документацию используемой версии.
2. Для смены текущей версии следует воспользоваться командой module.
Можно запускать программы из командной строки или из системы Matlab.
Для запуска программ на кластере из командной строки пользователю необходимо установить на своем компьютере программу PuTTY.
Запуск параллельных Matlab-программ из командной строки осуществляется с помощью разновидностей команды mlrun.
Для работы в диалогом окне Matlab на компьютере пользователя предварительно должен быть установлен и запущен какой-нибудь X-сервер (MobaXterm, X2Go).
Из командной строки вызвать Matlab
matlab или
matlab & (с освобождением командной строки)
и дождаться появления оконного интерфейса Matlab.
Запуск параллельных программ на кластере из системы Matlab осуществляется с помощью разновидностей служебной функции imm_sch.
Замечание. Можно работать в системе Matlab, запустив её в интерактивном текстовом режиме командой
matlab -nodisplayВыход осуществляется по команде exit.
Параллельные вычисления на кластере инициируются
1) запуском параллельных програм;
2) запуском частично параллельных программ (c parfor или spmd);
3) запуском программ с использованием GPU.
Подробнее на нижеследующих страницах.
В разделе "Запуск задач на кластере" находится краткая инструкция "Запуск параллельного Matlab".
Использование русских букв в Linux версии Matlab
Для работы с русскими буквами в Matlab'е необходимо правильно настроить кодировку файла с программой, и, при необходимости, настроить ввод русских букв в клиентской программе.
Возможны два варианта настройки кодировки файла с программой:
- Если в основном вы работаете в Windows, то рекомендуется использование кодировки CP1251.
- Если вы создаёте, редактируете и запускаете программы в основном в Linux, то рекомендуется использование кодировки UTF-8 (кодировка на кластере по умолчанию).
Вариант 1
На кластере "Уран" при запуске Matlab'а можно включить Windows-кодировку CP1251. Для этого необходимо запускать Matlab в окне терминала следующей командой:
LANG=ru_RU.CP1251 matlabПосле этого можно нормально работать с файлами, подготовленными в Windows.
Внимание. Данный вариант может не сработать при запуске счётной задачи на узлах кластера.
Как минимум, в начало счетной программы надо вставить команду:
feature('DefaultCharacterSet', 'cp-1251');
После этого строки, выводимые функцией fprintf(), будут сохраняться в правильной кодировке. Строки на русском языке, выводимые функцией disp(), к сожалению, будут испорчены в любом случае.
Если в программе для вывода результатов используется функция disp(), выполняются операции сравнения или сортировки строк с русскими буквами, то стоит попробовать второй вариант.
Вариант 2
После передачи файла из Windows на кластер можно перекодировать его в кодировку UTF-8. Следует помнить, что перекодированный файл будет некорректно отображаться в Windows, зато он без проблем будет обрабатываться на кластере.
2.a Перекодирование файла на кластере в командной строке. Файл перекодируется с помощью команды
iconv -c -f WINDOWS-1251 -t UTF-8 winfile.m > unixfile.m где winfile.m - имя исходного файла, а unixfile.m - перекодированного (подставьте вместо winfile.m и unixfile.m имена ваших файлов, главное, помните - они должны быть различными). Затем можно открыть новый файл в Matlab'е.
2.b Перекодирование файла на кластере в текстовом редакторе. Для перекодирования файла необходимо запустить текстовый редактор KWrite (Linux'овская кнопка "Пуск", затем ввести в строке поиска имя редактора). При открытии файла с программой указать кодировку cp1251, убедиться, что русские буквы читаются правильно, затем выбрать пункт меню "Файл ->Сохранить как" и указать при сохранении кодировку UTF-8.
Если есть необходимость перекодировать файлы, полученные с кластера, то это также можно сделать с помощью KWrite. При открытии файла надо выбрать кодировку UTF-8, а потом сохранить файл в кодировке cp1251.
В командной строке перекодирование из Linux в Windows выглядит так:
iconv -c -f UTF-8 -t WINDOWS-1251 unixfile.m > winfile.m
Примечание для администраторов
В дистрибутиве RHEL и его производных (CentOS, Scientific Linux) отсутствует файл локализации ru_RU.CP1251. Поэтому "Вариант 1" не сработает (Matlab не запустится с сообщением о невозможности установить указанный язык).
Для генерации файла с кодировкой администратор должен выполнить в Linux'е команду:
localedef -i ru_RU -f CP1251 ru_RU.CP1251
Историческое примечание
Старые версии Matlab'а (до 2010 года) умели работать с единственной кодировкой русских букв ISO-8859-5. Для того, чтобы ее настроить на серверной стороне, необходимо установить переменную окружения LANG в значение ru_RU.8859-5 .
1) Для корректной обработки русских букв на вычислительных узлах
в файл ".bashrc" из домашнего каталога пользователя (~/.bashrc) необходимо вставить следующую строку:
export LANG=ru_RU2) в настройках сессии программы PuTTY, в разделе Translation, установить кодировку ISO-8859-5:1999 (Latin/Cyrillic) и сохранить эту сессию для работы с системой Matlab в дальнейшем.
Запуск параллельной программы
Основные сведения
Параллельная программа - это программа, копии которой, запущенные на кластере одновременно, могут взаимодействовать друг с другом в процессе счета.
Программа пользователя должна быть оформлена как функция (не скрипт) и находиться в начале запускаемого файла, т.е. предшествовать возможным другим вспомогательным функциям. Имя файла должно совпадать с именем первой (основной) функции в файле. Одноименная с файлом функция, не являющаяся первой, никогда не будет выполнена, так как независимо от имени всегда выполняется первая функция файла. Файл должен иметь расширение "m" (Пример параллельной программы).
Для выполнения программы пользователя всегда вызывается программа MatLab.
При запуске программы пользователя на кластере в программе MatLab создаётся объект Job (работа) с описанием параллельной работы, которое включает определение объекта Task (задача), непосредственно связанного с заданной программой. Можно сказать, что копия работающей программы представлена в системе MatLab объектом Task.
Каждый объект Job получает идентификатор (ID) в системе MatLab, равный порядковому номеру. Нумерация начинается с 1.
Соответствующее имя работы вида Job1, выдаваемое при запуске, хранится в переменной окружения MDCE_JOB_LOCATION и может быть использовано в программе, а сам объект доступен пользователю во время сеанса MatLab.
Аналогично пользователь имеет доступ и к объектам Task (задача), которые также нумеруются с 1. Идентификатор или номер задачи (1,2,...) - это номер соответствующего параллельного процесса (lab) и его можно узнать с помощью функции labindex, а общее число запущенных копий с помощью функции numlabs.
Имена работы (Job1), задач (Task1, Task2,…) используются в процессе вычислений для формирования имен файлов и каталогов, связанных с заданной программой. Так, каталог вида Job1 содержит наборы файлов с информацией по задачам. Имена этих файлов начинаются соответственно с Task1, Task2, … Например, файлы вывода имеют вид Task1.out.mat, Task2.out.mat, … и содержат, в частности, выходные параметры функции пользователя (массив ячеек argsout).
Программа пользователя, оформленная в виде объекта Job, поступает в распоряжение системы запуска, которая ставит её в очередь на счет с присвоением своего уникального идентификатора.
Система запуска создает каталог вида my_function.1, например для файла my_function.m. В этом каталоге пользователю может быть интересен, в частности, файл errors (см. Возможные ошибки). Заметим, что пользователь должен сам удалять ненужные каталоги вида имя_функции.номер (номера растут, начиная с 1).
Если ресурсов кластера достаточно, то на каждом участвующем в вычислении процессоре (ядре для многоядерных процессоров) начинает выполняться копия программы-функции пользователя при условии наличия достаточного числа лицензий (в настоящее время система запуска не контролирует число лицензий, доступность лицензий определяется в начале счета).
Пользователь может контролировать прохождение своей программы через систему запуска как в окне системы Matlab, например, с помощью Job Monitor (см. п. Доступ к объекту Job ), так и из командной строки с помощью команд системы запуска (запросить информацию об очереди, удалить стоящую в очереди или уже выполняющуюся программу).
Действия пользователя
Войти на кластер (с помощью PuTTY или MobaXterm) и запустить программу-функцию из командной строки или в окне системы Matlab, указав необходимое для счета число параллельных процессов и максимальное время выполнения в минутах.
В ответ пользователь должен получить сообщение вида:
Job output will be written to: /home/u1303/Job1.mpiexec.out где Job1 - имя сформированной работы, 1 - идентификатор работы
(/home/u1303 - домашний (личный) каталог пользователя).
Замечание. Для локализации результатов вычислений рекомендуется осуществлять запуск программы (даже в случае запуска встроенных функций Matlab ) из рабочего каталога, специально созданного для данной программы в домашнем каталоге.
Запуск параллельной программы из командной строки
Команда запуска mlrun имеет вид
mlrun -np <number_of_procs> -maxtime <mins> <func> ['<args>']где<number_of_procs> - число параллельных процессов (копий программы)<mins> - максимальное время счета в минутах<func> - имя файла с одноименной функцией (например, my_function)<args> - аргументы функции (не обязательный параметр) берутся в одиночные кавычки и представляются в виде
k,{arg1,...,argn}
где k - число выходных аргументов функции, а в фигурных скобках список ее входных аргументов. При отсутствии аргументов у функции, что соответствует "0,{}", их можно опустить. Например, для файла my_function.m с одноименной функцией без параметров запуск имеет вид:
mlrun -np 8 -maxtime 20 my_functionгде 8 - число процессов, 20 - максимальное время счета в минутах.
