Разделы
Центр коллективного пользования
Центр коллективного пользования ИММ УрО РАН «Суперкомпьютерный центр ИММ УрО РАН» (СКЦ ИММ УрО РАН)
СКЦ ИММ УрО РАН действуют на базе двух структурных научных подразделений ИММ УрО РАН (отдел вычислительной техники и отдел системного обеспечения). Деятельность СКЦ ИММ УрО РАН регламентируется Положением о центре, планами работы, приказами директора ИММ УрО РАН. СКЦ ИММ УрО РАН работает в режиме вычислительного центра коллективного пользования. Главное направление деятельности СКЦ ИММ УрО РАН - решение фундаментальных и прикладных ключевых задач, обусловливающих научно-технический прогресс в экономике и бизнесе и ведущих к получению новых знаний и информации.
Базовая организация: Федеральное государственное бюджетное учреждение науки Институт математики и механики им. Н. Н. Красовского Уральского отделения Российской академии наук (сайт); адрес: 620108, Российская Федерация, г. Екатеринбург, ул. Софьи Ковалевской, д. 16.
Руководитель: заведующий отделом системного обеспечения Игумнов Александр Станиславович, телефон: +7 (343) 375-35-11; e-mail: parallel@imm.uran.ru.
Уникальная установка суперкомпьютер "Уран" расположена по адресу: Екатеринбург, ул. Софьи Ковалевской, д. 16.
Перечень оборудования СКЦ ИММ УрО РАН
Образец заявки на регистрацию пользователей
Интерактивная форма подачи заявок
Методики измерений, применяемые в ЦКП - не применимо к услугам СКЦ ИММ УрО РАН.
Как ссылаться на центр коллективного пользования
В публикациях по проектам, выполненным с использованием СКЦ ИММ УрО РАН, необходимо давать ссылки на соответствующие вычислительные ресурсы, например, включив в них фразу:
«При проведении работ был использован суперкомпьютер «Уран» ИММ УрО РАН».
Для англоязычных публикаций можно использовать формулировку подобную этой:
«Computations were performed on the Uran supercomputer at the IMM UB RAS».
Положение о Суперкомпьютерном центре ИММ УрО РАН
В документах, расположенных на данной странице, находятся сканы приказов о создании вычислительного Центра коллективного пользования научным оборудованием ИММ УрО РАН и утвержденное положение о суперкомпьютерном центре ИММ УрО РАН.
| Прикрепленный файл | Размер |
|---|---|
| 3.03 МБ | |
| 2.09 МБ | |
| 285.85 КБ | |
| 2.21 МБ |
План работы СКЦ ИММ УрО РАН
Текущая загрузка суперкомпьютера "Уран"
План работы на 2025 год
| Организация | Примечания | Способ распределения ресурсов |
|---|---|---|
| ИММ УрО РАН | Разделяемый и выделенный | |
| ИГФ УрО РАН | По договору | Разделяемый |
| ИЭФ УрО РАН | По договору | Разделяемый |
| ИФМ УрО РАН | По договору | Разделяемый |
| ИМ УрО РАН | По договору | Разделяемый |
| ИХТТ УрО РАН | По договору | Разделяемый |
| ИМЕТ УрО РАН | По договору | Разделяемый |
| ИВТЭ УрО РАН | По договору | Разделяемый |
| ГИ УрО РАН | По договору | Разделяемый |
| ИМСС УрО РАН | По договору | Разделяемый |
| ИМАШ УрО РАН | По договору | Разделяемый |
| ИТФ УрО РАН | По договору | Разделяемый |
| Студенты | Аспиранты ИММ УрО РАН и магистры совместной с ИММ УрО РАН кафедры УрФУ |
Разделяемый |
| УрФУ | Сотрудники УрФУ совместной с ИММ УрО РАН кафедры | Разделяемый |
| Коммерческие договоры | Не более 10% в пересчете на процессорное время | Разделяемый и выделенный |
| Тех. обслуживание | Не более 25% в пересчете на процессорное время | Выделенный |
Примечание:
“Разделяемый способ распределения ресурсов” – совместное
использование ресурса несколькими пользователями и динамическое планирование
ресурсов по алгоритмам системы запуска задач;
“Выделенный способ распределения ресурсов” – выделение части
ресурсов кластера в единоличное пользование пользователю или группе
пользователей.
Правила конкурсного отбора заявок
В соответствии с регламентом доступа к ресурсам центра коллективного пользования научным оборудованием ИММ УрО РАН «Суперкомпьютерный центр ИММ УрО РАН» план работы ЦКП формируется на основе поступающих заявок. По ним на каждый год составляется расписание работы ЦКП. Заявки могут быть поданы как в бумажном, так и в электронном виде. За рассмотрение заявок отвечает руководитель ЦКП. Полученные заявки должны быть рассмотрены в срок не более двух недель с момента поступления заявки.
При рассмотрении заявок принимаются во внимание: содержательная часть работы, научная значимость и актуальность задачи, степень соответствия заявки возможностям оборудования ЦКП, запрашиваемое время работы оборудования, поддержка молодых ученых. По результатам рассмотрения заявок руководитель ЦКП принимает решение о возможности заключения с пользователем договора на проведение научных работ и оказание услуги и включает заявку в план работ. Решение о невозможности заключения договора должно быть мотивированным и доведено до сведения пользователя не позднее десяти дней со дня принятия такого решения. Научные подразделения ИММ УрО РАН получают допуск к работе с использованием вычислительных ресурсов без заключения договоров на основании заявки.
Перечень причин для отклонения заявки.
- Отсутствие технической возможности исполнить заказ центром коллективного пользования.
- Неисполнение, ненадлежащее исполнение условий договора заказчиком.
Решение и мотивация о невозможности выполнения заявки доводятся до сведения пользователя не позднее десяти дней со дня его принятия.
Регламент доступа
Регламент доступа к ресурсам центра коллективного пользования научным оборудованием ИММ УрО РАН «Суперкомпьютерный центр ИММ УрО РАН»
Порядок выполнения работ и оказания услуг при проведении научных исследований; порядок осуществления экспериментальных разработок в интересах третьих лиц.
Центр коллективного пользования «Суперкомпьютерный центр ИММ УрО РАН» (далее - ЦКП) не имеет статуса юридического лица. ЦКП представляет собой научно-организационную структуру, обладающую современным научным оборудованием, высококвалифицированными кадрами и обеспечивающую на имеющемся оборудовании проведение научных исследований и оказание услуг, в том числе в интересах внешних пользователей (физических лиц и сторонних организаций).
Вычислительную, телекоммуникационную и информационную базу ЦКП составляют высокопроизводительные вычислительные системы, структурированная локальная информационно-вычислительная сеть, информационные и вспомогательные серверы.
Перечень типовых услуг, оказываемых заявителям с использованием оборудования ЦКП, представлен на официальном сайте ЦКП.
Использование оборудования ЦКП при проведении заявителями, указанными в пункте 4.4 Положения о центре коллективного пользования научным оборудованием ИММ УрО РАН, фундаментальных и прикладных научных исследований в рамках утвержденного государственного задания организуется и осуществляется на конкурсной основе безвозмездно на основании договоров безвозмездного оказания услуг доступа к ресурсам центра коллективного пользования научным оборудованием ИММ УрО РАН «Суперкомпьютерный центр ИММ УрО РАН».
Использование оборудования ЦКП в интересах внешних заявителей при проведении прикладных исследований реализуется на возмездной основе в соответствии с договором оказания услуг предоставления ресурсов Центра коллективного пользования научным оборудованием ИММ УрО РАН «Суперкомпьютерный центр ИММ УрО РАН». Стоимость оказания услуг ЦКП в этом случае определяется фактическими затратами, необходимыми для выполнения работ.
Права на результаты интеллектуальной деятельности, получаемые в ходе проведения научных исследований и оказания услуг принадлежат заявителям, в отдельных случаях права на результаты интеллектуальной деятельности, регулируются договором между базовой организацией и заявителем.
Условия допуска к работе с использованием вычислительных ресурсов ЦКП
План работы ЦКП формируется на основе поступающих заявок. По ним на каждый год составляется расписание работы ЦКП.
Заявки могут быть поданы как в бумажном, так и в электронном виде. За рассмотрение заявок отвечает руководитель ЦКП. Полученные заявки должны быть рассмотрены в срок не более двух недель с момента поступления заявки.
При рассмотрении заявок принимаются во внимание: содержательная часть работы, научная значимость и актуальность задачи, степень соответствия заявки возможностям оборудования ЦКП, запрашиваемое время работы оборудования, поддержка молодых ученых.
По результатам рассмотрения заявок руководитель ЦКП принимает решение о возможности заключения с пользователем договора на проведение научных работ и оказание услуги и включает заявку в план работ. Решение о невозможности заключения договора должно быть мотивированным и доведено до сведения пользователя не позднее десяти дней со дня принятия такого решения. Научные подразделения ИММ УрО РАН получают допуск к работе с использованием вычислительных ресурсов без заключения договоров на основании заявки.
Перечень причин для отклонения заявки.
- Отсутствие технической возможности исполнить заказ центром коллективного пользования.
- Неисполнение, ненадлежащее исполнение условий договора заказчиком.
Решение и мотивация о невозможности выполнения заявки доводятся до сведения пользователя не позднее десяти дней со дня его принятия.
Стоимость вычислительных услуг
Вычислительные услуги предоставляются на основе договора, заключаемого в соответствии с Положением о центре коллективного пользования ИММ УрО РАН от 18.01.2016.
Стоимость вычислительных услуг (без учета НДС) в 2026 году:
- Одной GPU-карты типа Tesla M2090 - 13,2 руб*час
- Одной GPU-карты типа Tesla K40 - 35,2 руб*час
- Одной GPU-карты типа Tesla V100 - 105,6 руб*час.
- Одной GPU-карты типа Tesla A100 - 158,4 руб*час.
- Ядро CPU - 1,76 руб*час.
При выделении вычислительных узлов в монопольное использование, плата взимается за все вычислительные ресурсы, физически размещенные на этих узлах, вне зависимости от их фактической загрузки.
Правила использования кластера
- Пользователь получает логин (учетную запись) и пароль доступа по заявке от организации на основании заключенного договора доступа к ресурсам СКЦ ИММ УрО РАН.
- Полученный логин должен использоваться только лицом, указанным в заявке, и только для решения задач, указанных в заявке. При выявлении нецелевого использование вычислительных ресурсов администратор кластера блокирует доступ к учетной записи до устранения нарушений.
- В случае изменения регистрационных данных (изменение контактной информации и т.п.) пользователь обязан сообщить об этом администратору кластера в течение 5 рабочих дней по адресу otchet-par@list.uran.ru, а также оформить в течение месяца новую заявку на регистрацию пользователя.
- Объём хранилища данных в СКЦ ИММ УрО РАН для каждого пользователя ограничивается 100 GB (см. Ограничения по ресурсам). Если для работы необходимы большие ресурсы, пользователь должен согласовать их выделение с администратором кластера.
- В публикациях по проектам, выполненным с использованием СКЦ ИММ УрО РАН, необходимо давать ссылки на соответствующие вычислительные ресурсы, например, включив в них фразу: «При проведении работ был использован суперкомпьютер «Уран» ИММ УрО РАН». Для англоязычных публикаций можно использовать формулировку подобную этой: «Computations were performed on the Uran supercomputer at the IMM UB RAS».
- Ежегодно в ноябре месяце организация, заключившая договор на длительный срок, должна предоставить заявку для перерегистрации учетных записей на следующий календарный год и краткий отчет о проведенных исследованиях, выполненных с использованием СКЦ ИММ УрО РАН в текущем году. Требования к отчёту представлены на сайте.
- При необходимости проведения расчетов в коммерческих целях (например, вне программ и проектов по государственному заданию) организация должна подать заявку на заключение договора возмездного оказания услуг доступа к ресурсам СКЦ ИММ УрО РАН.
Заявка на регистрацию пользователей
ЗАЯВКА ОФОРМЛЯЕТСЯ НА БЛАНКЕ ОРГАНИЗАЦИИ
Директору ИММ УрО РАН
Н. Ю. Лукоянову
Заявка на регистрацию потребителя ИТ-Услуг на 20.. год
к договору безвозмездного оказания услуг доступа к ресурсам центра коллективного пользования научным
оборудованием ИММ УрО РАН «Суперкомпьютерный центр ИММ УрО РАН»
№_____ от «__»_________201__ г.
________Название организации_______ просит предоставить доступ к вычислительным ресурсам Федерального государственного бюджетного учреждения науки Института математики и механики им. Н.Н. Красовского Уральского отделения Российской академии наук следующим сотрудникам нашей организации (института):
1. Источник финансирования ________________
___список пользователей, контактный телефон, e-mail каждого пользователя___
С использованием ресурсов СКЦ ИММ УрО РАН планируется решение задач, предусмотренных государственным заданием_____общее описание круга решаемых задач с ожидаемыми результатами от использования вычислительных ресурсов.
2. Источник финансирования ________________
___список пользователей, контактный телефон, e-mail каждого пользователя___
С использованием ресурсов СКЦ ИММ УрО РАН планируется решение задач, предусмотренных государственным заданием_____общее описание круга решаемых задач с ожидаемыми результатами от использования вычислительных ресурсов.
3. и т.д.
При отсутствии у пользователей опыта работы с вычислительной техникой такого уровня требуется проинформировать о необходимости заключения отдельного договора по организации курса обучения___.
Директор _____подпись_________ /_расшифровка подписи_/
__________________________________________________
ВНИМАНИЕ!!!
1. Заявка оформляется на бланке организации.
2. Список пользователей необходимо сгруппировать по источникам финансирования.
3. Пользователь может быть включен в несколько групп.
4. Источник финансирования: регистрационный номер НИОКТР в https://www.rosrid.ru/ и наименование НИОКТР, по которому финансируется работа.
В случае изменения сведений, указанных в заявке, в течение срока действия договора должна быть подана новая заявка, оформленная надлежащим образом.
Данное письмо отправить:
-
По адресу 620108, г. Екатеринбург, ул. Софьи Ковалевской, 16. Копия может быть отправлена по факсу: (343)374-25-81 - это основная заявка.
-
Электронный вариант письма в формате Word (текст) по адресу parallel@imm.uran.ru - информация для администратора.
Проект договора на предоставление услуг ЦКП
На этой странице вы можете скачать PDF файл с проектом договора на предоставление вычислительных услуг суперкомпьютерного центра коллективного пользования УрО РАН.
| Прикрепленный файл | Размер |
|---|---|
| 2.7 МБ |
Требования к отчету об использовании вычислительных ресурсов
Отчетные материалы предоставляются один раз в год не позднее 20 ноября отчетного года от групп пользователей, работающих над одной темой, объединяются в один файл отчета от организации.
Содержание отчета по отдельному проекту (НИР), выполненному с участием центра коллективного пользования:
- ТИТУЛЬНЫЙ ЛИСТ оформляется на первой странице отчета, информация по НИР – со второго листа отчета.
- Наименование НИР совпадает с НИОКТР, зарегистрированной в домене гиснаука.рф (https://xn--80aahulq1as.xn--p1ai/). Наименование НИР может отличаться от наименования НИОКТР, если выполненная работа является частью НИОКТР.
- Руководитель НИОКТР с указанием ФИО, должности, ученой степени.
- Список участников проекта с указанием ФИО, должности, ученой степени каждого участника.
- Заказчик - информация из домена гиснаука.рф (https://xn--80aahulq1as.xn--p1ai/).
- Источник финансирования: регистрационный номер НИОКТР, зарегистрированный в домене гиснаука.рф (https://xn--80aahulq1as.xn--p1ai/) и наименование НИОКТР, по которому финансируется работа.
- Приоритетное направление развития науки, технологий и техники в РФ в соответствии с Указом Президента Российской Федерации в редакции от 16.12.2015 г. № 623 ( http://www.kremlin.ru/acts/bank/33514 ).
- Направление фундаментальных исследований в соответствии с Программой фундаментальных научных исследований на 2021-2030 годы (https://docs.cntd.ru/document/573319222?marker=64U0IK ).
- Направление исследования в соответствии с классификатором РНФ (https://rscf.ru/contests/classification).
- Критическая технология РФ утверждена Президентом Российской Федерации 7 июля 2011 г., Пр-N 899 ( http://www.kremlin.ru/acts/bank/33514).
- Приоритетные направления научно-технологического развития в РФ в соответствии с Указом Президента РФ от 18 июня 2024 г. № 529 "Об утверждении приоритетных направлений научно-технологического развития и перечня важнейших наукоемких технологий" (http://publication.pravo.gov.ru/document/0001202406180018 ?index=1).
- Важнейшие наукоемкие технологии: критические технологии и сквозные технологии в соответствии с Указом Президента РФ от 18 июня 2024 г. № 529 "Об утверждении приоритетных направлений научно-технологического развития и перечня важнейших наукоемких технологий" (http://publication.pravo.gov.ru/document/0001202406180018 ?index=1)
- Описание результатов работы по проекту за год в доступной форме - 2-3 абзаца.
- 2-3 ярких, показательных иллюстрации работы (картинки/схемы/графика/фото, если таковые имеются), которые необходимо вставить в текст, а также представить в виде отдельных графических файлов высокого качества.
Имя файла: Отчет_<сокращенное название института>_<наименование НИР>_<номер рисунка по теме>.jpg. - (По желанию) Краткая, не более половины страницы, аннотация работы на английском языке .
- Список публикаций, в которых есть ссылки на то, что при работе по проекту был использован суперкомпьютер «Уран» ИММ УрО РАН (за текущий год по данному проекту), в формате: № п/п |Наименование|DOI публикации|Авторы|Издание(полная библ. информация)| ISSN издания| IF и номер квартиля в Web of Science | IF в SCOPUS | ИФ в РИНЦ| Уровень в «Белом списке» научных журналов| ВАК РФ| Аннотация.
Сокращения:
DOI публикации - цифровой идентификатор публикации;
ISSN - уникальный идентификатор периодического издания;
ИФ или IF (импа́кт-фа́ктор) — численный показатель важности научного журнала;
Уровень в «Белом списке» научных журналов - для определения воспользуйтесь ссылкой https://journalrank.rcsi.science/ru/
Для списка публикаций со ссылкой на использование суперкомпьютера «Уран» ИММ УрО РАН при работе по проектам за текущий год есть 2 таблицы.
Таблицу 1 заполнять обязательно.
Просьба: заполнить Таблицу 2, если у вас есть данные IF Scopus и Web of Science. - Сканы статей, указанных в списке публикаций по данной НИР, сделанные со страниц журнала, необходимо представить отдельными файлами в формате pdf. При отсутствии на странице названия журнала необходим скан титульного листа журнала.
- Список дипломных работ, защищенных кандидатских и докторских диссертаций в текущем году, подготовленных с использованием вычислительных средств СКЦ ИММ УрО РАН, в формате: Присвоенное звание | ФИО| Место работы| Должность| Возраст на момент защиты| Название работы| Дата защиты| Краткое описание полученных результатов.
- Список патентов, свидетельств на программу для ЭВМ и т.п., полученных по результатам работ, проведенных с использованием оборудования вычислительных средств СКЦ ИММ УрО РАН, в формате: № п/п | № в ЕГИСУ НИОКТР | Вид РИД |Авторы (ФИО, место работы, должность) | Реквизиты охранного документа (правообладатель, вид документа, номер, дата),
где РИД-результат интеллектуальной деятельности.
| Прикрепленный файл | Размер |
|---|---|
| 126 КБ |
Задачи, решаемые на кластере "Уран"
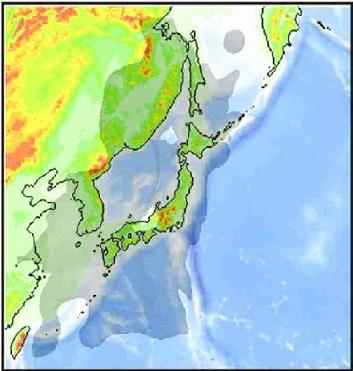
Моделирование задач геофизики на суперкомпьютере "Уран"
А.И. Короткий (1,2), И.А. Цепелев (1), А. Исмаил-заде (3,4), С. Хонда (5)
(1) Институт математики и механики УрО РАН, Екатеринбург, РОССИЯ
(2) Уральский федеральный университет, Екатеринбург, РОССИЯ
(3) Geophysikalisches Institut, Universitat Karlsruhe, GERMANY
(4) Institut de Physique du Globe de Paris, Paris, FRANCE
(5) Earthquake Research Institute, University of Tokyo, Tokyo, JAPAN
Цель исследования
Задача реконструкции внутреннего строения Земли состоит в качественной и количественной идентификации строения Земли и ее отдельных регионов на основе интерпретации геолого-геофизических данных (теплового, гравитационного, электромагнитного полей, сейсмичности, палео- и современной геодинамики). Моделирование данной задачи проводится в прямом и обратном временах. Для решения задач необходимо создание математических моделей глобальных процессов, проведение численных экспериментов на детальных расчетных сетках, установление соответствия построенных моделей результатам геодезических и геофизических измерений современного состояния и динамики земных недр. Для эффективной компьютерной реализации требуется использование суперкомпьютеров большой мощности.
Моделирование геофизических процессов на ЭВМ позволит получить фундаментальные знания в области реконструкции физических параметров, обоснования и численного решения задач прогнозирования и оценки параметров геологических систем. Использование ЭВМ в этом направлении приведет к реальному сокращению затрат на эти исследования...
| Прикрепленный файл | Размер |
|---|---|
| 1.34 МБ | |
| 4.28 МБ |
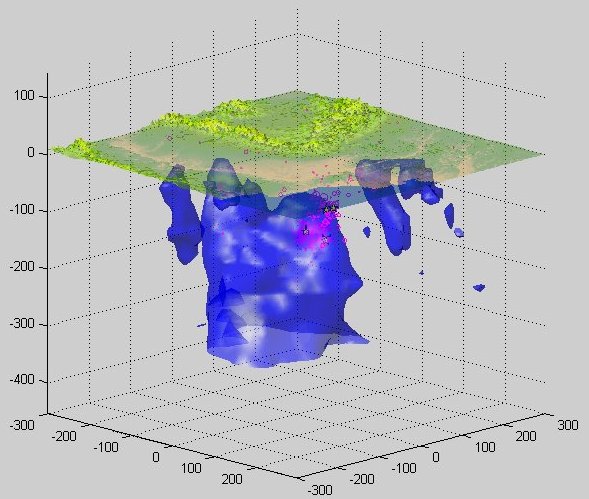
Моделирование погружения осколка континентальной плиты в районе юго-восточных Карпат
А.И.Короткий (1,2), И.А.Цепелев (1), А.Т.Исмаил-заде (3,4), Дж.Шуберт (5)
(1) Институт математики и механики УрО РАН, Екатеринбург, РОССИЯ
(2) Уральский федеральный университет, Екатеринбург, РОССИЯ
(3) Geophysikalisches Institut, Universitat Karlsruhe, GERMANY
(4) Institut de Physique du Globe de Paris, Paris, FRANCE
(5) Institute of Geophysics and Planetary Physics, University of California, USA
Основные научные цели исследования:
на основе обработки реальных геолого-физических данных для географического региона юго-восточных Карпат исследовать эволюцию погружения тектонической плиты в заданной области, изучить механизмы образования тектонических напряжений в коре Земли, которые приводят к землетрясениям в данном регионе.
| Прикрепленный файл | Размер |
|---|---|
| 1.44 МБ |
Компьютерное моделирование стеклования в системе коллапсирующих сфер
Р.Е. Рыльцев1, Н.М. Щелкачев1,2, В.Н. Рыжов3
1 – Институт Металлургии УрО РАН
2 – Институт теоретической физики им. Л.Д. Ландау
3 – Институт физики высоких давлений им. Л.Ф. Верещагина
Получение аморфных материалов с заданными свойствами является важнейшей практической задачей. Ее решение невозможно без всестороннего изучения физических процессов и механизмов стеклования, что обуславливает также и фундаментальный интерес к данной проблеме. В силу отсутствия строгой теории и сложности аналитического описания процесса стеклования основным инструментов теоретического исследования здесь является компьютерное моделирование методом молекулярной динамики.
Основной целью данной работы является исследования стеклования методами молекулярной динамики. Решение этой задачи требует больших затрат машинного времени в силу необходимости рассматривать большие системы и по причине медленной релаксации системы в окрестности температуры стеклования. Это заставляет искать оптимальные модельные системы, которые должны быть достаточно простыми, но вместе с тем описывать свойства некоторого класса конкретных систем. Одной из таких систем является система коллапсирующих сфер, описываемых эффективным парным потенциалом с отрицательной кривизной в области отталкивания. Такие потенциалы используются в качестве простейших моделей систем с направленными связями типа воды, кремнезема и др.
Проведено компьютерное моделирование структурных и динамических свойств системы коллапсирующих сфер. Впервые для однокомпонентных систем с изотропными потенциалами обнаружено стеклование при квазиравновесном охлаждении, сопровождающееся рекордно большими отклонениями температурных зависимостей транспортных коэффициентов от закона Аррениуса. Найденная зависимость температуры стеклования от плотности имеет аномальный немонотонный характер, что объясняется квазибинарным поведением системы. Полученные результаты дают вклад в развитие общей теории стеклования, которая является фундаментальной основой для технологий изготовления аморфных сплавов и композитных нанокристаллических материалов с заданными свойствами.
| Прикрепленный файл | Размер |
|---|---|
| 497.73 КБ | |
| 3.17 МБ | |
| 363.94 КБ |
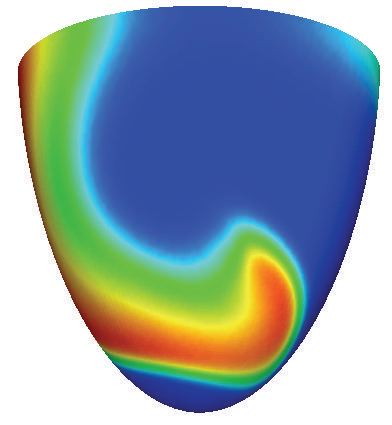
Моделирование свитковых волн электрического возбуждения в сердце
 С.Ф.Правдин (1,2), А.В.Панфилов (3)
С.Ф.Правдин (1,2), А.В.Панфилов (3)
(1) Институт математики и механики УрО РАН, Екатеринбург, РОССИЯ
(2) Уральский федеральный университет, Екатеринбург, РОССИЯ
(3) Universiteit Gent, BELGIE
Основные научные цели исследования:
Изучить динамику трёхмерных свитковых волн электрического возбуждения в миокарде левого желудочка сердца, характерных для пароксизмальной тахикардии, в зависимости от толщины сердечной стенки, степени анизотропии миокарда, трансмурального угла вращения волокон и направления вращения волны. Выяснить условия распада волны (break-up), соответствующего переходу тахикардии в фибрилляцию желудочков.
В расчетах используется реалистичная ионная модель электрофизиологии кардиомиоцита "TNNP".
Кластер "Уран"
| Имя | Год | Кол-во ядер |
Процессор | Объем ОП |
Сеть | ОС | Пиковая производи- тельность (Tflop/s) |
Тест Linpack (Tflop/s) |
|---|---|---|---|---|---|---|---|---|
| "Уран" | 2008-2021 | 1734 CPU 149 GPU m2090 18 GPU k40m 8 GPU v100 (01.2021) |
Intel Xeon (2.2-3.1 ГГц) NVIDIA Tesla |
15 ТБ | Infiniband, GiEthernet |
Linux |
CPU 44.3 GPU 206.2 |
105.36 |
Адрес кластера "Уран" umt.imm.uran.ru

Аннотация
Суперкомпьютер «Уран» собран на базе Blade серверов фирмы Hewlett-Packard. Он состоит из 81 вычислительного узла, которые установлены в модулях с высокой плотностью упаковки.
Вычислительные узлы оснащены процессорами Intel Xeon, работающими на частотах 2.2-3.1 ГГц, 48-384 гигабайтами оперативной памяти и графическими ускорителями NVIDIA Tesla.
В общей сложности пользователям доступно 1542 вычислительных ядра CPU, 167 платы GPU и 13 Тбайт оперативной памяти. Система хранения суперкомпьютера «Уран» позволяет разместить до 140 Тбайт данных.
Для передачи данных между вычислительными узлами используется высокоскоростные сети Infiniband с пропускной способностью 20 Гбит/с и 100 Гбит/с. Доступ к суперкомпьютеру «Уран» осуществляется через городскую сеть УрО РАН в Екатеринбурге по технологии 10Gi Ethernet со скоростью 10 Гбит/c.
Для проведения научных и инженерных расчетов на суперкомпьютере установлено базовое программное обеспечение, включающее:
- Операционная система Linux;
- Система запуска задач Slurm;
- Языки программирования C, C++, Fortran;
- Компиляторы Intel, GNU, PGI;
- Библиотека Math Kernel Library (MKL) Intel;
- Реализации MPI: OpenMPI и MVAPICH2;
- Пакеты Matlab, ANSYS CFX Academic Research.
По заявкам пользователей на суперкомпьютере могут быть установлены компиляторы, библиотеки и пакеты программ, свободно распространяемые научным сообществом.