Запуск параллельной программы в окне Matlab
В командном окне Matlab (Command Window) вызвать служебную функцию imm_sch, которой в качестве параметров передать число процессов, время выполнения и предназначенную для параллельных вычислений функцию с аргументами или без, сохраняя (рекомендуется) или не сохраняя в переменной (например, job) ссылку на созданный объект Job (имя функции набирается с символом "@" или в одиночных кавычках):
job = imm_sch(np,maxtime,@my_function,k {arg1,...,argn});или
job = imm_sch(np,maxtime,'my_function',k,{arg1,...,argn});Так, для примера выше запуск в окне Matlab будет иметь вид:
job = imm_sch(8,20,@my_function);Доступ к объекту Job, состояние работы
Все работы хранятся на кластере. При необходимости доступа к работе, на которую в текущий момент отсутствует ссылка, можно (1) в окне Job Monitor правой кнопкой мыши выделить нужную работу и выбрать соответствующую опцию в контекстном меню или (2) по идентификатору (ID) определить ссылку на работу (обозначенную ниже job), используя, например, команды:
c = parallel.cluster.Generic
job = c.findJob('ID',1)Состояние работы (State) можно:
(1) увидеть в окне Job Monitor или
(2) выдать в окне Command Window, набрав
job.State
Основные значения состояния работы следующие:
pending (ждет постановки в очередь)
queued (стоит в очереди)
running (выполняется)
finished (закончилась)
Окончания счета (состояние finished) можно ждать с помощью функции wait, wait(job) или job.wait()
Примечание.
Вышеприведенные команды предназначены для версий MatLab с профилем кластера, т.е. начиная с R2012a. В ранних версиях (с конфигурацией кластера) следует набирать:
s = findResource('scheduler', 'type', 'generic')
job = findJob(s,'ID',1)При этом в поле DataLocation структуры s должен быть текущий каталог (тот, в котором ищем работу). Если каталог другой, то можно выполнить
clear allи повторить предыдущие команды.
В окне Matlab (с R2012a) для работы job и любой ее задачи (Task) с номером n=1,2,... можно выдать (далее для удобства n=1)
1) протокол сеанса:
job.Tasks(1).Diary2) информацию об ошибках (поле ErrorMessage):
job.Tasks(1) или job.Tasks(1).ErrorMessage
3) результаты (значения выходных параметров) работы job в целом (по всем Task-ам):
out = job.fetchOutputsТогда для 1-ой задачи (Task) значение единственного выходного параметра:
res = out{1}
В случае нескольких выходных параметров соответственно имеем для 1-го, 2-го, ... :
res1 = out{1,1}
res2 = out{1,2}
Другой способ выдачи результатов по задачам
out1 = job.Tasks(1).OutputArgumentsЗамечания.
1. Эту же информацию можно выдать, запустив Matlab в интерактивном текстовом режиме (matlab -nodisplay) и набирая затем упомянутые команды.
2. Если ссылка на работу (job) отсутствует, то ее можно найти по идентификатору.
3. Для ранних версий (до R2012a) следует использовать следующие команды, чтобы выдать
1) протокол сеанса:
job.Tasks(1).CommandWindowOutput 3) результаты (значения выходных параметров) работы job в целом (по всем Task-ам):
out = job.getAllOutputArguments1. Начать работу на кластере рекомендуется с запуска своей последовательной программы в тестовом однопроцессном варианте, например,
mlrun -np 1 -maxtime 20 my_functionгде my_function – функция без параметров, максимальное время счета 20 минут.
2. После преобразования последовательной программы в параллельную её работоспособность можно проверить, выполняя шаги, приведенные в пункте Как убедиться в работоспособности программы при рассмотрении примеров с распределенными массивами.
Пример запуска программы
Для запуска программы на кластере используем функцию rand, вызываемую для генерации 2х3 матрицы случайных чисел (традиционный вызов функции: y = rand(2,3)).
Для получения 4 экземпляров матрицы задаем число процессов, равное 4. Максимальное время счета пусть будет равно 5 минутам.
Запускать функцию будем на кластере "Уран" (umt) в каталоге test, специально созданном заранее в домашнем каталоге пользователя /home/u9999, где u9999 – login пользователя (см. Схема работы на кластере и Базовые команды ОС UNIX).
Для запуска функции rand из командной строки используется команда mlrun,
а из системы Matlab – служебная функция imm_sch.
Для запуска из командной строки войти на umt через PuTTY и выполнить команду
mlrun -np 4 -maxtime 5 rand '1,{2,3}'Для запуска из окна Matlab войти на umt из MobаXterm, вызвать Matlab командой
matlab &и в открывшемся окне набрать
job = imm_sch(4,5,@rand,1,{2,3});где job – ссылка на сформированную работу.
Можно работать в системе Matlab, войдя на umt через PuTTY и запустив её в интерактивном текстовом режиме командой
matlab -nodisplayВ ответ на приглашение (>>) следует соответственно набрать
job = imm_sch(4,5,@rand,1,{2,3});Выход из Matlab осуществляется по команде exit.
После выполнения mlrun или imm_sch выдается строка вида
Job output will be written to: /home/u9999/test/Job1.mpiexec.outгде Job1 - имя сформированной работы, 1 - идентификатор (номер) работы.
Если ресурсов кластера достаточно, задача войдет в решение (см. Запуск задач на кластере). Иначе для ускорения запуска на кластере небольших (отладочных) задач можно вместо выделенного задаче раздела назначить debug командой вида:
scontrol update job 8043078 partition=debugгде 8043078 — уникальный идентификатор (JOBID) задачи.
Дожидаемся окончания задачи, т.е. job.State должно быть finished.
В окне Matlab контролировать состояние задачи удобно с помощью Job Monitor.
Результаты выдаем с помощью команд:
со всех процессов
out = job.fetchOutputsа для выдачи матрицы, полученной 1-ым процессом (т.е. Task1)
out{1}и т.д.
Для выдачи результатов ранее посчитанной работы, на которую в текущий момент нет ссылки, следует обеспечить к ней доступ, например используя Job Monitor.
Запуск частично параллельной программы (c parfor или spmd)
- Введение
- 1. Запуск частично параллельной программы с неявным заданием пула
- 2. Запуск частично параллельной программы с явным заданием пула
на основе профиля кластера
Введение
Частично параллельной будем называть программу, при выполнении которой наряду с последовательными возникают параллельные вычисления, инициируемые параллельными конструкциями языка Matlab parfor и spmd.
Использование параллельного цикла parfor или параллельного блока spmd предполагает предварительное открытие Matlab пула, т.е. выделение необходимого числа процессов (Matlab workers или labs), на локальной машине или на кластере.
Запуск частично параллельных программ с открытием Matlab пула на кластере можно выполнять
(1) по аналогии с запуском параллельных программ из командной строки или в окне системы Matlab (запуск с неявным заданием пула) или
(2) на основе профиля кластера (с версии R2012a, ранее параллельной конфигурации) при работе в окне системы Matlab (запуск с явным заданием пула).
Пользователь может контролировать прохождение своей программы через систему запуска как в окне системы Matlab (с версии R2011b) с помощью Job Monitor (см. пункт меню Parallel), так и из командной строки с помощью команд системы запуска.
1. Запуск частично параллельной программы с неявным заданием пула
При запуске из командной строки вместо команды mlrun (для параллельных программ) следует использовать команду mlprun, например,
mlprun -np 12 -maxtime 20 my_function '1, {x1, x2}'а при запуске в окне вместо функции imm_sch использовать функцию imm_sch_pool, например,
job = imm_sch_pool(12,20,@my_function,1,{x1,x2});для функции, определенной как
function y = my_function(x1,x2)и запущенной на 12 процессах с максимальным временем счета 20 минут.
При этом один процесс будет выполнять программу-функцию, а оставшиеся будут использованы в качестве пула.
В результате запуска программа ставится в очередь на счет и, если ресурсов кластера достаточно, входит в решение.
Вывод результатов осуществляется так же, как и в случае параллельных программ.
2. Запуск частично параллельной программы с явным заданием пула
на основе профиля кластера
Явное задание пула возможно при работе в окне Matlab с помощью команды matlabpool (см. help matlabpool). Число выделенных процессов и время, в течение которого они будут доступны пользователю, зависят от заданного профиля кластера (см. пункт меню Help/Parallel Computing Toolbox/Cluster Profiles).
Команда
matlabpoolбез параметров открывает пул, используя профиль по умолчанию с указанным в нем размером пула. В ИММ УрО РАН по умолчанию Matlab пул открывается на узлах кластера (тип кластера Generic), поскольку управляющий компьютер, выступающий в роли локальной машины (Matlab client), не должен использоваться для длительных вычислений.
Пользователь может выбрать профиль по умолчанию из уже существующих профилей или создать новый, используя пункт меню Parallel окна Matlab.