Краткое описание кластера
Кластер выполнен на базовых блоках (ББ) фирмы Hewlett-Packard . Каждый базовый блок объединяет вычислительные и коммуникационные модули.
Вычислительные узлы
Используются узлы нескольких типов, которые образуют основные разделы (partition) кластера. Внутри разделов (кроме debug) узлы связаны между собой высокоскоростной сетью Infiniband. Узлы разных разделов связаны между собой 1 Гбит/c Ethernet.
Раздел hiperf
1 узел tesla-v100 (2020.01)
- два 18-и ядерных процессора Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz;
- оперативная память 384 GB;
- 8 GPU Nvidia Tesla V100 (32 ГБ Global Memory)
1 узел tesla-a100 (2022.06)
- два 24-х ядерных процессора Intel(R) Xeon(R) Gold 6240R CPU @ 2.40GHz;
- оперативная память 376 GB;
- 8 GPU Nvidia Tesla A100 (40 ГБ Global Memory)
1 узел tesla-a101 (2022.09)
- два 12-и ядерных процессора Intel(R) Xeon(R) Gold 6246 CPU @ 3.30GHz;
- оперативная память 251 GB;
- 2 GPU Nvidia Tesla A100 (40 ГБ Global Memory)
Раздел apollo
16 узлов apollo[1-16] (2017.02)
- два 18-и ядерных процессора Intel(R) Xeon(R) CPU E5-2697 v4 @ 2.30GHz;
- оперативная память 256 GB;
- кэш-память 45 MB SmartCache;
- локальный жесткий диск 1 TB
20 узлов apollo[17-36] (6 — 2019.12, 1 — 2020.01, 5 — 2020.01, 4 — 2021.11, 4 — 2022.10 )
- два 18-и ядерных процессора Intel(R) Xeon(R) Gold 6254 CPU @ 3.10GHz;
- оперативная память 384 GB;
Узлы раздела apollo объединены высокоскоростной сетью Infiniband нового поколения 100 Гбит/с.
Раздел all
20 узлов tesla[1-20]
- два 6-и ядерных процессора Intel® Xeon® X5675 (3.07GHz)
- оперативная память 48 GB
- кэш-память 2 x 12 MB Level 2 cache
- локальный жесткий диск 120 GB
10 узлов tesla[21-30]
- два 6-и ядерных процессора Intel® Xeon® X5675 (3.07GHz)
- оперативная память 192 GB
- кэш-память 2 x 12 MB Level 2 cache
- 8 GPU Tesla M2090 (6 ГБ Global Memory)
- локальный жесткий диск 400 GB
13 узлов tesla[33-45]
- два 8-и ядерных процессора Intel® Xeon® E5-2660 (2.2 GHz)
- оперативная память 96 GB
- кэш-память 2 x 20 MB Level 2 cache
- 8 GPU Tesla M2090 (6 ГБ Global Memory)
- локальный жесткий диск 400 GB
5 узлов tesla[48-52]
- два 8-и ядерных процессора Intel® Xeon® E5-2650 (2.6 GHz)
- оперативная память 64 GB
- кэш-память 2 x 20 MB Level 2 cache
- 3 GPU Tesla K40m (12 ГБ Global Memory)
- локальный жесткий диск 400 GB
Узлы раздела all объединены высокоскоростной сетью Infiniband 20 Гбит/с.
Раздел debug
4 узла tesla[31-32,46-47]
- два 8-и ядерных процессора Intel® Xeon® E5-2660 (2.2 GHz)
- оперативная память 96 GB
- кэш-память 2 x 20 MB Level 2 cache
- 8 GPU Tesla M2090 (6 ГБ Global Memory)
- локальный жесткий диск 400 GB
Узлы раздела debug объединены сетью 1 Гбит/c Ethernet.
Коммуникационная счетная среда
В качестве MPI – интерконнекта использована хорошо себя зарекомендовавшая технология Infiniband (IB). В качестве коммутатора IB использован 144 – портовый коммутатор Qlogic 9120.
Коммуникационная среда ввода/вывода
В качестве I/O – интерконнекта использована выделенная сеть Gigabit Ethernet. Сеть имеет двухуровневую структуру. Первый уровень организован на коммутирующих модулях GbE2c Ethernet Blade Switch for HP c-Class BladeSystem, установленных в шасси ББ. К коммутирующему модулю каждого ББ внутренними гигабитными каналами подключены вычислительные модули и модуль управления. Коммутирующий модуль каждого ББ подключен к коммутатору Ethernet HP ProCurve Switch 4208v1-192. К нему подключены все ВМ, порты Host – машин, консоль управления и мониторинга.
Управляющий сервер (HOST- машина)
Управляющий сервер ВС - HP DL180G5 на основе процессоров Intel Xeon 5430.
Управляющий сервер содержит:
- два четырёхъядерных процессора с тактовой частотой 2,6 ГГц;
- 16 ГБ оперативной памяти;
- дисковую подсистему RAID5, состоящую из 5 дисков SATA объемом 500 ГБ каждый ;
- 10/100/1000 Base-T Ethernet интерфейс;
- видеоадаптер, порт USB 2, порты мыши, клавиатуры.
| Прикрепленный файл | Размер |
|---|---|
| 60.64 КБ |
Начинающим
Вычислительные ресурсы для учреждений УрО РАН предоставляются на основе договоров, заключаемых в соответствии с Положение о вычислительном Центре коллективного пользования ИММ УрО РАН от 18.01.2016. Стоимость вычислительных услуг для всех остальных организаций договорная.
Cотрудникам организаций, уже заключивших договор с ИММ УрО РАН, чтобы стать пользователями суперЭВМ, необходимо:
- Ознакомиться с правилами использования вычислительных ресурсов ИММ УрО РАН.
- Оформить заявку на регистрацию пользователей.
- Получить от администраторов login (имя пользователя) и пароль для доступа на серверы.
Для работы на суперЭВМ с персонального компьютера пользователю необходимо установить на компьютере программы, которые обеспечат :
1) удаленный доступ к командной строке сервера для компиляции и запуска задач;
2) возможность обмена файлами между компьютером и сервером;
3) удобный графический интерфейс.
Начинающим пользователям полезно ознакомиться со Схемой работы на кластере.
Схема работы на кластере
Схема работы на кластере проиллюстрирована ниже на примере кластера "Уран" с использованием программ WinSCP и PuTTY (см. Программы удаленного доступа).
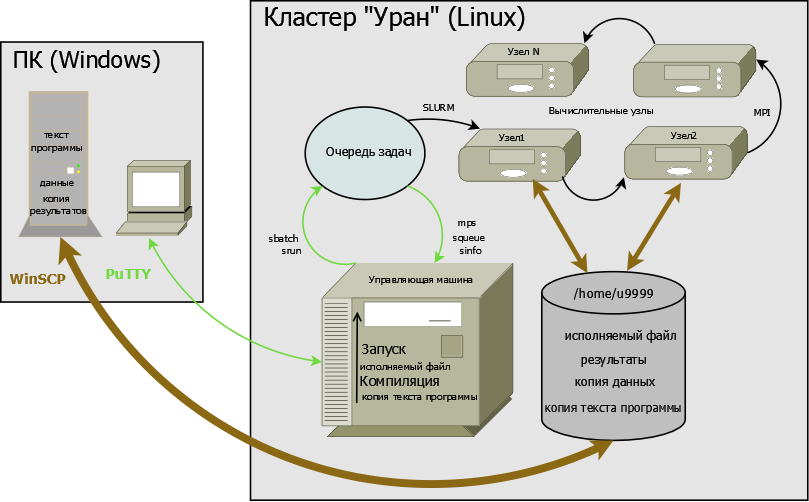
Для вычислений на компьютере или кластере нужен исполняемый файл программы и, как правило, исходные данные. Поскольку на компьютере пользователя обычно установлена операционная система Windows, а на кластере - Linux (разновидность UNIX), то для счета на кластере необходимо получить исполняемый файл с помощью одного из компиляторов кластера. Следовательно, на кластер должен быть переписан текст программы.
Для удаленного копирования файлов используется программа WinSCP.
Пользователь копирует файлы (текст программы, исходные данные) с персонального компьютера в свой домашний каталог на кластере:
на рисунке это копирование в /home/u9999, где u9999 - имя (идентификатор, login) пользователя на кластере.
Компиляция программ и запуск задач на счет осуществляются после входа на кластер через программу удалённого доступа PuTTY. Набирая в окне PuTTY соответствующие команды, пользователь выполняет на управляющей машине (хосте) нужные ему действия, в частности, компиляцию и запуск задач на кластере. При этом запуск задачи осуществляется с помощью постановки её в очередь на счет. Ведением очереди и стартом задач на вычислительных узлах занимается система SLURM. Во время счета параллельные вычислительные процессы задачи могут обмениваться данными по коммуникационной сети и имеют доступ к домашнему каталогу.
Пользователь в любой момент может получить информацию о своих задачах в очереди и о доступных ресурсах кластера.
Ускорение вычислений достигается лишь после преобразования последовательной программы в параллельную, обычно с применением стандартов MPI и OpenMP. Запуск задач на кластере осуществляется с учетом особенностей программ, в частности, с учетом использования MPI и/или OpenMP. Для отладки полезно запустить на кластере последовательный тестовый вариант программы. Так же как параллельные, последовательные (однопроцессные) программы должны запускаться путем постановки в очередь.
Для работы на кластере полезно ознакомиться с базовыми командами ОС UNIX.
Внимание! По правилам пользования вычислительным кластером "Уран" счетные задачи можно запускать лишь на вычислительных узлах кластера, используя команды системы SLURM srun, sbatch или упрощенную команду mqrun (см. раздел Запуск задач на кластере). Такое ограничение связано с тем, что исполняющиеся на хост-машине процессы счетного характера на длительное время занимают процессорные ядра хост-машины, затрудняя работу с кластером всех остальных пользователей.
Вход на кластер по секретному ключу
- Доступ по ключу
- Использование агента аутентификации
- Генерация ключей в UNIX
- Совместное использование ключа и пароля
- Основные ссылки
Для входа на кластер пользователь должен иметь логин (имя пользователя) и для аутентификации (подтверждения подлинности) ключ или пароль (password).
Поскольку использование ключа обеспечивает большую конфиденциальность и дает возможность избавиться от подтверждения пароля для операций типа scp (удалённого копирования файлов), доступ по ключу рассматривается в дальнейшем как более предпочтительный.
Поэтому первоначально, а также при утере пароля или ключа для обеспечения доступа к кластеру необходимо создать ключи, как это описано ниже.
Для входа на кластер из ОС Windows можно воспользоваться программой PuTTY (см. Программы удаленного доступа).
Для организации доступа по ключу требуется выполнить следующую последовательность действий.
1. Сгенерировать и сохранить на своем компьютере приватный (секретный) и публичный ключи,
используя программу PuTTYgen из поставки PuTTY, как проиллюстрировано в инструкции [1]. При этом публичный ключ следует сохранить в файле Блокнота, копируя текст из PuTTYgen: начиная с типа ключа 'ssh-rsa' и заканчивая знаками '==' и комментарием с датой вида 'rsa-key-20150421'.
Секретный ключ рекомендуется зашифровать кодовой фразой (паролем секретного ключа, passphrase) и хранить в безопасном месте.
2. Добавить публичный ключ в файл ~/.ssh.authorized_keys каталога на сервере ( '~’ обозначает домашний каталог пользователя). Пользователь может сделать это самостоятельно (если у него есть доступ на кластер по паролю или другому ключу, см. [1]) или отправить файл с публичным ключом администратору кластера на адрес parallel@imm.uran.ru. Администратор кластера установит публичный ключ и сообщит об этом пользователю.
3. Создать в PuTTY именованную сессию (Session) для работы на кластере с доступом по ключу, для чего вставить путь к секретному ключу в разделе Connection->SSH->Auth, вернуться в раздел Session и, заполнив поля Host Name и Saved Sessions значениями, например umt.imm.uran.ru и umt, сохранить настройки (см. [1]).
После этого работа с кластером может быть инициирована двойным нажатием на имени созданной сессии.
Использование агента аутентификации
Если секретный ключ защищён кодовой фразой (passphrase), то запуск агента аутентификации, программы Pageant из поставки PuTTY (см. инструкцию [2]), избавляет от ввода passphrase при повторном соединении по ключу с кластером на период времени до завершения работы агента.
Pageant можно запустить, например, двойным кликом на секретном ключе и набором его кодовой фразы (если есть). В результате в системной области панели задач (внизу справа ) появится иконка Pageant.
Далее (при каждом входе на кластер) правой кнопкой мыши открываем меню и выбираем для запуска нужную сессию (umt).
В UNIX-системах для генерации ключей используется утилита ssh-keygen,
создающая два файла: ~/.ssh/id_rsa и ~/.ssh/id_rsa.pub (имена по умолчанию),
агент аутентификации запускается с помощью утилиты ssh-agent.
Совместное использование ключа и пароля
Имея доступ по ключу, пользователь при необходимости может запросить пароль у администратора кластера. Администратор создает пароль (password) и кладет его в домашний каталог пользователя, сообщая ему об этом.
Пользователь всегда может изменить пароль командой passwd.
Надо иметь в виду, что при входе на кластер сначала делается попытка пройти аутентификацию по ключу, а в случае неудачи - по паролю.
В PuTTY удобнее иметь разные сессии для доступа по ключу или паролю.
При доступе по паролю вводить password требуется всегда. В случае использования ключа кодовая фраза (passphrase) запрашивается (если есть), но возможно только один раз и возможно для доступа ко многим системам. Поэтому кодовая фраза может быть более сложной, что повышает безопасность, не слишком усложняя работу пользователя.
1. Настройка аутентификации по ключу в PuTTY
2. Работа с агентом аутентификации в PuTTY
Программы удаленного доступа
Для работы на суперЭВМ с персонального компьютера пользователю необходимо установить программы на компьютере, которые обеспечат
удаленный доступ к командной строке сервера для компиляции программ и запуска задач,
возможность обмена файлами между компьютером и сервером
и позволят использовать удобный графический интерфейс.
1. Удаленный доступ к командной строке сервера
Доступ к серверам осуществляется через протокол SSH (собственно SSH – « secure shell »). Для работы с командной строкой рекомендуется программа PuTTY. Эта программа позволяет единожды ввести адрес сервера и, в дальнейшем, выбирать его из списка сессий. В настройках PuTTY необходимо указать протокол SSH. При первом соединении с сервером программа выдает предупреждение о том, что ключ шифрования сервера ранее не использовался, и предлагает его сохранить или отвергнуть (продолжить сеанс или прервать). Естественно надо выбрать продолжение сеанса.
Полезно более подробно ознакомиться с установкой и некоторыми настройками программы PuTTY.
Пример диалога при входе на сервер UM16 с именем xxxxx с компьютера ada.imm.uran.ru:
login as: xxxxx Password: (ввести пароль) Last login: Tue Sep 6 16:31:23 2005 from ada.imm.uran.ru
Вы можете изменить свой пароль в любое время, набрав команду passwd, например:
[~@um16]:passwd Password for xxxxx@IMM.URAN.RU: (наберите здесь свой текущий пароль) Enter new password: (наберите новый пароль) Enter it again: (повторите новый пароль) Password changed. (успешная смена пароля)
Для того чтобы защитить свою учетную запись, придерживайтесь следующих рекомендаций:
- используйте пароль не менее, чем из 6 букв и цифр и храните его в секрете;
- один раз в полгода меняйте свой пароль;
- никогда не оставляйте активный терминал без внимания, всегда выходите (logout) со своего терминала (заканчивайте сеанс) прежде, чем покинуть его;
- обязательно сообщайте о любом неправильном использовании или злоупотреблении системному администратору, иначе доступ к серверу будет закрыт.
Для того, чтобы завершить сеанс работы на сервере, выполните команду logout.
2. Обмен файлами между компьютером и сервером
Для обмена файлами между компьютером и сервером рекомендуется использовать программу WinSCP.
При копировании файлов (протоколы SCP – “secure copy ” и SFTP – “ secure ftp ”) в настройках WinSCP рекомендуется выбрать протокол SFTP. Программа WinSCP позволяет сохранить имя пользователя и пароль. При первом соединении с сервером программа выдает предупреждение о том, что ключ шифрования сервера ранее не использовался, и предлагает его сохранить или отвергнуть (продолжить сеанс или прервать). Естественно, надо выбрать продолжение сеанса. Программа WinSCP может использоваться как самостоятельное приложение и как плагин для других программ проводников, например для Far Commander.
Тексты программ и данные для задачи можно записать в отдельный каталог на сервере, тогда вся информация по этой задаче будет сохраняться в этом каталоге (объектные модули после трансляции текстов программ, файл с сообщениями об ошибках, выходные файлы).
На сервере существует понятиe домашнего каталога, это каталог с именем /home/имя_пользователя. При работе с командной строкой этот каталог становится текущим после установления терминального соединения. Программа WinSCP может запоминать последний посещенный в предыдущей сессии каталог. Поэтому важно следить, в какой каталог производится копирование.
После копирования необходимо перейти в рабочий каталог, выполнить компиляцию программы и ее запуск.
Полезно ознакомиться с информацией об установке и некоторых настройках программы WinSCP.
3. Графический интерфейс
Для работы с сервером удобно использовать графический интерфейс. В настоящее время предпочитаемой программой для подключения к рабочему столу кластера в графическом режиме является X2Go Client (замена программы NX Client, которая больше недоступна для скачивания с сайта производителя).
Для удалённого запуска графических Linux программ с использованием протокола X-Window предназначена и программа MobaXterm_vx.x.exe.
Установка и настройка программы PuTTY
Для установки программы PuTTY на свой компьютер воспользуйтесь ресурсами http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
Чтобы войти на нужный кластер, необходимо:
- Запустить программу PuTTY.
- В открытом окне ввести имя кластера(Host Name).
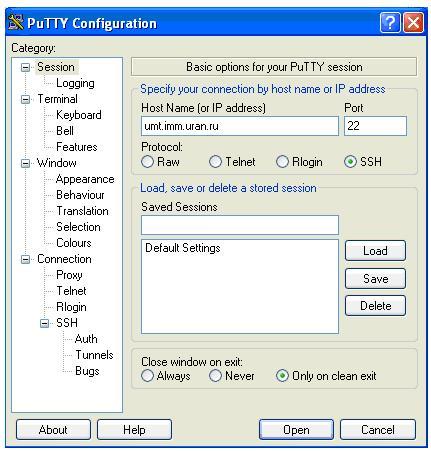
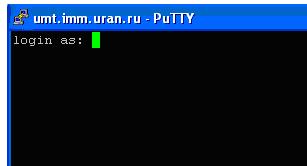
- Выполнить команду OPEN.
Откроется окно , в котором после ввода логина и пароля пользователь может работать на кластере из командной строки или используя Midnight Commander.
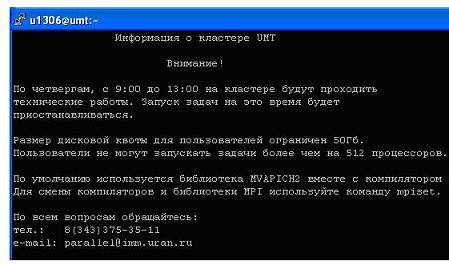
В начале сеанса выдается информация о кластере .
Для удобства работы можно выполнить некоторые настройки и сохранить их для дальнейших сеансов.
Например, чтобы при входе на кластер пользователь мог прочитать вводный текст на русском языке, необходимо выбрать кодировку UTF – 8 и сохранить данную настройку, проделав следующие шаги.
Открыть окно PuTTY
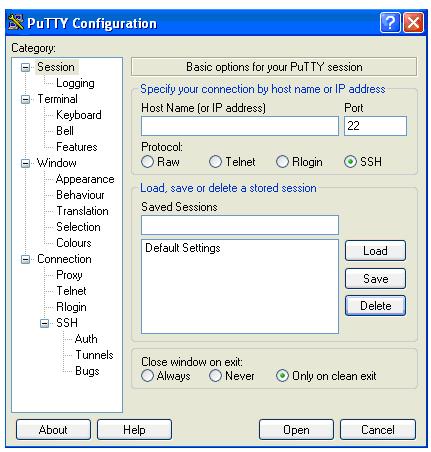
Выбрать раздел Translation.
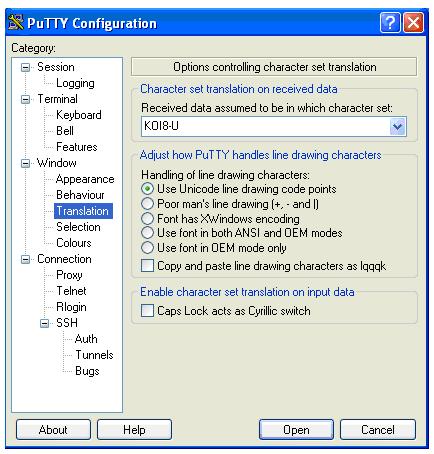
Выбрать кодировку UTF – 8.
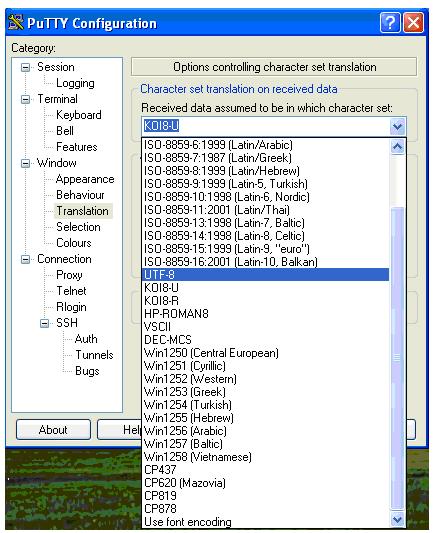
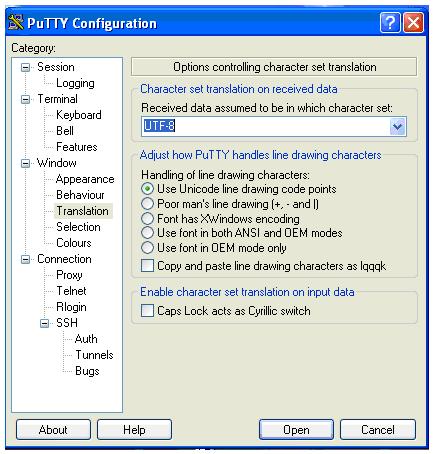
Перейти к разделу Session.
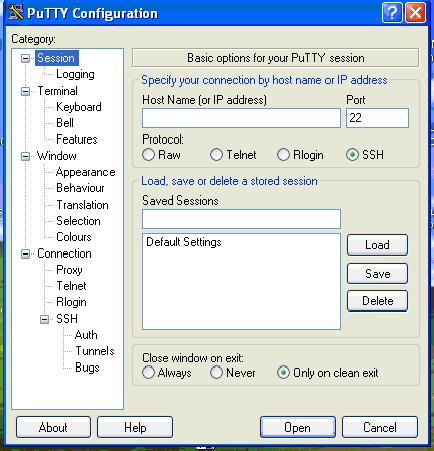
Ввести имя кластера в окнах Host Name и Saved Sessions.
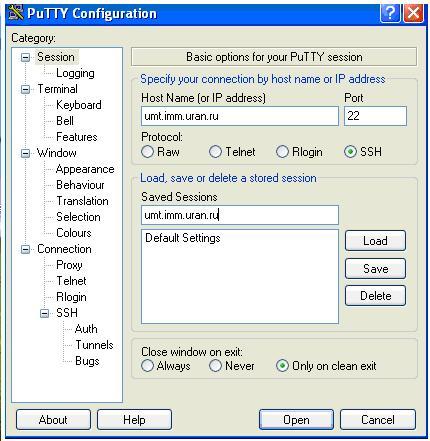
Нажать клавишу Save (сохранить)
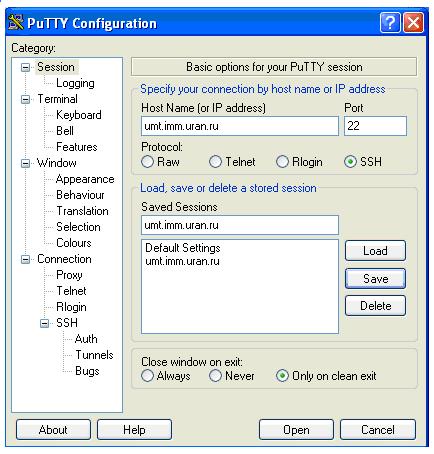
и затем Open .
В дальнейшем для начала сеанса на кластере достаточно выделить нужную сессию и нажать Load, затем Open или выполнить двойной клик на имени сессии.
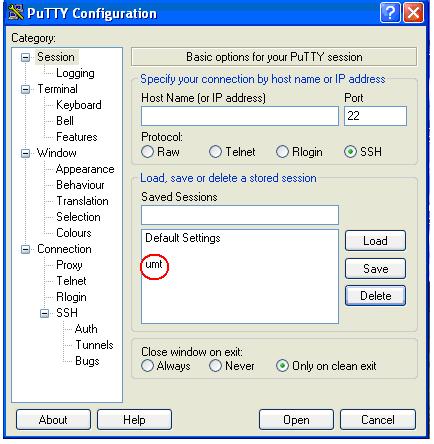
ВНИМАНИЕ!
Чтобы настроить нужную кодировку при работе на другом кластере, необходимо повторить все шаги заново для этого кластера.
В итоге при запуске PuTTY будет открываться окно
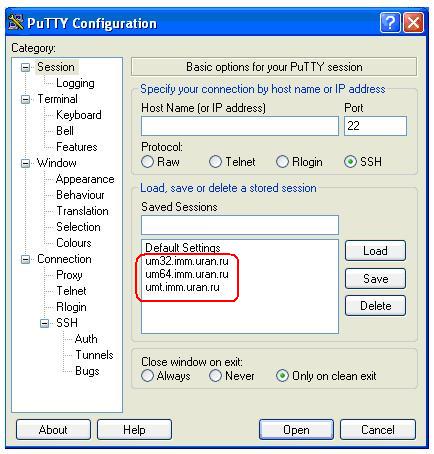
Пользователю достаточно выбрать нужный кластер и начать работу.
Желаем удачи!
Установка и некоторые настройки программы WinSCP
Программа WinSCP предназначена для удаленной работы с файлами на компьютерах/серверах.
Скачать программу можно с сайта разработчиков
Стиль графического интерфейса, выбранный в процессе установки, в дальнейшем можно изменить.
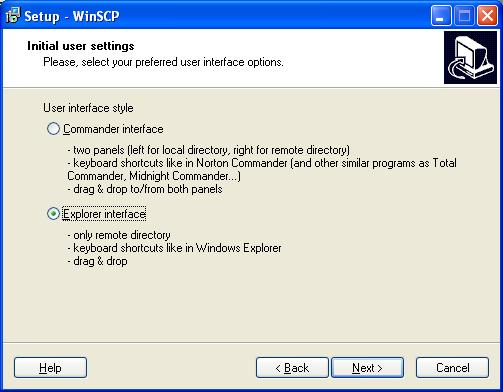
По окончании работы мастера установки на рабочем столе будет создан ярлык

и откроется окно,
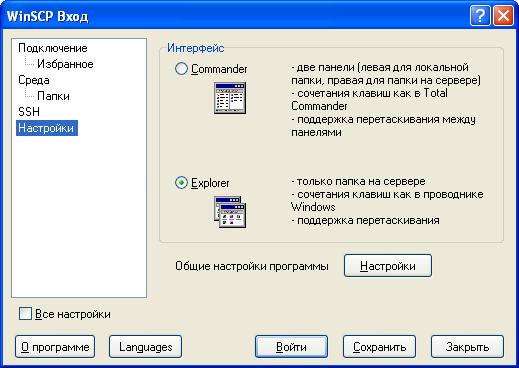
Можно заново выбрать привычный для работы интерфейс.
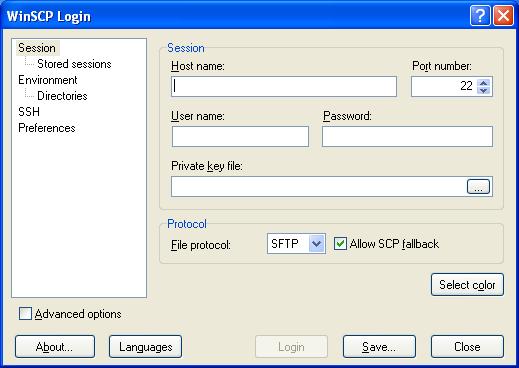
Ввести необходимую информацию для подключения к выбранному серверу. Пароль лучше не вводить и не сохранять.
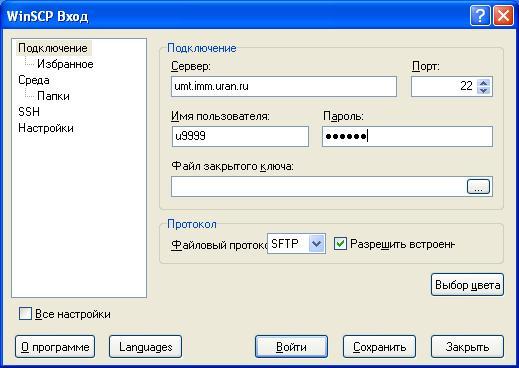
Сохранить эти настройки.