Команда matlabpool с указанием размера пула, например
matlabpool open 28открывает пул, переопределяя размер, заданный по умолчанию. При этом следует иметь в виду, что существует ограничение на максимальное число доступных пользователю процессов на кластере.
В результате открытия пула сформированная для кластера работа с именем вида JobN (где N=1,2,...) поступает в распоряжение системы запуска и ставится в очередь на счет. Если свободных процессов достаточно, то пул будет открыт на время, заданное в профиле по умолчанию, с выдачей сообщения вида:
Starting matlabpool using the 'imm_20mins' profile ... Job output will be written to: /home/u1303/my_directory/Job1.mpiexec.out
connected to 28 labs.Размер пула можно узнать, набрав
matlabpool sizeПо завершении вычислений, связанных с пулом, его следует закрыть
matlabpool closeВнимание. Пул закрывается по истечении времени с диагностикой вида:
The client lost connection to lab 12.
This might be due to network problems, or the interactive matlabpool job might have errored.
Запуск частично параллельной программы на Matlab клиенте
(не разрешается для длительных вычислений)
Итак, схема использования параллельных конструкций parfor и spmd в окне Matlab такова:
matlabpool
...
% вычисления с использованием parfor или spmd,
% выполняемые построчно или
% собранные в программу (частично параллельную)
% и запущенные из файла
...
matlabpool closeПри этом все вычисления, кроме параллельных, выполняет Matlab client (см., например, Introduction to Parallel Solutions/Interactively Run a Loop in Parallel.)
Запуск частично параллельной программы с помощью команды batch
В системе Matlab существует команда (функция) batch, которая позволяет запускать программы в пакетном режиме, разгружая Matlab client (см., например, Introduction to Parallel Solutions/Run a Batch Job). Эта команда выполняется асинхронно, т.е. интерактивная работа пользователя не блокируется.
Где будет выполняться программа и максимально сколько времени, определяется планировщиком (scheduler), заданным в профиле кластера по умолчанию: в ИММ на кластере, тип планировщика generic. Для выполнения программы создается объект Job (работа). Команда batch вида
job = batch('my_mfile')(job - ссылка на объект работа)
запускает программу (скрипт или функцию) my_mfile в однопроцессном варианте. В ответ на команду batch выдается сообщение вида
Job output will be written to: /home/u1303/my_directory/Job1.mpiexec.outсодержащее идентификатор работы (ID), равный здесь 1. Сформированная для кластера работа ставится в очередь и при наличии свободных процессов входит в решение с именем очереди вида my_mfile.1.
Для запуска на кластере частично параллельной программы можно использовать команду batch с открытием пула. При этом выделяемое на кластере число процессов будет на 1 больше заданного размера пула.
Так, например, для выполнения команды
job = batch('my_mfile','matlabpool',11)потребуется 12 процессов: 1 для программы my_mfile, 11 для пула (см., например, Introduction to Parallel Solutions/Run a Batch Parallel Loop). Время счета здесь определяется временем, заданным в профиле по умолчанию (в аналогичной команде imm_sch_pool все аргументы задаются явно).
По завершении работы job можно выдать
1) протокол сеанса
job.diary2) результаты работы
out=job.fetchOutputs
celldisp(out)
(fetchOutputs вместо getAllOutputArguments в ранних версиях, использовавших конфигурацию кластера, а не профиль)
3) информацию об ошибках (поле ErrorMessage)
job.Tasks(1)или
job.Tasks(1).ErrorMessageЗапуск программ с использованием GPU
Программа с использованием GPU - это параллельная программа, каждая ветвь (копия, процесс), которой может использовать своё GPU.
Поэтому к программе с GPU применимо почти все, что относится к параллельной программе (в частности, это должна быть программа-функция). Особенности запуска программ с GPU отмечены ниже.
Программа с использованием GPU в результате запуска ставится в очередь на счет в системе SLURM. Пользователь может контролировать прохождение своей программы через эту систему с помощью соответствующих команд или в окне системы Matlab (с версии R2011b) с помощью Job Monitor (см. пункт меню Parallel).
При запуске программы-функции, как обычно, указывается необходимое для счета число параллельных процессов и максимальное время выполнения в минутах, но используются другие команды.
Запуск программы на счет осуществляется по аналогии с запуском параллельных программ:
из командной строки с помощью команды mlgrun, например,
mlgrun -np 8 -maxtime 20 my_gpufunction
или в окне системы Matlab с помощью служебной функции imm_sch_gpu, например,
job = imm_sch_gpu(8,20,@my_gpufunction);
В приведенных командах запускается функция без параметров с использованием 8 процессов, 20 минут - максимальное время счета.
При этом каждый из 8 процессов (копий функции) может использовать своё GPU.
При наличии параметров у функции они указываются по тем же правилам, что и в случае параллельной программы.
Возможные ошибки
1) Если не хватает лицензий для запуска на кластере функции my_function из одноименного файла my_function.m, то информация об ошибке находится в файле вида my_function.1/errors. При этом, как правило, файл my_function.1/output содержит MPIEXEC_CODE=123. Число свободных лицензий, кто и какие лицензии занимает, можно узнать, используя команду lmstat.
Внимание. В настоящее время система запуска не контролирует число лицензий, доступность лицензий определяется только в начале счета.
2) ErrorMessage содержит ошибки трансляции, например:
Undefined function or variable 'my_function'.Имя или расширение файла, имя функции или переменной отсутствует или указано неверно. Имя может отсутствовать по причине случайного запуска из другого каталога.
Invalid function name 'j-cod'.В именах файлов и функций не должно быть минуса ("-"), только подчерк ("_").
Invalid file identifier. Use fopen to generate a valid file identifier.Возможно, имя файла задано русскими буквами.
Внимание. В случае таких ошибок в файле my_function.1/errors обычно содержится строка
[0]application called MPI_Abort(MPI_COMM_WORLD, 42) - process 0Помните: имя файла должно совпадать с именем первой функции в файле, так как
(1) при запуске программы ищется файл с именем, указанным в команде запуска, и
(2) в нем выполняется, прежде всего, первая функция.
Если они не совпадают и при запуске указано имя функции (например, my_function), то файл не будет найден и будет выдана ошибка вида:
Undefined function or variable 'my_function'. Если они не совпадают и при запуске указано имя файла (например, my_code), то выполнится первая функция файла независимо от ее имени. При этом наличие одноименной с файлом функции, не являющейся первой, приведет к выдаче в протоколе сеанса предупреждения вида:
Warning: File: my_code.m Line: 25 Column: 14
Function with duplicate name "my_code" cannot be called.
3) Если выполнение программы прервано принудительно, например, по истечению времени, то выходная информация отсутствует (т.е. файлы вывода вида Task1.out.mat будут пусты). При этом состояние работы (поле State) будет running, в то время как состояния её задач (поля State для Tasks(n), где n=1,2,...) могут быть как running, так и finished, если часть копий программы успела финишировать до окончания заказанного времени.
В случае исчерпания времени соответствующая информация попадает в файл my_function.1/errors.
4) В случае аварийного завершения работы программы в домашнем каталоге пользователя (~) могут оставаться файлы вида mpd.hosts.123456 и mpd.mf…
Их следует периодически удалять вручную.
Завершение работы
Работу, в которой нет больше необходимости, следует уничтожить, используя Job Monitor (Delete в контекстном меню) или функцию delete, освобождая тем самым ресурсы кластера
job.deleteтакже удалить файл вида Job1.mpiexec.out (где Job1 - имя удаляемой работы),
а затем почистить Workspace
clear job
Если эти действия не выполняются пользователем регулярно, то при очередных запусках будут создаваться и накапливаться файлы новых работ Job2, Job3 и т.д.
Не все работы заканчиваются с признаком finished. Так, по истечении времени счета работа будет прервана в состоянии running.
Для уничтожения в текущем каталоге всех или только завершившихся (finished) работ можно воспользоваться написанной в ИММ УрО РАН функцией job_destroy.
Вызов job_destroy без параметра
из командной строки:
echo 'job_destroy, exit' | matlab -nodisplayв окне:
job_destroyуничтожает только завершившиеся работы.
Вызов job_destroy с параметром (тип и значение параметра не существенны)
из командной строки:
echo 'job_destroy(1), exit' | matlab -nodisplayили
echo "job_destroy('all'), exit" | matlab -nodisplayв окне:
job_destroy(1)или
job_destroy('all')уничтожает все работы в текущем каталоге.
Внимание! В состоянии running, разумеется, находятся выполняющиеся в текущий момент работы, поэтому выполняйте команду job_destroy(1) только тогда, когда Вы твердо уверены, что все работы закончились (нормально или аварийно).
После выполнения этой команды нумерация работ начинается с 1.
После уничтожения ненужных работ следует удалить на них ссылки в Workspace с помощью команды clear.
Важные замечания.
1. Нумерация работ (Job) в каталоге пользователя начнется с 1 в новом сеансе Matlab при отсутствии каталогов и файлов предыдущих работ (Job...).
2. Каталог вида my_function.1 не удаляется при использовании команды job_destroy. При новых запусках одной и той же программы образуются аналогичные каталоги с возрастающими номерами: my_function.2, my_function.3…
Пользователь должен сам удалять ненужные каталоги.
Пример параллельной программы
Пример взят с сайта MathWorks и иллюстрирует основные (базовые) принципы программирования параллельной программы-функции.