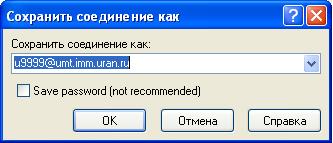
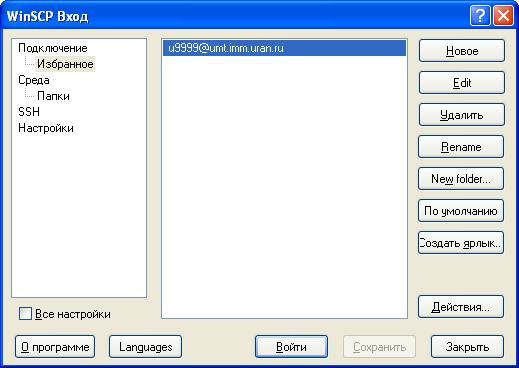
Аналогично можно выполнить и сохранить настройки для входа на другие серверы/кластеры.
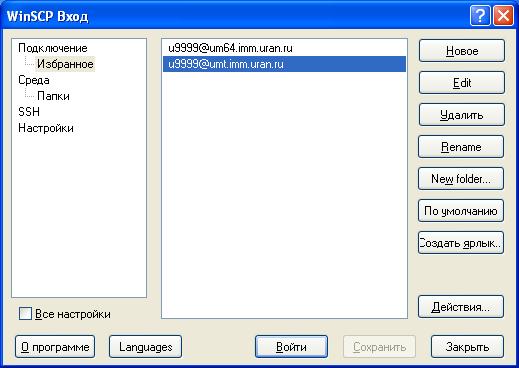
Теперь остается выбрать сессию и выполнить ВОЙТИ.
Во время первого сеанса выдается диагностика,
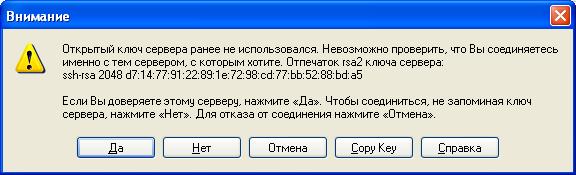
выбрать ДА и продолжить работу.
Если пароль не был сохранен, то надо будет его ввести в новом окне.
Далее можно работать с файлами исходного компьютера и сервера, используя настроенный интерфейс.
Однопанельный в стиле "Проводника":
Либо двухпанельный в стиле "Командера":
При закрытии окна рабочего инерфейса можно закончить сеанс работы.
Желаем удачи!
Mosh (Mobile Shell)
Одним из средств удаленного доступа к кластеру "Уран" является Mosh (Mobile Shel - мобильная оболочка). Mosh является альтернативой для интерактивного терминала SSH. Реализации Mosh - доступны для Windows, Linux, Android и iOS. Особенностью Mosh - является то, что она позволяет получить доступ к серверу с мобильного телефона при плохом качестве связи. Mosh поддерживает кратковременные перерывы связи и позволяет вводить команды в командной строке даже тогда, когда связь временно отсутствует. После восстановления связи, команды передаются на сервер, а экран обновляется, чтобы показать последние сообщения.
В Linux клиентская часть Mosh устанавливается стандартными средствами установки программ. Для Android необходимо установить эмулятор командной строки - termux, и выполнить в нем команду apt install mosh. В Windows и ChromeOS Mosh устанавливается как расширение браузера Chtome.
ВНИМАНИЕ. Закрытие окна приложения Mosh в любой ОС, не завершает сеанс на сервере, но делает его недоступным. Для корректного завершения работу используйте команду exit. Удаление незавершенных сеансов на сервере описано ниже.
Описание установки Mosh из браузера Google Chrome по шагам:
Шаг № 1.
Вызываем Google Chrome и входим в настройки через кнопку «Настройки и управление Google Chrome»
Шаг № 2
В открывшемся окне выбираем «Дополнительные инструменты/Расширения» или «Настройки/Расширения» (в зависимости от версии Chrome);
Шаг № 3.
Вызвав «Расширения» и не обнаружив MOSH, идем в «Интернет магазин Chrom»
Шаг № 4.
Mosh появился в «Расширения».
Вы можете работать прямо в браузере, если дважды щелкните на иконке с изображением Mosh ![]() , или установить приложение в "Главное меню" компьютера и запускать Mosh из меню кнопки "Пуск".
, или установить приложение в "Главное меню" компьютера и запускать Mosh из меню кнопки "Пуск".
Шаг № 5.
Произошел вызов Mosh.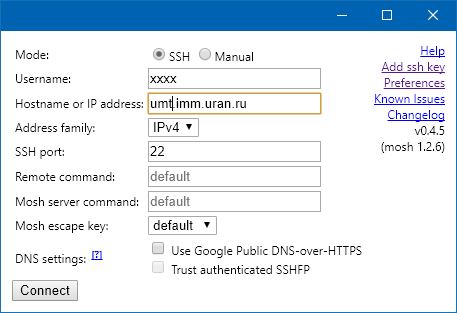
Заполните текстовые поля для Username (ваш логин) и Hostname (имя хоста umt.imm.uran.ru), затем нажмите Connect.
Шаг № 6
После ввода пароля и появления приглашения командной строки можно начинать работать!
Несколько полезны советов.
Как добавить закрытый ключ.
Закрытый ключ добавляется при запуске Mosh по ссылке «Add ssh key». После задания ключа работа с Mosh будет происходить без запроса пароля. В диалоговое окно вставляется текст секретного ключа, который можно взять из файла ~/.ssh/id_rsa на сервере. Кнопка Save сохраняет ключ в постоянном хранилище браузера.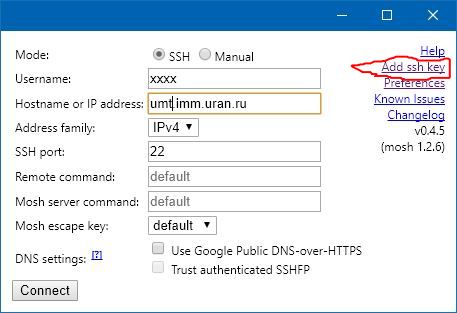
Если повторно выбрать «Add ssh key», то поле для ключа будет содержать напоминание о том, что ключ уже был задан. Если ключ ещё нужен, то можно закрыть окно крестиком. Если нажать кнопку Save не вводя новый ключ, то текущий ключ удалится из памяти.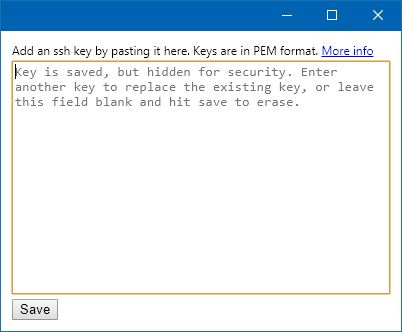
Как задать отображение русских букв в сеансе работы с Mosh.
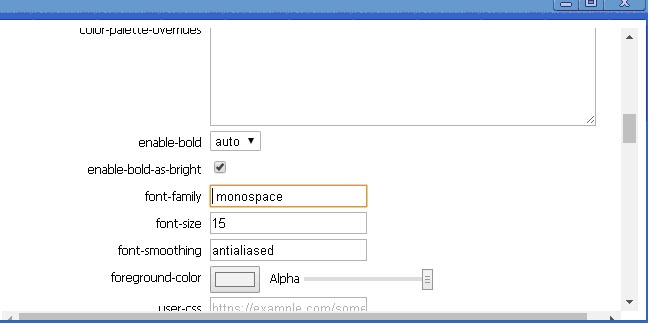
Чтобы правильно отображать русские буквы необходимо в Preferences, в текстовом поле для «font-family» выбрать шрифт «monospase» (из списка удалить все кроме «monospase.
Как выбросить все сеансы работы c Mosh.
В командной строке выполните команду:
killall -KILL mosh-serverОсторожно. Если вы работаете через Mosh, то закроется и текущий сеанс.
Использование MobаXterm
Программа MobaXterm_vx.x.exe объединяет в себе текстовый терминал и средства для удалённого запуска графических Linux программ с использованием протокола X-Window.
Программа распространяется в виде переносимой (portable) версии в архиве с именем MobaXterm_Portable_vx.x.zip ( x.x - это номер версии), или в виде архива с инсталлятором MobaXterm_Installer_vx.x.zip, которые можно бесплатно получить на сайте разработчика.
Запустите MobaXterm_vx.x.exe :
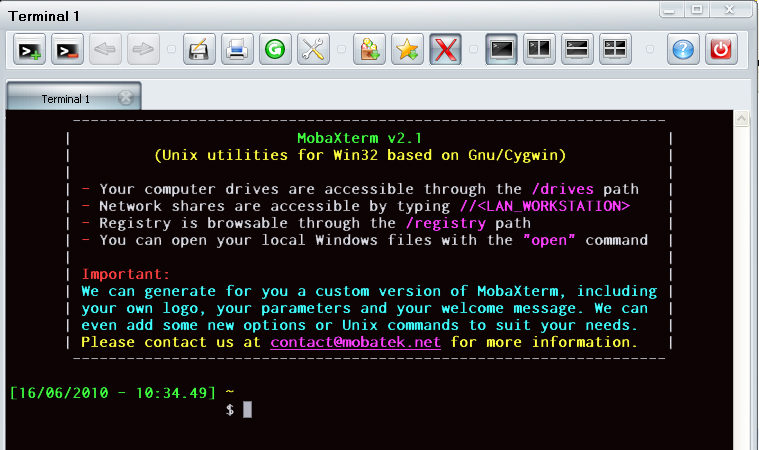
Рисунки №1 и №2 демонстрируют вызов программы MobaXterm_vx.x.exe, которая открывает терминал.
В командной строке наберите ssh umt.imm.uran.ru и введите имя пользователя и пароль. Теперь можно запускать графические приложения, например matlab. При запуске в конец строки можно добавить символ &, что позволит освободить командную строку для ввода последующих команд:
matlab &
Переключение русской раскладки в графических приложениях
На графические приложения XWindow переключение раскладки в текстовой консоли никак не влияет. Чтобы в графических приложениях можно было переключать раскладку надо до их запуска в консоли на удалённой машине выполнить команду, которая назначит переключение на сочетание Левый Alt+ Shift.
setxkbmap -layout us,ru -variant winkeys -option grp:alt_shift_toggle
Для удобства можно вставить эту команду на автовыполнение, например, добавив команду в файл ~/.bash_profile В версии MobaXterm Pro в расширенных настройках ssh-соединений команду можно прописать в поле Advanced SSH Settings -> Execute conmmand.
Программное обеспечение кластеров
Программное обеспечение кластера (трансляторы, библиотеки, пакеты прикладных программ и т. д.) обновляется и пополняется при выходе новых версий и по запросам пользователей (на адрес parallel@imm.uran.ru). Для компиляции программ доступны Intel компиляторы (бесплатно для некоммерческого использования в версиях Linux), свободно распространяемые компиляторы серии GCC (GNU Compiler Collection) и компиляторы Portland Group (PGI) с языков C , C++ , Fortran:
Intel (icc, icpc, ifort) GNU (gcc, g++, gfortran, g77) PGI (pgcc, pgcpp, pgf77, pgf90, pgf95)
Для трансляции Паскаль-программ можно воспользоваться Free Pascal Compiler (fpc).
Для организации межпроцессного взаимодействия можно использовать следующие библиотеки обмена сообщениями, реализующие стандарт MPI:
MVAPICH2 OpenMPI MPICH2
MPI (Message Passing Interface) ориентирован, прежде всего, на системы с распределенной памятью. Возможно распараллеливание программ и с помощью стандарта OpenMP (Open Multi-Processing), ориентированного на системы с общей памятью (см. Компиляция и запуск задач с OpenMP), а также стандартов CUDA (см. Использование CUDA) и OpenACC (Open Accelerators), нацеленных на использование графических процессоров (GPU). В компиляторах Portland Group реализованы как OpenMP, так и OpenACC (см. PGI Accelerator и OpenACC).
На кластере установлено программное обеспечение (ПО) фирмы Intel для профилировки и отладки – Intel Parallel Studio XE. Это ПО позволяет находить наиболее нагруженные места в приложении, подсчитывать степень параллельности программы, находить тупики и гонки в параллельных программах и т.д. Основные инструменты Advisor XE, Inspector XE и Vtune Amplifier XE находятся в соответствующих папках в каталоге /opt/intel (см. Инструменты Intel для профилировки и отладки).
Для смены компиляторов и библиотеки MPI, а также выбора других пакетов прикладных программ используйте модули установки переменных окружения .
Доступные пакеты
Имеются академические лицензии на пакеты Matlab и ANSYS CFX Academic Research.
Информация о запуске программ из этих пакетов находится на страницах:
- Запуск параллельного Matlab - краткая инструкция
- Параллельный Matlab - полная инструкция
- Запуск программ из пакета ANSYS
Установлены по запросам и используются пакеты OpenFOAM, GAMESS, SIESTA, VASP и др.
Компиляция программ на кластере
Выбор среды компиляции
По умолчанию на каждом кластере установлен определенный набор компиляторов и библиотек. При входе на вычислитель каждому пользователю на экран выдается информация о некоторых установках по умолчанию, а также дополнительная служебная информация. Для выбора другого доступного ПО (компилятора, библиотеки обмена сообщениями, пакета прикладных программ) необходимо использовать модули установки переменных окружения. Для быстрого доступа к настройкам основных модулей можно воспользоваться командой mpiset (эта команда без параметров выдает текущие установки). В дальнейшем, при запуске задачи на счет, необходимо следить, чтобы выставленная конфигурация (например, через mpiset) совпадала при компиляции и при запуске.
О компиляции
Компиляция (в расчете на использование MPI) выполняется утилитами (командами):
mpiccдля программ на Сиmpicxxдля программ на C++mpif77для программ на Фортране 77mpif90для программ на Фортране 90
Они запускают компилятор, передавая ему дополнительные флаги, специфичные для MPI (ключ -show у этих утилит покажет, какая команда будет выполнена). Заметим, что компиляция программы (например исходной) без MPI может быть выполнена и обычными средствами со ссылкой на используемый компилятор (icc, gcc, pgcc, ...).
Для файлов на Си и C++ важно расширение имени файла: для языка Си это .c, для языка С++ это .cxx.
В командной строке задается список файлов, которые надо откомпилировать, и имя выходного файла. Для удобства желательно сообщения об ошибках компиляции перенаправить в файл. Например, если наш исполняемый файл должен называться outprog и собирается из файлов in1.c и in2.c, находящихся в каталоге proj, то необходимо выполнить следующие действия:
cd proj
mpicc –o outprog in1.c in2.c 2>errors.log
Сообщения об ошибках компиляции попадут в файл errors.log. В командной строке файл можно пролистать командой:
less errors.log
При пролистывании используются клавиши <Пробел> - следующая страница, b - предыдущая страница, q - выход из просмотра.
Подключение дополнительных библиотек обеспечивается добавлением опции –l<имя_библиотеки> в строку компиляции. Например, библиотека BLAS подключается так:
mpicc -o mytest mytest.c -L /usr/lib64/atlas -lcblas Если программа скомпилирована успешно, создастся файл mytest. Это можно посмотреть в WinSCP, не забыв обновить список файлов в окне, или в командной строке командой ls, которая выдает список файлов.
Компиляция программ, использующих для распараллеливания стандарты OpenMP, CUDA и OpenACC, а также особенности запуска таких программ рассмотрены в отдельных инструкциях, а именно:
Базовые команды ОС UNIX
Полная информация по UNIX командам и их параметрам выдается с помощью справочной командыman <имя команды> (q или Q - выход из man).
Далее под именем файла понимается простое, полное или относительное имя файла.
Простое имя файла - это имя файла в текущем (рабочем) каталоге (директории), например, mytest.
Полное (абсолютное) имя файла включает путь от корневого каталога, обозначаемого символом слеш (/), до каталога, содержащего файл, например, /home/u9999/dir/mytest
(слеш используется и как разделитель подкаталогов). Заметим, что /home/u9999 называется домашним каталогом пользователя u9999, домашний каталог обозначается тильдой (~).
Относительное имя файла содержит путь, который отсчитывается от текущего каталога и, следовательно, не начинается со слеша, например, dir1/mytest1.
Аналогичные пояснения относятся и к именам каталогов.
Следует иметь в виду, что большие и малые буквы в UNIX различаются.
При наборе команд и путей к файлу можно нажимать клавишу Tab для автодополнения имен; с помощью стрелок вверх и вниз можно выбрать ранее выполнявшуюся команду.
Ниже перечислены основные команды, с которыми полезно ознакомиться для работы в ОС UNIX:
pwd— выдать полный путь текущего каталога;mkdir <имя каталога>— создать каталог;cd <имя каталога> — сменить текущий каталог;cd .. — перейти в каталог уровнем выше ;cd— перейти в домашний каталог ;ls— распечатать содержимое текущего каталога;ls <имя каталога>— распечатать содержимое заданного каталога;rm -R <имя каталога>— удалить каталог со ВСЕМИ (опция-Rили-r) подкаталогами и файлами в нем;rm <имя файла>— удалить файл. Удалённый файл или каталог восстановить невозможно;cp <имя копируемого файла> <имя каталога, в который копируем>— копировать файл, напримерcp /home/u9999/mytest /home/u9999/dirmv <имя исходного файла> <имя каталога, в который перемещаем|имя файла, в который переименовываем>— переместить (переименовать) файл;cat <имя файла>— выдать содержимое файла на консоль;more, less— команды просмотра текста;gzip <имя файла>— сжать файл;gunzip <имя файла>.gz— расжать файл;tar <опции> <имя архива>.tar <имена файлов и каталогов>— работа с архиватором tar;size <имя файла с исполняемой программой>— выдать размер исполняемой программы в байтах, например$ size mytest text data bss dec hex filename 423017 12016 2128658400 2129093433 7ee76339 mytestгде
text- размер выполняемого кода,data- размер области инициализированных данных,bss- размер области неинициализированных данных,dec- общий размер программы,hex- общий размер программы в шестнадцатеричной системе,filename- имя программы. Если имя не указано, то будет использоваться a.out ;quotacheck(добавленная команда) позволяет узнать назначенный пользователю лимит дискового пространства и текущий объем его данных на диске, например$ quotacheck User: u9999 Used: 25.18GB Limit: 100.00GBdu <опции> <имя файла или каталога>— оценка места на диске, занимаемого файлом или каталогом, напримерdu -h mytestопция
-hиспользуется для более удобной формы выдачи (например, 1K 234M 2G), иначе по умолчанию в K, т.е. в Kбайтах (1 Кбайт=1024 байт); опция--siкак-h, но использует степень 1000, а не 1024.du -sh /home/u9999опция
-sиспользуется для выдачи суммарного места на диске, занимаемого пользователем u9999.
При отсутствии аргумента-имени выдается информация для текущего каталога:
du -sh— размер текущего каталога;
du -h— размер каталога и подкаталогов.find <имя каталога> -mtime <количество суток>— выдать имена всех файлов из <имя каталога> и его подкаталогов, которые изменялись в последние 24*(1+<количество суток>) часов;passwd— сменить пароль;uptime— получить время непрерывной работы сервера;exit— выйти из оболочки (или отключиться от машины).
Работа с архиватором tar
tar <опции> -f <имя архива.tar> <имена файлов и каталогов>Опции:
-f— указать имя файла архива. По умолчанию архив читается со стандартного ввода.-f -— явное задание чтения архива со стандартного ввода.-c— создать архив и записать в него файлы;-x— извлечь файлы из архива;-t— просмотреть содержимое архива; формат вывода аналогичен командеls –l; если имена файлов не указаны, то выводятся сведения обо всех файлах архива;-z— использовать программуgzipдля сжатия при архивировании файлов и для обратной распаковки архива перед извлечением из него файлов. Файлу сжатого архива принято давать с расширением.tar.gzили сокращённо.tgz;-j— аналогично-zтолько для программыbzip2и архивов с расширением.tar.bz2или.tbz; В современных версияхtarопции вызова программы сжатия-z,-jи т.п. указывать не обязательно — формат архива распознаётся автоматически.-p— при извлечении сохранить права доступа к файлам (по умолчанию сбрасываются права указанные в маскеumask);-v— выводить имена всех файлов, которые обрабатываются; если выбрана и опцияt, тоvдает больше информации о сохраненном файле, а не просто его имя.
При использовании нескольких опций знак «-» перед опциями не ставится.
Примеры
tar cf myarch.tar file1 file2 … filen — создание архива myarch.tar и запись в него перечисленных файлов;
tar cf myarch.tar mydir — создание архива из содержимого каталога mydir и всех его подкаталогов в файле myarch.tar;
tar xvpf myarch.tar— извлечение файлов из архива; при извлечении формируются и все подкаталоги; (f — ссылается на архивный файл, данная опция ставится последней в списке опций; p — заархивированные файлы будут восстановлены с изначальными правами доступа; v — выводятся имена извлекаемых файлов);
tar tf myarch.tar — выдача списка всех файлов, хранящихся в архиве myarch.tar;
tar cfz myarch.tgz mydir — архивация файлов с последующим сжатием архива программой gzip;
tar xfz myarch.tgz — вызов gzip для распаковки архива перед извлечением файлов;
zcat myarch.tgz | tar xf - — вызов внешней программы распаковки и передача распакованного архива через перенаправление стандартного ввода.
Архив
Установка и настройка NX клиента для Windows
- Дистрибутив NX клиента для Windows (nxclient-x.x.x-x.exe, где x.x.x-x - это номер версии) можно бесплатно получить на сайте разработчика www.nomachine.com в разделе
DOWNLOAD->Legacy NX 3.5.0 products (NX Client for Windows в списке NX Client products).
ВНИМАНИЕ! Версия 3 была полностью заменена версией 4, коммерческой.
Вместо программы NX Client можно использовать программу X2Go Client, а также MobaXterm_vx.x.exe.
Чтобы начать процедуру установки запустите скаченный файл и проделайте весь путь инсталляции до добавления NX Client for Windows в меню:
-
Запустите NX Connection Wizard (мастера настройки NX) для установки вашей сессии
Диалоговое окно настройки сессии:
 Далее:
Далее: 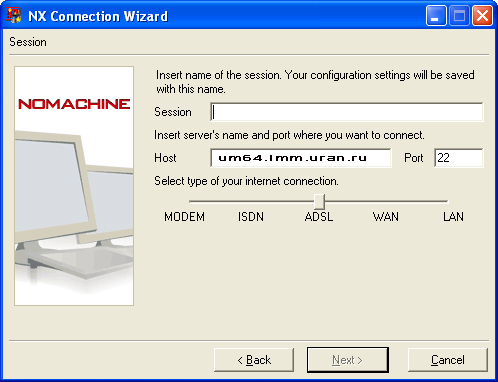
- • Host - имя сервера, к которому планируется подключение. Для кластера "Уран" это имя umt.imm.uran.ru .
- • Port- номер порта, на котором сервер ждет подключений - 22.
- • Ползунок с подписями "Modem", "ISDN", "ADSL", "WAN" и "LAN" - меняет степень сжатия данных в канале между сервером и клиентом и позволяет снизить объем трафика в канале связи "клиент <-> сервер". Выбор левой отметки означает меньшую нагрузку на сеть и большую на процессор, а правой отметки - большую нагрузку на сеть и меньшую на процессор.
Итак, задав имя сервера, порт, имя сессии вам необходимо задать параметры рабочего стола:
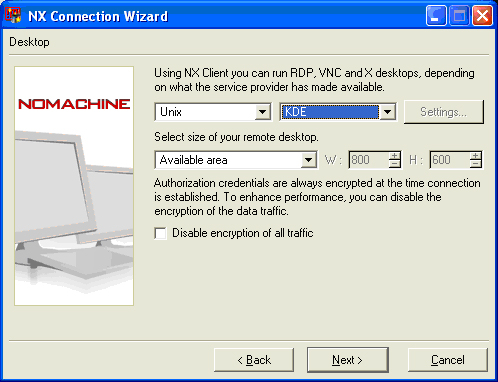 • Desktop - выбор параметров рабочего стола. В одном выпадающем списке выбирается ОС, запущенная на сервере, к которому планируется подключение. Во втором выпадающем списке выбирается графическая оболочка (Gnome, KDE, пр.), вход в которую будет осуществлен автоматически. Рекомендуем задавать KDE.
• Desktop - выбор параметров рабочего стола. В одном выпадающем списке выбирается ОС, запущенная на сервере, к которому планируется подключение. Во втором выпадающем списке выбирается графическая оболочка (Gnome, KDE, пр.), вход в которую будет осуществлен автоматически. Рекомендуем задавать KDE.
• Display - установка размеров экрана. Можно выбрать конкретные значения (например, "640х480" или "800х600" и т.д.), можно выбрать полноэкранный (Fullscreen) или пользовательский (Custom) размеры...
Следующее диалоговое окно будет завершающим настройку соединения. - В дальнейшем вызвав NX Client for Windows и задав сессию
вы можете увидеть примерно следующее:
Примечание:
Сессия считается завершенной только после выключения компьютера. Закрыв окно сессии, вы можете вернутся к истории ваших команд, если повторно закажите сессию.
Настройка русской клавиатуры в NX клиенте
Для настройки русской клавиатуры в NX клиенте используются стандартные механизмы Linux. В графической среде, установленной на кластере "Уран", настройка выполняется следующим образом:
Нажимаем на кнопку "Пуск" в левом нижнем углу Linux'овского рабочего стола. 
Выбираем меню "System settings"->"Regional & language" 
Выбираем подпункт "Keyboard layout" и на вкладке "Layouts" ставим галочку в "Enable keyboard layouts" 
Добавляем русский язык в "Active layouts" 
На вкладке "Switching options" и "Advanced" выбираем сочетание клавиш для переключения раскладок и объекты на которые распространяется действие переключения. На скриншотах переключение настроено по сочетанию клавиш "Alt+Пробел" одновременно для всех запущенных программ. 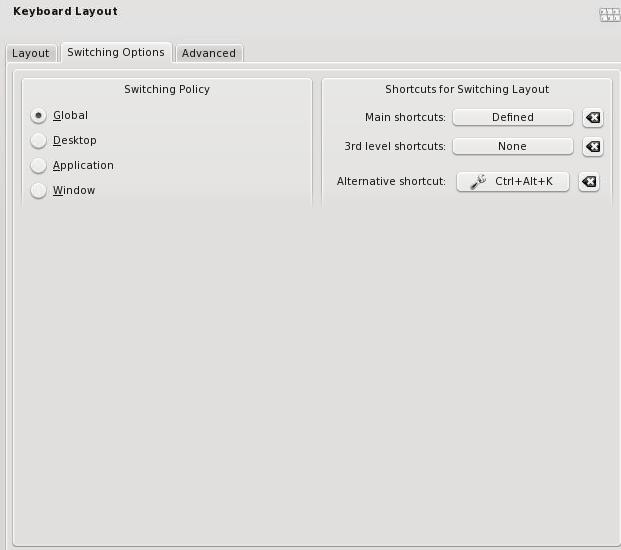
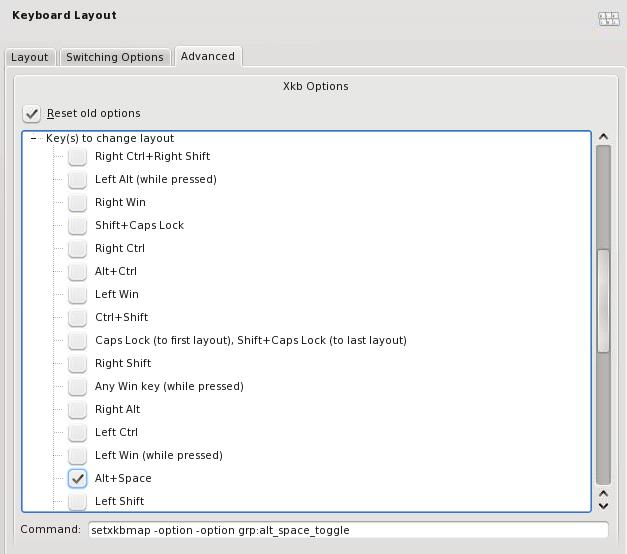
Запуск задач на кластере
ВНИМАНИЕ: c 16.03.2022 запуск задач должен осуществляться в подкаталогах ~/_scratch и ~/_scratch2. Запись данных в другие подкаталоги домашнего каталога на вычислительных узлах будет заблокирована.
Каталоги ~/_scratch и ~/_scratch2расположены в отдельных системах хранения: _scratch — на параллельной файловой системе Lustre, _scratch2 — на SSD-дисках. Эти файловые системы также могут быть видны под именами /misc/home1/uXXXX — _scratch и /misc/home6/uXXXX — _scratch2, где uXXXX — логин пользователя.
При запуске задачи пользователя на счет
- необходимо учитывать ограничения по ресурсам для пользователей;
- желательно использовать тот модуль установки переменных окружения, с которым программа была откомпилирована;
- пока задача не просчиталась, нельзя ее перекомпилировать, удалять исполняемый файл и менять входные данные.
Запуск программ осуществляется в системе SLURM. Основные команды SLURM приведены в инструкциях ниже. Полная информация выдаётся с помощью команды man.