Копия работающей функции, т.е. задача (Task), для которой значение labindex равно 1, создает магический квадрат (magic square) с числом строк и столбцов равным числу выполняющихся копий (numlabs) и рассылает матрицу с помощью labBbroadcast остальным копиям. Каждая копия вычисляет сумму одного столбца матрицы. Все эти суммы столбцов объединяются с помощью функции gplus, чтобы вычислить общую сумму элементов изначального магического квадрата.
function total_sum = colsum
if labindex == 1
% Send magic square to other labs
A = labBroadcast(1,magic(numlabs))
else
% Receive broadcast on other labs
A = labBroadcast(1)
end
% Calculate sum of column identified by labindex for this lab
column_sum = sum(A(:,labindex))
% Calculate total sum by combining column sum from all labs
total_sum = gplus(column_sum)
endСуществуют альтернативные методы получения данных копиями функций, например, создание матрицы в каждой копии или чтение каждой копией своей части данных из файла на диске и т.д.
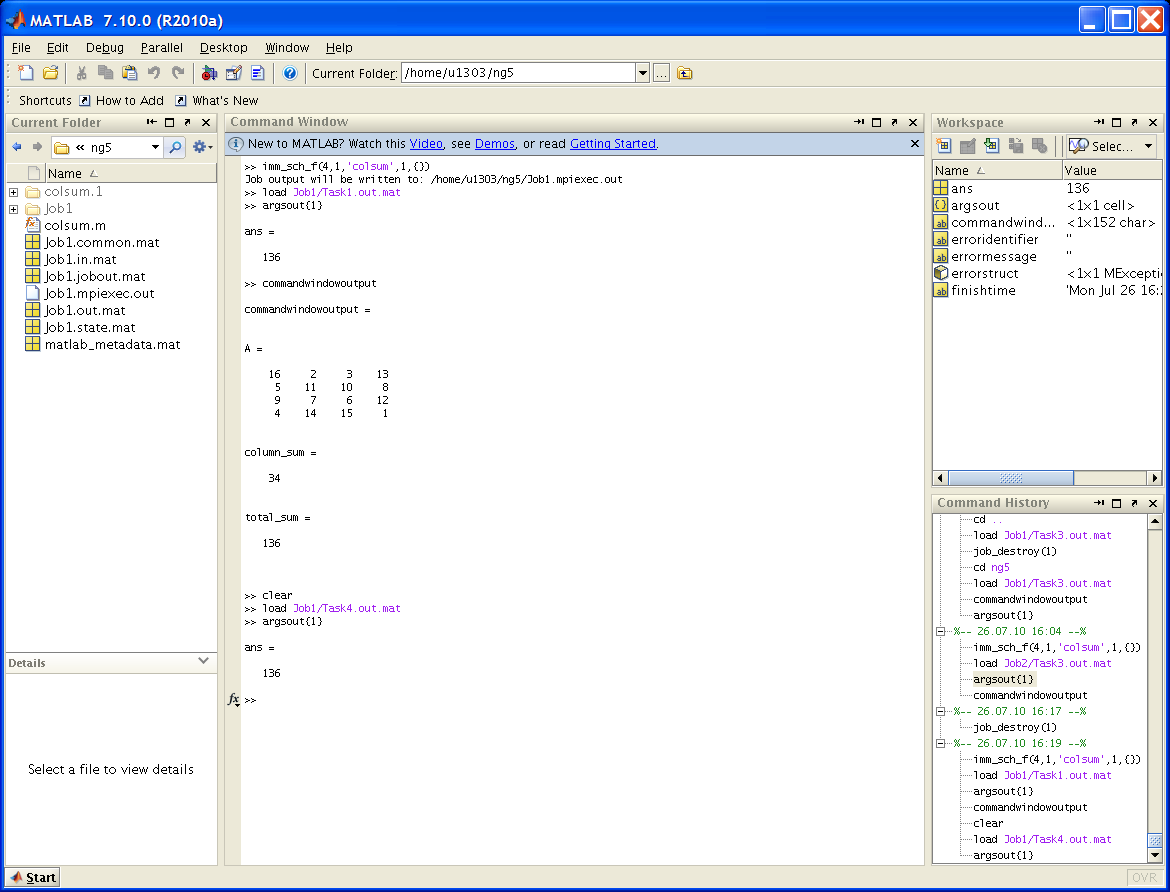
В прикрепленном файле ml_session.PNG (см. ниже) демонстрируется запуск функции colsum в окне системы Matlab с использованием 4-х вычислительных процессов и максимальным временем счета 1 минута.
Функция хранится как файл colsum.m в каталоге ng5 пользователя (полный путь: /home/u1303/ng5). После запуска imm_sch_f(4,1,'colsum',1,{});, а в более поздних версиях (с учетом переименования служебной функции в imm_sch)
job = imm_sch(4,1,@colsum,1);выдается сообщение вида:
Job output will be written to: /home/u1303/ng5/Job1.mpiexec.outв котором указано имя сформированной работы Job1.
Проверив состояние работы и убедившись, что она закончилась, можно выдать результаты счета.
| Прикрепленный файл | Размер |
|---|---|
| 73.66 КБ |
{kind=link}
Примеры с распределенными массивами
Введение
Распределение данных по процессам предназначено для ускорения счета и экономии памяти.
Параллельные вычисления с использованием распределенных массивов подробно описаны на сайте Matlab, в частности, в подразделе Working with Codistributed Arrays.
Распределенный массив состоит из сегментов (частей), каждый из которых размещен в рабочей области (workspace) соответствующего процесса (lab). При необходимости информацию о точном разбиении массива можно запросить с помощью функции getCodistributor (подробнее см. Obtaining information About the Array). Для просмотра реальных данных в локальном сегменте распределенного массива следует использовать функцию getLocalPart.
Возможен доступ к любому сегменту распределенного массива.
Доступ к локальному сегменту будет быстрее, чем к удаленному, поскольку последний требует посылки (функция labSend) и получения (функция labReceive) данных между процессами.
Содержимое распределенного массива можно собрать с помощью функции gather в один локальный массив, продублировав его на всех процессах или разместив только на одном процессе.
Использование распределенных массивов при параллельных вычислениях сокращает время счета благодаря тому, что каждый процесс обрабатывает свою локальную порцию исходного массива (сегмент распределенного массива).
Существует 3 способа создания распределенного массива (см. Creating a Codistributed Array):
1) деление исходного массива на части,
2) построение из локальных частей (меньших массивов),
3) использование встроенных функций Matlab (типа rand, zeros, ...).
1) Деление массива на части может быть реализовано с помощью функции codistributed (Пример 1). При этом в рабочей области каждого процесса расположены исходный массив в своем полном объеме и соответствующий сегмент распределенного массива. Таким образом, этот способ хорош при наличии достаточного места в памяти для хранения тиражируемого (replicated) исходного массива.
Размерности исходного и распределенного массивов совпадают.
Деление массива может быть произведено по любому из его измерений.
По умолчанию в случае двумерного массива проводится горизонтальное разбиение, т.е. по столбцам, что выглядит естественно с учетом принятого в системе Matlab размещения матриц в памяти по столбцам (как в Фортране).
2) При построении распределенного массива из локальных частей в качестве сегмента распределенного массива берется массив, хранящийся в рабочей области каждого процесса (Пример 2). Таким образом, распределенный массив рассматривается как объединение локальных массивов. Требования к памяти в этом случае сокращаются.
3) Для встроенных функций Matlab (типа rand, zeros, ...) можно создавать распределенный массив любого размера за один шаг (см. Using MATLAB Constructor Functions).
Вверх
Как можно использовать распределенные массивы
В приводимых ниже примерах решение задачи связано с вычислением значений некоторой функции, обозначенной my_func. При этом вычисление одного значения функции требует длительного времени.
Даются возможные схемы решения таких задач с использованием распределенных массивов. Показан переход от исходной последовательной программы к параллельной с распределенными вычислениями. Соответствующие изменения выделены.
Замечание.
Хотя дистрибутивные массивы совместимы (в отличие от цикла parfor и GPU) с глобальными переменными, необходимо тщательно следить за тем, чтобы изменения глобальных переменных в процессе обработки одной порции данных не влияли на результаты обработки других порций, тем самым обеспечивая независимость вычислений частей дистрибутивных массивов.
Там, где допустимо, проще использовать цикл parfor или вычисления на GPU.
Вверх
Пример 1. Деление массива на части
Пусть требуется вычислить значения некоторой функции 10 вещественных переменных. Аргументом функции является 10-мерный вектор.
Значение функции необходимо вычислить для n точек (значений аргумента), заданных 10хn матрицей. Вычисление матрицы производится по некоторому заданному алгоритму и не требует много времени.
Обозначения.my_func - вычисляемая функцияМ - массив для аргументов функции my_funcF - массив для значений функции my_funcM_distr - распределенный массив для M (той же размерности)F_distr - распределенный массив для F (той же размерности)
Исходная программа
Результирующая программа
function test_1()
% инициализация данных
n=1000;
...
% резервирование памяти
M = zeros(10,n);
F = zeros(1,n);
% заполнение матрицы М
...
function test_1()
% инициализация данных
n = 1000;
...
% резервирование памяти
M = zeros(10,n);
F = zeros(1,n);
% заполнение матрицы М
...
% создание распределенных массивов
% разбиение по умолчанию проводится
% по столбцам (2-му измерению)
M_distr = codistributed(M);
F_distr = codistributed(F);
% вычисление функции
for i = 1:n
F(1,i) = my_func(M(:,i));
end
% вычисление функции
for i = drange(1:size(M_distr,2))
F_distr(1,i) = my_func(M_distr(:,i));
end
% сбор результатов на 1-ом процессе
F = gather(F_distr,1);
save ('test_res_1.mat', 'F', 'M');
if labindex == 1
save ('test_res_1.mat', 'F', 'M');
end
return
end
return
end
Пример 2. Построение массива из частей.
Распределенный массив как объединение локальных массивов
Сформировать таблицу значений функции 2-х вещественных переменных ((x,y) --> F) на прямоугольной сетке размера 120x200, заданной векторами (x1:x2:x3 и y1:y2:y3). Существует алгоритм вычисления значения функции в точке , обозначенный my_func.
Обозначения.my_func - вычисляемая функция 2-х переменныхF - массив для значений функции my_funcF_loc - локальный массив, который заполняется соответствующими значениями функции на каждом процессе и затем берется за основу (рассматривается как сегмент) при построении распределенного массива F_distrF_distr - распределенный массив, содержимое которого собирается в массиве F на 1-ом процессе
Вариант 1.
Распараллеливание проводится по внешнему циклу (по x - первому индексу).
Предполагается, что число строк 120 кратно numlabs - числу процессов, заказанных при запуске программы на счет.
Исходная программа
Результирующая программа
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
m_x = x1:x2:x3;
n = 120/numlabs;
% выделение памяти
F = zeros(120,200);
% вычисление функции
i = 1;
for x = x1:x2:x3
...
% выделение памяти
F_loc = zeros(n,200);
% вычисление функции
% i = 1;
for i = 1:n
k = (labindex-1)*n + i;
x = m_x(k);
...
j = 1;
for y = y1:y2:y3
F(i,j) = my_func(x,y);
j = j + 1;
end
i = i + 1;
end
j = 1;
for y = y1:y2:y3
F_loc(i,j) = my_func(x,y);
j = j + 1;
end
% i = i + 1;
end
% распараллеливание проведено по строкам
% (1-му измерению) => codistributor1d(1, ...)
codist = codistributor1d(1, [], [120 200]);
F_distr = codistributed.build(F_loc, codist);
F = gather(F_distr, 1);
save ('test_res_2.mat', 'F');
if labindex == 1
save ('test_res_2.mat', 'F');
end
return
end
return
end
Вариант 2.
Распараллеливание проводится по внутреннему циклу (по y - второму индексу).
Предполагается, что число столбцов 200 кратно numlabs - числу процессов, заказанных при запуске программы на счет.
Исходная программа
Результирующая программа
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
m_y = y1:y2:y3;
n = 200/numlabs;
% выделение памяти
F = zeros(120,200);
% вычисление функции
i = 1;
for x = x1:x2:x3
...
j = 1;
for y = y1:y2:y3
% выделение памяти
F_loc = zeros(120,n);
% вычисление функции
i = 1;
for x = x1:x2:x3
...
% j = 1;
for j = 1:n
k = (labindex-1)*n + j;
y = m_y(k);
F(i,j) = my_func(x,y);
j = j + 1;
end
i = i + 1;
end
F_loc(i,j) = my_func(x,y);
% j = j + 1;
end
i = i + 1;
end
% распараллеливание проведено по столбцам
% (2-му измерению) => codistributor1d(2, ...)
codist = codistributor1d(2, [], [120 200]);
F_distr = codistributed.build(F_loc, codist);
F = gather(F_distr, 1);
save ('test_res_2.mat', 'F');
if labindex == 1
save ('test_res_2.mat', 'F');
end
return
end
return
end
Замечание. Эту задачу, если памяти достаточно, можно запрограммировать и первым способом, т.е. путем деления большого массива на части. В этом случае распределение данных по процессам будет сделано автоматически (требование кратности исчезает).
Вверх
Как убедиться в работоспособности программы
Перед первым запуском программы-функции на кластере ее стоит проверить сначала в однопроцессорном варианте с отладчиком Debug (см.,например, Debug a MATLAB Program), а затем в параллельном режиме pmode. Поскольку политика использования вычислительных ресурсов ИММ УрО РАН не предполагает длительных вычислений на управляющем компьютере, запускать программу в режимах Debug и pmode следует с тестовым набором данных.
Итак, рекомендуется следующая последовательность выхода на счет:
Debug
pmode
кластер
Запуск параллельной программы с отладчиком Debug (в однопроцессорном режиме) можно осуществить, например, предварительно открыв текст программы в редакторе (Editor), установив необходимые контрольные точки (щелкая, к примеру, левой клавишей мыши справа от номера нужной строки) и нажав клавишу F5 (см. пункт меню Debug).
Стартовать режим pmode на 4-х процессах (для наглядности) можно в окне Matlab (Command Window) с помощью команды
pmode start 4Затем в командной строке открывшегося параллельного окна (Parallel Command Window) вызвать свою программу.
Закрыть параллельный режим можно или из Parallel Command Window командой
exitили из окна Matlab командой
pmode exitДля контроля за данными полезна функция getLocalPart.
Запуск на кластере можно осуществить в окне Matlab с помощью функции imm_sch.
Использование параллельного профилирования
Основные понятия
Профилирование предназначено для выявления наиболее затратных по времени мест в программе с целью увеличения ее быстродействия (см. Profile to Improve Performance).
Профилирование параллельных программ определяет как затраты на вычисление функций, так и затраты на коммуникации (см. Profiling Parallel Code).
Профилирование в Matlab осуществляется с помощью инструмента, называемого профилировщик или профайлер (profiler).
Результатом профилирования являются суммарный и детальный отчеты о выполнении программы.
Суммарный отчет о профилировании параллельной программы содержит для каждого параллельного процесса (lab) информацию о времени вычисления функций и частоте их использования, а также о времени, затраченном на обмены (коммуникации) и ожидание обменов с другими процессами.
Для проблемных функций полезно выдавать детальный отчет, в котором содержится статистика по строкам функций, а именно: время выполнения и частота использования.
Код программы можно считать достаточно оптимизированным, если в результате изменения алгоритма большая часть времени выполнения программы будет приходиться на обращения к нескольким встроенным функциям.
Вверх
Действия пользователя
Действия пользователя иллюстрируются на примере функции colsum() по аналогии с функцией foo() из раздела Examples описания команды (функции) mpiprofile.
Внесение изменений в текст программы
1) В заголовок функции добавить выходной параметр для информации о профилировании, назовем его p:
function [p, total_sum] = colsum2) В тело функции добавить команду mpiprofile, а именно:
mpiprofile onдля включения профилирования (начала сбора данных)
mpiprofile offдля выключения профилирования при необходимости (или желании)
p = mpiprofile('info');для доступа к сгенерированным данным и сохранения собранной информации в выходном параметре p.
Пример скорректированной программы приведен ниже в файле ml_prof_colsum.PNG.
Запуск программы на профилирование
1) При запуске функции указать увеличенное соответственно на 1 число выходных параметров.
2) Запустить программу-функцию из командной строки:
mlrun -np 9 -maxtime 5 colsum '2'или в окне Matlab:
j = imm_sch(9,5,@colsum,2);Замечание. Окончания счета при желании можно ждать с помощью команды wait(j).
Просмотр результатов профилирования
Пусть программа запущена в окне Matlab. Тогда по окончании счета следует
1) получить результаты:
out = j.fetchOutputs;2) выделить вектор с информацией о профилировании:
p_vector = [out{:, 1}];3) запустить вьюер:
mpiprofile('viewer', p_vector);Подобные действия для ранних версий приведены ниже в файле ml_prof_session.PNG.
Для повторного использования полученные переменные можно сохранить командой:
save ('res_prof', 'out', 'p_vector')(в файле res_prof.mat) и загрузить при необходимости в другом сеансе:
load ('res_prof')
Вверх
Некоторые советы
Первая реализация программы должна быть настолько проста, насколько возможно, т.е. не рекомендуется ранняя оптимизация.
Профилирование может быть использовано
- в качестве инструмента отладки;
- для изучения (понимания) незнакомых файлов.
При отладке программы детальный отчет даст представление о том, какие строки выполнялись, а какие нет. Эта информация может помочь в расширении набора тестов.
Для очень длинного файла с незнакомым матлабовским кодом можно использовать профайлер, чтобы посмотреть, как файл в реальности работает, т.е. посмотреть вызываемые строки в детальном отчете.
При использовании профилирования копию 1-го детального отчета рекомендуется сохранить в качестве основы для сравнения с последующими, полученными в ходе улучшения программы.
Замечание. Существуют неизбежные отклонения времени, не зависящие от кода, т.е. при профилировании идентичного кода дважды можно получить слегка различные результаты.
| Прикрепленный файл | Размер |
|---|---|
| 38.44 КБ | |
| 85.25 КБ |
{kind=link}
{kind=link}
О реализации работы системы Matlab на кластере
Запуск параллельной программы пользователя на кластере организован в соответствии с рекомендациями разработчиков Matlab в разделах
Programming Distributed Jobs и
Programming Parallel Jobs
с учетом используемого в ИММ планировщика (типа Generic Scheduler в терминологии Matlab).