В результате запуска задача помещается в очередь заданий и ей присваивается уникальный идентификатор (JOBID). Его можно узнать командами mqinfo, mps или squeue, sacct.
На основе команд SLURM (которые начинаются с буквы s) для удобства пользователей (в частности, обеспечения преемственности при переходе на SLURM) были реализованы упрощённые команды запуска MPI-, MATLAB-, ANSYS-программ и информационные команды (начинающиеся с буквы m).
Упрощённые команды
mqrun, замена mpirun, — запуск программы на кластере, аналог команды sbatch.
mqinfo — выдача информации об узлах и очереди заданий с помощью команд sinfo и squeue ( Пример выдачи sinfo из команд mqinfo и mps).mps или mqinfo -u $USER -l — выдача информации об узлах и задачах только самого пользователя.mqdel, mkill — отмена выполнения задачи (ожидающей старта или уже стартовавшей), действуют как команда scancel.
Команда mqrun (замена mpirun, аналог sbatch ) запускает в пакетном режиме успешно откомпилированную С- или Fortran-программу, например
mqrun -np 8 -maxtime 20 -stdin in.txt mytestгде для mytest затребовано формирование 8 процессов (опция -np или -n) с выделением каждому по умолчанию 1950 MB (т.е. --mem 1950) и установкой входного файла (-stdin) при ограничении времени счета 20-ю минутами (–maxtime или –t). Так как не указаны опции -stdout и -stderr, то стандартными выходными файлами будут автоматически созданные mytest.1/output, mytest.1/error.
В ответ в строке вида Submitted batch job 1475 выдаётся уникальный идентификатор (JOBID) задачи в очереди заданий, здесь 1475. Уникальный идентификатор используется в командах отмены выполнения задания, например
mqdel 1475 #или mkill 1475Внимание!
1. В каталогах вида имя_программы.номер номера возрастают, начиная с 1. Пользователь должен сам удалять ненужные каталоги.
2. Для выдачи опций mqrun следует набрать
mqrun -help3. При необходимости можно указать опции команды sbatch в качестве значения параметра --slurm-opts команды mqrun, например:
mqrun -n 6 -nh 2 --slurm-opts '--ntasks-per-node=3 --gres=gpu:3 -x tesla[49,52]' ./testКоманды запуска SLURM
Система SLURM позволяет с помощью команд sbatch и srun работать соответственно в пакетном и интерактивном режимах. Пакетный режим является основным в работе с кластером.
Команда sbatch для запуска программы в пакетном режиме имеет вид
sbatch [опции] --wrap="srun <имя программы> [параметры программы]"
или
sbatch [опции] <имя скрипта> [параметры скрипта]
Минимальный скрипт может выглядеть так
#!/bin/bash
srun myprogram param1 param2
Внимание!
Библиотека OpenMPI работает только с командой sbatch и при этом перед именем программы в опции --wrap или в скрипте вместо srun добавляется orterun:
sbatch [опции] --wrap="orterun <имя программы> [параметры программы]"
Команда srun для запуска интерактивной программы имеет вид
srun [опции] <имя программы> [параметры программы]
Опции
-n <число процессов>если число процессов (tasks) не задано, то по умолчанию n=1.-t <время>при отсутствии заказа времени для решения задачи выделяется по умолчанию 30 минут. Максимальное время для счета задачи:- 20 часов - в будние дни (с 9 часов понедельника до 16 часов пятницы);
- 85 часов - на выходные (с 16 часов пятницы до 9 часов понедельника плюс 20 часов), т.е. на 85 часов задача запустится, если она войдет в решение в 16 часов ближайшей пятницы, иначе будет ждать следующей; аналогично, на 84 часа есть шанс запустить до 17 часов пятницы и т.д. до 9 часов понедельника;
- 100 часов - если к выходным добавляются праздничные дни.
Время может быть задано в виде:
- минуты
- минуты:секунды
- часы:минуты:секунды
- дни-часы
- дни-часы:минуты
- дни-часы:минуты:секунды
-N <кол-во узлов>задает число узлов (nodes) для задачи, если пользователю это важно.Для увеличения оперативной памяти можно воспользоваться опциями:
--mem-per-cpu=<MB>задаёт минимальную память в расчёте на одно ядро в мегабайтах ; если не задано, то по умолчанию 1 ГБ;--mem=<MB>задаёт память на узле в мегабайтах.
Эти опции взаимно исключают друг друга.--gres=gpu:<тип GPU>:<кол-во GPU>задаёт запуск программы на узлах с GPU. Еслиgresне задан, то количество GPU=0, т.е. GPU при счете не используются. Если не указан тип GPU, то автоматически назначается младшая модель (m2090). Типы GPU в 2024 году m2090, k40m, v100, a100.-p <раздел>или--partition=<раздел>позволяет указать раздел (partition) кластера для запуска задачи.
Основные разделы: tesla, apollo, hiperf и debug. Эти разделы покрывают весь кластер и взаимно не пересекаются, т.е. содержат разные узлы (см. Кластер «Уран»). Раздел v100 в 2024 году состоит из одного узла tesla-a101. Список всех разделов выдается командойsinfo -s. Если раздел не задан пользователем явно, то по умолчанию будет выбран раздел apollo, но при отсутствии в нем нужного числа свободных процессоров будет задействован раздел tesla.
-p debugпозволяет запускать задачи в специально выделенном для отладки программ разделе debug с максимальным временем счета 30 минут. Например,srun -p debug mytest
Опции -w, -x, -С позволяют более гибко регулировать список узлов, допустимых для запуска задачи (см. man sbatch).
Например:
-w tesla[5-7,15]- выделить заданию ресурсы узлов tesla5, tesla6, tesla7, tesla15, а если на них не хватит, то и другие узлы;-x tesla22- не выделять заданию ресурсы узла tesla22;-С a2017- выделять задаче только те узлы, которые имеют ресурс с именем (Feature), указанным после-C. На кластере имеются ресурсы с именами: tesla, a2017, a2019 (поколения узлов); bigmem (узлы с большим объёмом ОЗУ), a100, v100 (модель GPU). Информацию о том, какие ресурсы есть на конкретном узле, можно получить командой видаscontrol show node tesla22.
Описание всех опций и примеры команд можно посмотреть в руководстве man с помощью команд:
man sbatch
man srun
По умолчанию стандартный вывод пакетной задачи и стандартный поток ошибок направляются в файл с именем slurm-%j.out, где %j заменяется уникальным идентификатором (номером) задачи. Перенаправление ввода-вывода можно выполнить, указав программе sbatch опции
--input=<filename pattern>--output=<filename pattern>--error=<filename pattern>
При задании имени файла (filename pattern) можно использовать символы замены, в частности, %j заменяется на JobID, %t - на номер процесса в рамках задания. Таким образом file_%j_%t.txt при каждом запуске задачи сгенерирует уникальные имена для каждого процесса.
Выдаваемые результаты конкретной команды srun можно поместить вместо стандартного в указанный файл, добавив после команды символ перенаправления вывода >.
srun mytest > out_mytest &
Можно (чаще, при интерактивном запуске) параллельно просматривать результаты и сохранять их в файле, например:
srun --mem 40000 mytest | tee out_mytest
Примеры запуска
В результате интерактивного запуска программы hostname выдаётся имя узла, на котором запущен соответствующий процесс, например:
u9999@umt:~$> srun hostname
apollo5
При запуске в пакетном режиме команда запуска программы задаётся либо в скрипте, либо через опцию --wrap, например,
sbatch -n 2 --wrap="srun hostname"
или
sbatch mybat
где скрипт mybat:
#!/bin/sh
#SBATCH -n 2
srun hostname &;
wait
Внимание!
- Команда
srunвнутри скрипта может запрашивать ресурсы только в тех пределах, которые установлены командойsbatch. - Скрипт запускается только на первом из выделенных узлов.
- Запуск нескольких процессов осуществляется командой
srun. При этом все опции, указанные в командной строке или самом скрипте в строках#SBATCH, приписываются к каждой командеsrunданного скрипта, если не переопределены в ней. Так, результирующий файл приведённого примера будет содержать 2 строки с именами узлов (возможно, одинаковых), на которых выполнятся 2 процесса задачи, сформированные командой srun. - Если команды srun запускаются в фоновом режиме (символ
&в конце строки), то они при наличии ресурсов могут выполняться одновременно.
Примеры постановки задач в очередь
u9999@umt:~$ sbatch -n 3 --wrap="srun mytest1 3 5.1"
Submitted batch job 776
сформирована пакетная задача с запуском 3-х процессов mytest1 c 2-мя параметрами. Задаче присвоен уникальный идентификатор 776.
u9999@umt:~$ srun -N 2 sleep 30 &
[1] 22313
сформирована интерактивная задача в фоновом режиме. [1] - номер фоновой задачи в текущем сеансе, 22313 - pid процесса srun на управляющей машине. Уникальный идентификатор можно узнать с помощью команд squeue, sacct.
Пример задачи, рестартующей после истечения заказанного времени
Все опции запуска описаны в batch-файле. За 60 секунд до окончания заказанного времени все процессы, запущенные через srun получат сигнал TERM и завершатся, после чего последняя команда в скрипте restart_sbatch снова поставит его в очередь. Перезапуск произойдёт и в том случае, когда программа, запущенная через srun завершится самостоятельно.
Опция --signal задаёт номер сигнала, который будет отправлен процессам (KILL) и время отправки сигнала (60 секунд до конца заказанного времени счёта).
Запуск
sbatch restart_sbatch
Содержимое restart_sbatch:
#!/bin/sh
#SBATCH -n 1 -t 180
#SBATCH --signal=KILL@60
srun myprog arg1 arg2
# здесь можно вставить анализ результатов,
# формирование новых параметров,
# проверку условий завершения
# и т.п.
sbatch ./restart_sbatch
Запуск массива задач
Массив задач, это средство быстрого формирования очень большого задач, без повышения нагрузки на очередь задач и планировщик.
При формировании массива указывается список индексов, либо стартовый индекс, максимальное значение индекса и его шаг. Запускаемая задача может проверить в переменных окружения параметры массива и назначенное текущему экземпляру значение индекса.
# Перебираем индексы от 0 до 31 включительно
$ sbatch --array=0-31 -N1 myjob
# Перебираем индексы 1, 3, 5, 7
$ sbatch --array=1,3,5,7 -N1 myjob
# Перебираем индексы от 0 до 7 включительно с шагом 2
$ sbatch --array=1-7:2 -N1 myjob
# Дополнительно после символа % можно указать максимальное количество экземпляров, считающихся одновременно
sbatch --array=0-31%5 -N1 myjob
Например, задача, запущенная командой sbatch --array=1-3 -N1 myjob, увидит следующий набор переменных окружения:
SLURM_ARRAY_TASK_ID=3
SLURM_ARRAY_TASK_COUNT=3
SLURM_ARRAY_TASK_MAX=3
SLURM_ARRAY_TASK_MIN=1
Далее можно сформировать параметры используя значения переменной SLURM_ARRAY_TASK_ID. Например, программа myjob может прочитать нужную строку из файла параметров и передать её дальше в качестве аргументов для вычислений:
#!/bin/bash
PARAMS=$(head -n $SLURM_ARRAY_TASK_ID params.txt | tail -n1)
./exefile $PARAMS
Запуск интерактивных задач
Иногда бывает необходимо запустить на кластере интерактивную программу или подключиться к уже запущенной программе в интерактивном режиме (например для запуска отладчика). Ниже рассмотрено несколько вариантов запуска интерактивных программ.
Запуск интерактивной программы
Для взаимодействия с пользователем через текстовый интерфейс программа обращается к специальному устройству — псевдотерминалу (pseudo teletype, PTY). Для создания такого устройства на узлах необходимо указать команде srun опцию --pty.
В примере ниже для задачи выделено два узла, но интерактивный интерпретатор командной строки запущен только на первом из них.
[host]$ srun -n 36 -t 40 --pty bash
[node19]$ echo $SLURM_NODELIST
node[19,23]
Если вы работаете в графической среде XWindow (клиенты X2Go, Mobaxterm и т.п.), то по такой же схеме можно запускать на узлах задачи с графическим интерфейсом. Единственное отличие — при запуске надо добавить опцию --x11. По умолчанию графический вывод возможен с любого из выделенных узлов.
[host]$ srun -n 8 -N 1 -t 40 --pty --x11 matlab
Подключение к запущенной задаче
Для подключения к уже запущенной задаче необходимо знать её идентификатор и список узлов. На кластере "Уран" для этого служит команда mps, которая разворачивается в команду squeue:
squeue -a -u $USER -o '%.9i %.5P %.8j %.8u %.20S %.4T %.9M %.9l %.5D %R
Получив идентификатор задания его можно указать в параметре --jobid. Дополнительно в параметре -w можно указать узел, к которому надо подключиться. По умолчанию выполняется подключение к первому из узлов.
Пример подключения к задаче отладчиком gdb:
[host]$ srun -p debug -n 36 -t 40 myprog &
[host]$ mps
JOBID PARTI NAME USER START_TIME STAT TIME TIME_LIMI NODES NODELIST(REASON)
10323407 debug bash user8 2020-06-25T10:48:45 RUNN 1:52 3:00 3 node[31-32,46]
[host]$ srun --jobid=10323407 -w node46 --pty bash
[node46]$ ps ax | grep myprog
9556 ? S+ 0:00 myprog
[node46]$ gdb -p 9556
Веб-интерфейс
Многие современные пакеты, такие как Jupiter Notebook или Tensor Board имеют встроенный веб-сервер, который обеспечивает взаимодействие с программой через веб-браузер. В этом случае возможно запустить сервер на узле, а браузер на хост-машине или на домашнем компьютере пользователя.
Запуск браузера на домашнем компьютере требует дополнительных настроек, связанных с пробросом портов, и здесь рассматриваться не будет.
Далее предполагается, что пользователь кластера использует подключение с поддержкой графической среды XWindow (клиенты X2Go, Mobaxterm и т.п.). Поскольку запускаемые скрипты требуют выполнения нескольких команд, они оформлены в виде файлов, которые могут запускаться как через srun, так и через sbatch.
В скриптах номера портов TCP выбираются на основе UID пользователя и базового смещения большего 1024. Это должно обеспечить возможность одновременного запуска скрипта на одном узле несколькими пользователями. Если порт случайно оказался занят, то можно поменять базу (в пределах 2000-20000) и попробовать запустить скрипт снова.
Запуск Jupiter Notebook
Для запуска Jupiter Notebook на узле, необходимо передать ему опцию --no-browser и IP адрес сетевой карты (иначе будет использован IP 127.0.0.1). Можно настроить авторизацию по паролю, отредактировав файл ~/.jupyter или выполнив команду jupyter notebook password, но авторизации по токену будет достаточно.