Замечание. Ссылки на сайт разработчика Matlab даны на момент подключения системы Matlab (~2010).
Для осуществления такого запуска необходимо:
Со стороны системы Matlab
1) Обеспечить наличие функций Submit и Decode.
Функция Submit выполняется Matlab клиентом на хосте (управляющей машине) и основное ее назначение - установить необходимые переменные окружения, в том числе для функции Decode, перед обращением к планировщику (Scheduler).
Функция Decode выполняется автоматически Matlab сервером (worker) на каждом узле и основное ее назначение – забрать переданные планировщиком через переменные окружения значения, которые Matlab worker использует для проведения вычислений на узлах кластера.
2) Задать последовательность действий для описания параллельной работы (Job, точнее ParallelJob), в рамках которой и будут проводиться программой Matlab вычисления функции пользователя на кластере. Основные действия описаны на сайте Matlab и продемонстрированы, в частности, на примере. В ИММ с учетом пакетной обработки эти действия дополнены перехватом stdout и stderr, т.е. установкой свойства CaptureCommandWindowOutput в значение true для всех задач (Task) программируемой работы (Job) (коротко о Job и Task см. в пункте Основные сведения).
С целью дальнейшего многократного использования все необходимые для программирования параллельной работы действия были оформлены в виде служебной функции imm_sch_f (позднее переименованной в imm_sch), обозначенной на рисунке ниже как scheme function. Этой функции в качестве параметров передаются число параллельных процессов, время счета, имя и параметры функции пользователя, предназначенной для распараллеливания вычислений.
Функция imm_sch_f служит для запуска параллельных программ.
При запуске параллельной программы в окне системы Matlab пользователь явно обращается к этой функции.
3) Для своевременного удаления информации о завершенных работах предоставить в распоряжение пользователя функцию job_destroy.
Со стороны планировщика
1) Обеспечить пользователя командой запуска параллельной программы из командной строки, аналогичной mpirun (заменённой впоследствии на mqrun). Эта команда получила название mlrun. При вызове mlrun пользователь указывает число необходимых для счета процессов, максимальное время счета и имя, а при наличии и параметры, программы-функции. Команда mlrun в интерактивном текстовом режиме (-nodisplay) вызывает программу matlab для выполнения функции imm_sch_f (scheme function на рисунке), передавая ей все необходимые аргументы.
2) Обеспечить наличие скрипта, реализующего механизм постановки в очередь программы пользователя, сформированной для запуска на кластере в рамках Matlab. Этот скрипт назван matlab_run.
Используем предлагаемую на сайте Matlab схему запуска программы пользователя на кластере для демонстрации получаемой у нас цепочки вызовов (для определенности на um64 в системе пакетной обработки заданий СУППЗ, 2009 г.).
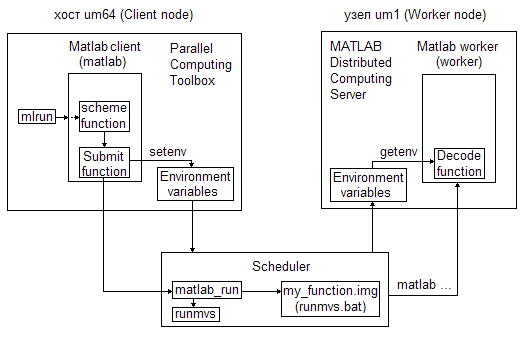
Источниками для написания собственных функций и скриптов послужили:
1) Ориентированные на Generic Scheduler примеры:
- функций Submit и Decode,
- схемы программирования параллельной работы на хосте в клиентской части Matlab и
- действий по удалению (разрушению, destroy) законченной и ненужной уже работы (Job).
2) Документация (скрипты типа pbsParallelWrapper) в каталогах вида:
/opt/matlab-R2009b/toolbox/distcomp/examples/integration/{pbs|ssh|lsf} где R2009b - название версии
3) Скрипты запуска, такие как mvarun_p2 из каталога
/common/runmvs/binСписок наших служебных функций и скриптов приведен в таблице:
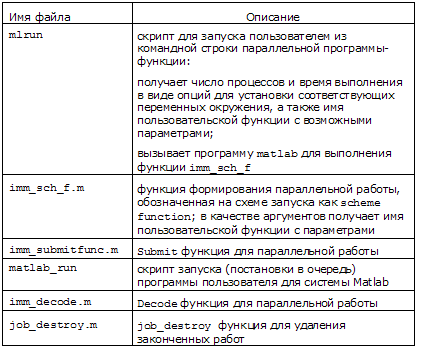
При переходе на новую версию Matlab, например R2010a, следует
- добавить одноименные ссылки в каталог /opt/matlab-R2010a/toolbox/local
на наши служебные Matlab функции, хранящиеся в каталоге /opt/matlab-imm, а именно: imm_sch_f.m, imm_submitfunc.m, imm_decode.m, job_destroy.m ;
- скорректировать файл /etc/profile.d/matlab.sh.
Инструменты Intel для профилировки и отладки
На кластере установлено программное обеспечение (ПО) фирмы Intel для профилировки и отладки – Intel Parallel Studio XE. Это ПО позволяет находить наиболее нагруженные места в приложении, подсчитывать степень параллельности программы, находить тупики и гонки в параллельных программах и т.д.
Основные инструменты Advisor XE, Inspector XE и Vtune Amplifier XE находятся в соответствующих папках в каталоге /opt/intel.
Графический интерфейс (GUI) запускается командами
/opt/intel/advisor/bin64/advixe-gui/opt/intel/inspector/bin64/inspxe-gui/opt/intel/vtune_amplifier_xe/bin64/amplxe-gui
По умолчанию отлаживаемая программа будет запускаться на управляющей машине кластера и мешать другим пользователям. Как запустить последовательную/параллельную программу на узлах кластера подробно описано в справке, которая доступна по кнопке (?) в GUI (а в формате html на кластере в папках /opt/intel/*/documentation/), на сайте Intel https://software.intel.com/en-us/documentation, а также в инструкциях:
Использование Intel® VTune™ Amplifier XE
Intel VTune Amplifier – мощный инструмент для сбора и анализа данных о производительности кода (профилировки) последовательных и параллельных приложений (программ). Явное указание на участки кода, выполняющиеся дольше всего, и определенная детализация причин задержек могут помочь в модификации программы и тем самым существенно ускорить её исполнение. Можно профилировать код, написанный на C, C++, C#, FORTRAN, Java и Assembly. VTune Amplifier проектировался (и работает) для программ со взаимодействием через общую память, поэтому код с MPI и/или OpenMP может быть профилирован, если он выполняется на одном узле.
VTune Amplifier позволяет запустить удаленный анализ на вычислительном узле кластера и просмотреть результаты сбора данных на хосте (головном узле). Для сбора данных на кластере используется интерфейс командной строки amplxe-cl (Intel® VTune™ Amplifier Command Line Interface). Для просмотра результатов удобно использовать графический интерфейс (GUI), который вызывается командой amplxe-gui.
- Подготовка к работе с VTune Amplifier
- Сбор данных на вычислительном узле
- Визуализация результатов в графическом интерфейсе на хосте
- Пример
Подготовка к работе с VTune Amplifier
1. Построить приложение как обычно, с той же опцией оптимизации (-O), но с добавлением опции -g (отладочного режима компиляции) для команд icc, gcc, mpicc, ifort и т.д. Это позволяет профилировать на уровне исходного языка. Рекомендуется использовать (попробовать), например, -O3, чтобы сосредоточиться на оптимизации регионов, не учитываемых компилятором.
2. Установить VTune окружение, выполнив команду:
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh
Сбор данных на вычислительном узле
1. Для профилировки на кластере приложение должно запускаться исполняемым файлом amplxe-cl. Рекомендуется начать со сбора горячих точек (collect hotspots), т.е. с нахождения самых трудоемких функций в приложении. В этом случае запуск на кластере профилировки последовательной программы my_app может иметь вид:
srun amplxe-cl -collect hotspots ./my_appПо умолчанию в рабочем каталоге пользователя будет создан подкаталог с именем r000hs (при первом запуске), в который будет записан файл вида r000hs.amplxe с полученной информацией. При этом hs – аббревиатура типа анализа (hotspots), 000 – номер, который будет автоматически увеличиваться при следующих запусках.
Имя каталога может быть задано опцией -r (или -result-dir), например,
srun amplxe-cl -collect hotspots -r my_res ./my_appСбор данных (для чистоты эксперимента) желательно проводить на одном и том же узле или разделе кластера с одинаковыми узлами, используя соответствующие опции -w, -p.
2. Для приложений, использующих MPI, необходимо установить не только опцию -n для запроса количества процессов, но и -N 1, чтобы задача полностью находилась на одном вычислительном узле. VTune не способен собирать данные по нескольким узлам!
Опция -gtool (только в Intel MPI, устанавливается по команде mpiset 8) позволяет запускать анализ лишь на выбранных процессах, последовательных или многопоточных (см., например, Профилировка гибридных кластерных приложений MPI+OpenMP).
3. Поскольку основным на кластере является пакетный режим, то запуск приложения для профилировки лучше осуществлять командой sbatch.
Замечания.
1) Для доступа к полной документации команды amplxe-cl в используемой версии VTune следует набрать
amplxe-cl -help
amplxe-cl -help collect - уточнить информацию для конкретного действия (action) collect
amplxe-cl -help collect hotspots - дополнительно о типе анализа hotspots и т.п.
2) Можно получить образец нужной команды amplxe-cl, используя возможность генерации этой команды в VTune Amplifier GUI. Следует создать проект, выбрать нужный тип анализа и нажать на клавишу Command Line (подробнее command generation feature на сайте Intel).
Не рекомендуется нажимать на клавишу Start, так как это вызовет запуск приложения на хосте, что может замедлить обслуживание задач других пользователей. Запуск на хосте допустим в крайнем случае для очень коротких задач, не более нескольких минут.
3) Документацию по команде amplxe-cl можно посмотреть на сайте Intel в разделе Intel® VTune™ Amplifier Command Line Interface или найти в GUI в разделе Help, обозначенным в меню вопросительным знаком (?).
Визуализация результатов в графическом интерфейсе на хосте
Для просмотра результатов можно запустить GUI командой
amplxe-gui &и в открывшемся окне нажать на кнопку меню ≡ (вверху справа), выбрать пункт Open/Result... и найти файл-результат (например, my_res.amplxe в каталоге my_res).
Из рабочего каталога задачи достаточно запустить GUI командой
amplxe-gui my_res &где my_res - каталог с результатами профилировки.
Замечания.
1) VTune Amplifier GUI можно запустить из MobaXterm или X2Go Client.
2) Предполагается, что запуску GUI предшествовала установка VTune окружения.
3) & – не обязательный символ. Он используется для запуска с освобождением командной строки.
Окно с результатами откроется на вкладке Summary (итоговая страница).
Раздел Top Hotspots укажет на наиболее трудоемкие (затратные по времени) функции/подпрограммы приложения пользователя.
Гистограмма использования CPU (CPU Usage Histogram) показывает загрузку одновременно работающих процессоров (CPUs). Она предназначена для параллельных кодов.
Дополнительную информацию можно увидеть, щелкнув на вкладках Bottom-up или Top-down Tree.
Двойной щелчок на строке с именем функции на вкладке Bottom-up приведет к исходному коду приложения и покажет использование CPU относительно отдельных строк. Это укажет на области, на которых следует сфокусировать усилия по оптимизации приложения.
После модификации кода и запуска приложения можно сравнить результаты, полученные до и после оптимизации.
Для этого удобнее воспользоваться GUI
amplxe-gui &Затем в открывшемся окне нажать на кнопку меню ≡, выбрать пункт New/Compare Results..., указать нужные файлы и нажать кнопку Compare.
Опробовать Intel VTune Amplifier можно на примере приложения ray-tracer с именем tachyon из каталога /opt/intel/vtune_amplifier_xe/samples/en/C++.
Соответствующий файл tachyon_vtune_amp_xe.tgz следует
1) скопировать в свой домашний каталог,
2) распаковать архиватором tar
tar zxf tachyon_vtune_amp_xe.tgz3) получить исполняемый файл tachyon_find_hotspots, выполнив команду
make4) запустить его на кластере из текущего рабочего каталога
srun ./tachyon_find_hotspotsдля получения baseline (показателя производительности), с которым в дальнейшем будет проводиться сравнение.
В данном примере это строка вида
CPU Time: 15.211 seconds.Заметим, что диагностика Can't open X11 display выдается, поскольку задача выполняется на вычислительном узле.
5) далее можно перейти к профилировке программы tachyon_find_hotspots на кластере, как описано выше.
Использование Intel® Advisor XE
Intel® Advisor XE предназначен помочь в достижении максимальной производительности Fortran, C и C ++ приложений, упрощая и улучшая параллелизацию вычислений.
Intel Advisor XE объединяет 2 инструмента оптимизации кода:
1) Vectorization Advisor – инструмент векторизации кода.
Vectorization Advisor позволяет идентифицировать циклы, которые в наибольшей степени выиграют от векторизации; определить, что блокирует (мешает) эффективную векторизацию; исследовать преимущества альтернативной реорганизации данных и повысить уверенность в том, что векторизация безопасна. Vectorization Advisor не только показывает расширенные (по сравнению с компилятором) отчеты по оптимизации, делая это удобным для пользователя способом, но и выдает рекомендации по оптимизации.
2) Threading Advisor – инструмент проектирования многопоточного кода.
Threading Advisor позволяет анализировать, проектировать, настраивать и проверять варианты проектирования потоков без реальной модификации программы.
Intel Advisor XE позволяет запустить удаленный анализ приложения на вычислительном узле кластера, используя интерфейс командной строки (CLI), а именно команду advixe-cl, и просмотреть результаты сбора данных на управляющей машине, используя более удобный по сравнению с CLI графический интерфейс (GUI), который вызывается командой advixe-gui. Из главного окна GUI доступна справочная информация для текущей версии (например, из пункта меню Help (?)).
- Начальные действия
- Сбор данных на вычислительном узле
- Просмотр результатов в GUI на хосте
- О примерах
1. Анализ с помощью Advisor XE предназначен для работающих приложений (программ).
Для проведения анализа, прежде всего, следует построить приложение с опциями -g и -O2 (или выше) и проверить его работоспособность.
Замечание. Опция -g используется для запроса полной отладочной информации.
Опция –O[n] задает уровень оптимизации. Для компиляторов Intel при значении -O2 (или выше) возможна векторизация (включены опции –vec и -simd). При этом опция -O2 установлена по умолчанию.
Запускать приложение с Advisor XE следует в том же окружении, т.е. используя ту же команду mpiset (или соответствующий модуль установки переменных окружения).
Для MPI программ следует устанавливать окружение командой
mpiset 8
2. До использования любой из команд advixe-cl или advixe-gui должно быть установлено Intel Advisor XE окружение командой
source /opt/intel/advisor/advixe-vars.sh
Сбор данных на вычислительном узле
Каждому виду оптимизации в Intel Advisor (vectorization/threading) соответствуют определенные этапы анализа приложения, которые объединены в так называемые рабочие процессы (workflows), а именно: Vectorization workflow и Threading workflow. Шаг за шагом выполняя пункты workflows, анализируя возможности распараллеливания кода и оценивая предполагаемую выгоду, пользователь реализует рекомендованные предложения и продвигается в понимании того, что препятствует дальнейшей оптимизации приложения, можно ли её достичь и как.
Подробная информация об этапах анализа приложения приведена в документации Intel, в частности проиллюстрирована в Get Started with Intel Advisor , а также может быть получена по команде
advixe-cl -help workflow
Анализ приложения на кластере следует начать с профилировки (поиска горячих точек) с помощью команды advixe-cl. Запуск её на кластере может иметь вид
srun advixe-cl -collect survey -project-dir ./surv -search-dir src:r=./src -- ./my_appгде-collect survey означает собрать данные с учетом указанного типа анализа (survey);-project-dir ./surv задает каталог surv для записи данных в текущем каталоге;-search-dir src:r=./src обеспечивает доступ к исходным текстам (рекомендуется);./my_app – исполняемый файл приложения в текущем каталоге.
Запуск анализа MPI приложения на 4-х ядрах одного узла осуществляется командой
sbatch myrun.shсо скриптом myrun.sh вида:
#!/bin/bash
#SBATCH -t 30 -n 4 -N 1 -L intel --mem-per-cpu 4950 --input /dev/null --job-name mpi.adv --output output --error errors
/opt/intel/compilers_and_libraries/linux/mpi/bin64/mpirun "advixe-cl" "--collect" "survey" "--project-dir" "./mpi_surv" "--search-dir" "src=./my_src" "--" "./my_mpi_app"Для импорта результатов анализа, полученного например 3 процессом, следует выполнить команду вида:
advixe-cl -project-dir ./mpi_surv_3 -import-dir ./mpi_surv -search-dir src=./my_src -mpi-rank=3Эта команда в текущем рабочем каталоге создает каталог проекта mpi_surv_3, доступный для просмотра в GUI.
Каталоги, задаваемые опцией -project-dir (surv, mpi_surv в примерах выше), – это для собранных данных каталоги верхнего уровня. Результаты для последовательных и OpenMP приложений хранятся в каталоге surv/e000, а для n-го процесса MPI приложения – в каталоге mpi_surv/rank.n. В этих каталогах можно увидеть подкаталоги hsxxx, trcxxx, stxxx, dpxxx и mpxxx в зависимости от использованного типа анализа .
Замечание. Полная информация (синтаксис с примерами) об advixe-cl может быть выдана по команде
advixe-cl -helpУточнить информацию о действии collect позволяет команда
advixe-cl -help collect
Типы анализа:
survey – помогает найти затратные по времени циклы и функции, так называемые «горячие точки» (hotspots), а также дает рекомендации по устранению проблем векторизации и советует, где добавить эффективную векторизацию и/или многопоточность.
tripcounts – собирает статистику по итерациям циклов, что позволяет принять лучшее решение о векторизации одних циклов или о стратегии потоков для других. Этот анализ проводится после survey, т.к. его результаты отражаются в отчете survey.
suitability – предсказывает максимальное ускорение приложения при моделировании многопоточного исполнения. Предсказание строится на основе вставленных аннотаций и ряда параметров моделирования «что-если», с которыми можно экспериментировать для выбора лучших участков при распараллеливании потоками.
dependencies – проверяет зависимости реальных данных в циклах, которые компилятор не векторизовал из-за предполагаемой зависимости, а также предсказывает проблемы совместного использования параллельных данных, базирующихся на вставленных аннотациях. В случае векторизации следует лучше характеризовать зависимости реальных данных, которые могут сделать принудительную векторизацию небезопасной. В случае предполагаемого использования многопоточного распараллеливания исправить проблемы с совместным использованием данных имеет смысл, если прогнозируемая выгода от максимального ускорения оправдает усилия.
Для этого типа анализа приложение строится с опциями -g и -O0. Входные данные следует сократить настолько, насколько возможно, чтобы минимизировать время счета.
map (Memory Access Patterns) – для отмеченных циклов проверяет наличие проблем с доступом к памяти, таких как несмежный (non-contiguous) или неединичный (non-unit stride) доступ.
Просмотр результатов в GUI на хосте
Для просмотра результатов проведенного анализа можно выполнить команду вида:
advixe-gui surv &Для удобства команда выполняется с освобождением командной строки (символ &). Использование & необязательно.
После запуска GUI в открывшемся окне следует выбрать Show My Result, после чего появится окно с панелями: Summary (открывается по умолчанию), Survey & Roofline, Refinement Reports, общими для вкладок Vectorization Workflow и Threading Workflow. По умолчанию открываются отчеты для Vectorization Workflow.
Summary показывает метрики программы (затраченное время, количество потоков) и циклов, выигрыш / эффективность векторизации, наиболее затратные по времени циклы, информацию о платформе.
Survey & Roofline детализирует информацию с учетом типа анализа, показывает исходный код, причины отсутствия векторизации циклов и рекомендации по улучшению кода.
Refinement Reports отображает отчет о шаблонах доступа к памяти (non-unit stride, …) и отчет о зависимостях.
Замечание. Можно получить образец с опциями нужной команды amplxe-cl -collect, используя возможность генерации этой команды в GUI. Выбрав нужный тип анализа, в строке Collect нажать на кнопку Get Command Line.
О примерах
Полезно познакомиться с Intel Advisor на предлагаемых разработчиками примерах. В частности, используя Threading Advisor, исследовать возможность распараллеливания кода для создания многопоточного приложения для программы Tachyon (/opt/intel/advisor/samples/en/C++/tachyon_Advisor.tgz).
Для этого надо скопировать её в свой домашний каталог, распаковать архиватором tar, используя команду
tar zxf tachyon_Advisor.tgzи дальше следовать рекомендациям из файла README.
Замечание. Анализ тестовой программы tachyon_Advisor проводится в рамках GUI, а следовательно, на управляющей машине кластера. В данном случае это допустимо, поскольку анализ занимает секунды. Полученный же начальный опыт работы в GUI может в дальнейшем пригодиться при анализе своих результатов, собранных на кластере с помощью команды advixe-cl.
Для погружения в тему, помимо обширной документации Intel, могут оказаться полезными (с поправкой на версию), например, следующие статьи:
1. От последовательного кода к параллельному за пять шагов c Intel® Advisor XE, где достаточно подробно описан и проиллюстрирован поэтапный (Survey Target, Annotate Sources, Check Suitability, Check Dependencies) анализ программы tachyon_Advisor.
2. Новый инструмент анализа SIMD программ — Vectorization Advisor, где пошагово (Survey Target, Find Trip Counts, Check Dependencies, Check Memory Access Patterns) проводится исследование кода на векторизацию.
Использование Intel® Inspector XE
Intel® Inspector XE – инструмент динамического анализа корректности кода, т.е. анализа исполняемого процесса. Inspector XE предназначен для поиска ошибок памяти и проблем, возникающих при взаимодействии потоков, в последовательных и многопоточных приложениях. Инспектировать можно код, написанный на C, C++, C# и Fortran.
Intel® Inspector XE позволяет запустить удаленный анализ на вычислительном узле кластера и просмотреть результаты сбора данных на хосте. Для сбора данных на кластере используется интерфейс командной строки inspxe-cl (Command Line Interface Support). Для просмотра результатов удобно использовать графический интерфейс (GUI), который вызывается командой inspxe-gui.
1. Intel Inspector XE проверяет весь исполненный код и не требует специальной перекомпиляции программ. Тем не менее рекомендуется включать в сборку приложения (его отладочной версии с -O0 или релиза) опцию -g для обеспечения связи исполняемого кода с исходным текстом.
Рекомендуется работать в окружении, устанавливаемом командой
mpiset 82. Для работы инспектора следует установить Intel Inspector XE окружение, выполнив команду:
source /opt/intel/inspector/inspxe-vars.shПримечание.
1. Поиск ошибок памяти (утечки, доступ к неинициализированной памяти и др.) связан с реально возникающими проблемами, поэтому рекомендуется использовать полный набор данных.
2. При поиске ошибок многопоточности (гонки данных, взаимные блокировки и др.) инспектор ищет потенциальные проблемы взаимодействия потоков, поэтому нагрузку на приложение для экономии времени лучше снизить, например уменьшить размер входных данных. При этом в процессе тестирования надо стремиться активизировать разные ветви кода, поскольку будет проанализирован только исполненный код. Так, взаимная блокировка будет найдена, даже если существует только потенциальная возможность её появления в исполнившихся ветках кода. Вот почему проверка потоков иногда сообщает об ошибках в программе, даже если программа выдает (имеет) правильный вывод.
Запуск Intel Inspector на вычислительном узле
Выполнение анализа инициируется командой inspxe-cl с указанием действия collect (сбор данных). Запустить её на кластере можно с помощью команд srun, sbatch или mqrun (см. Запуск задач на кластере). Например для последовательной программы (-n 1):
mqrun -n 1 inspxe-cl -collect mi1 -search-dir all:r=../ -- ./appгде
действие -collect mi1 означает собрать данные об ошибках памяти с учетом типа анализа mi1;
опция -search-dir all:r=../ задает родительский каталог в качестве начального для рекурсивного (r) поиска всех (all) типов файлов (bin, src, sym);app – исполняемый файл приложения в текущем рабочем каталоге (./).
Основные типы анализа:mi1 Detect Leaksmi2 Detect Memory Problemsmi3 Locate Memory Problemsti1 Detect Deadlocksti2 Detect Deadlocks and Data Racesti3 Locate Deadlocks and Data Races
Рекомендуется начать с первого уровня анализа (mi1, затем ti1), который характеризуется очень низкими накладными расходами (см. Collecting Result Data from the Command Line).
Замечания.
1. Для доступа к текущей документации о команде inspxe-cl следует набрать
inspxe-cl -helpУточнить информацию о действии collect позволяет команда
inspxe-cl -help collect2. Можно получить копию команды inspxe-cl -collect, которая будет выполнена в графическом интерфейсе Intel Inspector. Для этого, после вызова GUI:
inspxe-gui &создать, например, проект (выполнив New Project...), затем в главном окне выбрать New Analysis..., в открывшемся окне Configure Analysis Type выбрать тип анализа (например, Detect Leaks) и, нажав на кнопку Get Command Line, получить соответствующую команду.
Выдача результатов анализа
Собранные данные по умолчанию записываются в результирующий каталог с именем вида r@@@{at}, где
@@@ - следующий доступный номер для результата в текущем рабочем каталоге, 000 – начальный номер;
{at} – код типа анализа (analysis type).
Результирующий каталог, например r000mi1, содержит результирующий файл с тем же именем и расширением inspxe, например r000mi1.inspxe, а также краткий (суммарный, Summary) отчет в файле inspxe-cl.txt.
Краткий отчет включает общее число проблем, их типы, время старта и окончания анализа.
Замечание. Используя опцию -result-dir в команде inspxe-cl -collect, можно задать свой результирующий каталог. При этом к его имени можно приписать до 5-и знаков @. Это удобно в скриптах: не надо будет обновлять имя каталога каждый раз.
После каждого анализа следует посмотреть краткий отчет в файле inspxe-cl.txt. Если обнаружены проблемы, то можно открыть результат для визуализации в GUI или использовать команду inspxe-cl -report для генерации отчетов одного или более типов из полученного результата. Подробнее о команде см.:
inspxe-cl -help report
Для просмотра результатов проведенного анализа в GUI можно выполнить команду inspxe-gui с указанием результирующего каталога, например:
inspxe-gui r000mi1 &или выполнить вызов GUI:
inspxe-gui &и в открывшемся окне, выбрав Open Result, перейти в каталог с результатами анализа и открыть соответствующий файл, например файл r000mi1.inspxe в каталоге r000mi1.
Работа с MPI (ссылки)
- И.Евсеев MPI для начинающих.
- Вл.В.Воеводин Лекция об MPI.
- M.Snir, S.Otto, S.Huss-Lederman, D.Walker, J.Dongarra MPI: The Complete Reference (англ.)
- MPI-2: Extensions to the Message-Passing Interface (параллельный ввод-вывод) (англ.)