Скрипт запуска jupiter_slurm.sh
#!/bin/sh
#SBATCH -J jupiter_notebook # Job name
HOST=$(hostname -i)
unset XDG_RUNTIME_DIR
jupyter notebook --no-browser ---ip=$IP
Запустив скрипт и дождавшись сообщения с URL и токеном можно запустить браузер и подключиться к своему JupiterNotebook.
[host]$ srun -n1 -t60 jupiter_slurm.sh &
...
[I 11:59:00.782 NotebookApp] The Jupyter Notebook is running at:
[I 11:59:00.782 NotebookApp] http://192.168.100.19:8888/?token=e5044d65c85c7759e428667826fca80e96f6c3178e754931
[host]$ firefox http://192.168.100.19:8888/?token=e5044d65c85c7759e428667826fca80e96f6c3178e754931
Запуск Tensor Board
Запуск Tensor Board в целом аналогичен запуску Jupiter Notebook. В отличие от Jupiter Notebook у Tensor Board нет парольной защиты, так что теоретически возможно подключение к вашей Tensor Board какого-то пользователя кластера. При необходимости, эта проблема будет решаться административным путём — отключением слишком любопытных пользователей.
Скрипт запуска tensorboard_slurm.sh
#!/bin/sh
#SBATCH -J tensor_board # Job name
HOST=$(hostname -i)
tensorboard --host=$HOST --logdir=$1
Запуск:
[host]$ srun -n1 -t60 tensorboard_slurm.sh ./mylogdir &
...
TensorBoard 2.2.1 at http://192.168.100.19:6006/ (Press CTRL+C to quit)<enter>
[host]$ firefox http://192.168.100.19:6006
Примеры запуска задач в SLURM
Примеры постановки задач в очередь
u9999@umt:~$ sbatch -n 3 --wrap="srun myprog 3 5.1"
Submitted batch job 776
сформирована пакетная задача с запуском 3-х процессов mytest1 c 2-мя параметрами. Задаче присвоен уникальный идентификатор 776.
u9999@umt:~$ srun -N 2 sleep 30 &
[1] 22313
сформирована интерактивная задача в фоновом режиме. [1] - номер фоновой задачи в текущем сеансе, 22313 - pid процесса srun на управляющей машине. Уникальный идентификатор можно узнать с помощью команд squeue, sacct.
Многопоточная задача на одном узле
srun -n1 --cpus-per-task=12 myprog
Запуск одного процесса на одном узле с выделением ему 12 ядер.
Запуск задачи с GPU
Один процесс, которому выделена одна видеокарта модели K40m
srun -n1 -p tesla --gres=gpu:k40m:1 my_cuda_prog
Один процесс, которому выделена восемь видеокарт модели a100
srun -n1 -p hiperf --gres=gpu:a100:8 my_cuda_prog
Один процесс, которому нужна одна видеокарта модели v100 или a100
srun -n1 -p hiperf --gres=gpu:1 my_cuda_prog
Возможные варианты видеокарт в 2024 году: m2090, k40m, v100, a100
Запуск задачи с большим объёмом ОЗУ
srun -n3 -С bigmem myprog
Свойством bigmem помечены узлы с памятью 192 Гбайт и более (96 Гбайт в разделе debug).
Пример задачи, рестартующей после истечения заказанного времени
Все опции запуска описаны в batch-файле. За 60 секунд до окончания заказанного времени все процессы, запущенные через srun получат сигнал TERM и завершатся, после чего последняя команда в скрипте restart_sbatch снова поставит его в очередь. Перезапуск произойдёт и в том случае, когда программа, запущенная через srun завершится самостоятельно.
Опция --signal задаёт номер сигнала, который будет отправлен процессам (KILL) и время отправки сигнала (60 секунд до конца заказанного времени счёта).
Запуск
sbatch restart_sbatch
Содержимое restart_sbatch:
#!/bin/sh
#SBATCH -n 1 -t 180
#SBATCH --signal=KILL@60
srun myprog arg1 arg2
# здесь можно вставить анализ результатов,
# формирование новых параметров,
# проверку условий завершения
# и т.п.
sbatch ./restart_sbatch
Просмотр информации о кластере
squeue sacct sinfo scontrol характеристики GPU
squeue — просмотр очереди (информации о задачах, находящихся в счете или в очереди на счет); возможно использование ключей, например:
squeue --user=`whoami` # посмотреть только свои задачи;
squeue --states=RUNNING # посмотреть считающиеся задачи;
squeue --long # выдать более подробную информацию.
Пример
u9999@umt:~$ srun -N 2 sleep 30 &
[1] 22313
u9999@umt:~$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
777 all sleep u9999 R 0:23 2 umt[10,15]
- JOBID — уникальный идентификатор задачи; никогда не используется повторно ;
- PARTITION — название раздела, где считается задача;
- NAME — имя задачи пользователя;
- USER — логин пользователя;
- ST — состояние задачи
- R - выполняется,
- PD - в очереди;
- TIME — текущее время счета;
- NODES — количество узлов для задачи;
- NODELIST(REASON) — список выделенных узлов.
sacct — просмотр задач текущего пользователя за сутки (с начала текущего дня);
возможно использование ключей, например:
sacct -u u9999 --starttime 2019-01-01 # посмотреть все задачи пользователя u9999 с начала года.
Пример
u9999@umt:~$ sacct
JobID JobName Partition AllocCPUS State ExitCode
--------- ---------- ---------- ------------ ------------- --------
522 sbatch tesla 2 COMPLETED 0:0
522.batch batch 1 COMPLETED 0:0
777 sleep all 2 CANCELLED+ 0:0
780 sbatch tesla 2 FAILED 0:0
780.batch batch 1 FAILED 127:0
783 sleep tesla 2 RUNNING 0:0
- JobID — уникальный идентификатор задачи, повторно не используется;
- JobName — имя задачи пользователя;
- Partition — название раздела, где считается задача;
- State — состояние задачи:
- RUNNING — выполняется,
- PENDING — ждёт в очереди,
- COMPLETED — закончилась,
- FAILED — закончилась по ошибке,
- CANCELLED+ — снята пользователем;
- ExitCode — код возврата.
sinfo — просмотр информации об узлах (прежде всего, о состоянии узлов: доступны, заняты, свободны, ...);
возможно использование ключей, например:
sinfo -s # выдача суммарной информации о разделах кластера без детализации по узлам.
Пример
u9999@umt:~$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
umt* up 8:00:00 4 down* umt[59,92,139,201]
umt* up 8:00:00 203 idle umt[1-58,60-91,93-118,120-138,140-200,202-208]
umt* up 8:00:00 1 down umt119
tesla up 8:00:00 1 alloc tesla2
tesla up 8:00:00 18 idle tesla[3-20]
tesla up 8:00:00 1 down tesla1
- PARTITION — название раздела, где считаются задачи,
* - указывает на раздел по умолчанию; - AVAIL — состояние раздела узлов: up - есть доступ, down - нет доступа;
- TIMELIMIT — максимальное время, выделяемое для счета задачи;
- NODES — количество узлов;
- STATE — состояние (в сокращённой форме):
- idle - свободен,
- alloc - используется процессом,
- mix - частично занят, частично свободен,
- down, drain, drng - заблокирован,
- comp - все задания, связанные с этим узлом, находятся в процессе завершения;
- * - обозначает узлы, которые в настоящее время не отвечают (not responding);
- NODELIST — список узлов.
Пример выдачи sinfo из команд mqinfo и mps:
PARTITION SOCKET CORE CPU THREAD GRES TIMELIMIT CPUS(A/I/O/T)
umt 2 4 8 1 20:00:00 1203/53/408/1664
tesla 2 6 12 1 gpu:8 infinite 322/2/36/360
all* 2 4+ 8+ 1 20:00:00 1525/55/444/2024
- PARTITION — название раздела: umt, tesla, all; * отмечен раздел по умолчанию;
- SOCKET — число процессоров на узле;
- CORE — число ядер в процессоре;
- CPU — число ядер на узле;
- THREAD — число нитей на ядро;
- GRES — число общих для узла ресурсов, где gpu - графический ускоритель;
- TIMELIMIT — максимальное время, выделяемое для счета задачи;
- CPUS(A/I/O/T) — число ядер:
- A (alloc) - заняты,
- I (idle) - свободны,
- O (other) - заблокированы,
- T (total) - всего.
scontrol — выдача детальной информации об узлах, разделах, задачах:
scontrol show node tesla34 # информация об узле,
в частности, причине состояния drain, down;
scontrol show partition # о разделах;
scontrol show job 174457 # о задаче.
Информацию о технических характеристиках GPU выдает программа nvidia-smi:
srun --gres=gpu:1 nvidia-smi
Опция вида -w tesla21 позволяет выдать эту информацию для конкретного узла, например:
u9999@umt:~$ srun -w tesla21 --gres=gpu:1 nvidia-smi
Fri Jun 14 17:15:57 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 390.46 Driver Version: 390.46 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M2090 On | 00000000:09:00.0 Off | Off |
| N/A N/A P12 28W / N/A | 0MiB / 6067MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M2090 On | 00000000:0A:00.0 Off | Off |
| N/A N/A P12 27W / N/A | 0MiB / 6067MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla M2090 On | 00000000:0D:00.0 Off | Off |
| N/A N/A P12 28W / N/A | 0MiB / 6067MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla M2090 On | 00000000:33:00.0 Off | Off |
| N/A N/A P12 28W / N/A | 0MiB / 6067MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Дополнительная информация о характеристиках GPU доступна с помощью программы pgaccelinfo (входит в поставку компилятора PGI). Для получения информации о конкретном узле, используя опцию -w, следует набрать:
u9999@umt:~$ mpiset 7
u9999@umt:~$ srun -w tesla21 --gres=gpu:1 pgaccelinfo
Удаление задач из очереди
При запуске на кластере задача попадает в очередь заданий и ей присваивается уникальный идентификатор (ID). Для отмены выполнения задачи (ожидающей счета или уже стартовавшей) служит команда scancel:
scancel 565 345 # убрать из очереди задачи с указанными ID;
scancel -u u9999 # убрать из очереди все задачи пользователя u9999;
scancel --state=PENDING -u u9999 # убрать из очереди ожидающие запуска задачи пользователя u9999.
CTRL+C— снимает интерактивную задачу без фонового режима.
Пример. Снятие интерактивной задачи, запущенной в фоновом режиме.
u9999@umt:~$ srun -p tesla -N 2 sleep 1h &
[1] 13847
u9999@umt:~$ mps
PARTITION SOCKET CORE CPU THREAD GRES TIMELIMIT CPUS(A/I/O/T)
umt 2 4 8 1 20:00:00 0/0/768/768
umt_p2 2 4 8 1 20:00:00 0/0/512/512
tesla 2 6+ 12+ 1 gpu:8 20:00:00 234/2/12/248
...
JOBID PARTI NAME USER STAT TIME TIME_LIMI NODES NODELIST(REASON)
7650963 tesla sleep u9999 RUNN 0:21 30:00 2 tesla[2,4]
Завершаем задачу:
u9999@umt:~$ scancel 7650963
srun: Force Terminated job 7650963
u9999@umt:~$ srun: Job step aborted: Waiting up to 32 seconds for job step to finish.
slurmstepd: error: *** STEP 7650963.0 ON tesla2 CANCELLED AT 2019-08-20T12:59:13 ***
srun: error: tesla4: task 1: Terminated
srun: error: tesla2: task 0: Terminated
Надо нажать Enter
[1]+ Exit 143 srun -p tesla -N 2 sleep 1h
u9999@umt:~$ mps
PARTITION SOCKET CORE CPU THREAD GRES TIMELIMIT CPUS(A/I/O/T)
umt 2 4 8 ...
JOBID PARTI NAME USER STAT TIME TIME_LIMI NODES NODELIST(REASON)
u9999@umt:~$
Docker на кластере
Введение
Технология Docker позволяет создавать виртуальную среду исполнения. По сравнению с виртуальными машинами накладные расходы на виртуализацию составляют менее 1%.
С точки зрения пользователя данная технология даёт возможность настраивать среду исполнения и воспроизводить ее на разных компьютерах. Внутри контейнера у пользователя имеются права суперпользователя, что позволяет устанавливать необходимые пакеты без привлечения администратора кластера. Кроме того, Docker может работать с графическими ускорителями, что является очень полезным, например, при работе с библиотеками глубинного обучения.
Стандартная реализация Docker, позволяет пользователю получить права суперпользователя на хостовой машине, что неприемлемо с точки зрения безопасности. Поэтому на кластере используются альтернативная реализация — podman, которая устраняет данный недостаток. Podman имеет ряд особенностей, о которых будет написано ниже.
Для общего понимания технологии Docker можно ознакомиться с шестью статьями на Хабре.
Файлы и каталоги
Пользовательская конфигурация podman хранится в каталоге ~/.config/container. Стандартное размещение данных— ~/.local/share/container, но, поскольку podman не совместим с файловой системой NFS, то на кластере для хранения образов используется локальный каталог /tmp. Это значит, что копии каждого используемого образа будут создаваться по мере необходимости в каталоге /tmp на каждом вычислительном узле. Соответственно, не стоит использовать копирование входных/выходных данных между контейнером и домашним каталогом. Лучше использовать монтирование домашнего каталога внутрь образа при запуске с помощью опции -v $HOME:$HOME
Конфигурация хранилища данных для каждого пользователя кластера описана в ~/.config/containers/storage.conf и имеет вид
[storage]
driver = "vfs"
runroot = "/tmp/u9999_run"
graphroot = "/tmp/u9999_storage"
[storage.options]
mount_program = ""
где u9999 надо заменить на свой логин
Запуск готовых образов из публичных реестров
В конфигурации podman на кластере "Уран" в файле /etc/containers/registries.conf подключены публичные реестры registry.access.redhat.com, docker.io, registry.fedoraproject.org, quay.io, registry.centos.org и локальный реестр 172.16.0.1:5000. Если требуется добавить свое хранилище или убрать поиск в вышеперечисленных, то можно скопировать конфигурационный файл в свой каталог ~/.config/container/ и отредактировать копию.
Подготовка и сборка своего образа
На одном из компьютеров кластера по адресу 172.16.0.1:5000 организован локальный Docker-реестр, который может быть использован пользователями кластера для хранения своих образов. ВНИМАНИЕ. Доступ к реестру осуществляется без авторизации и поэтому есть небольшой риск, что кто-то испортит или удалит ваш образ.
При подготовке образа рекомендуется предварительно произвести сборку на локальной машине и убедится в корректности Dockerfile. Сборка контейнера с использованием podman происходит дольше, чем с использованием стандартного docker. Поэтому желательно осуществлять сборку контейнеров на узлах кластера с помощью планировщика SLURM. Для этого можно выполнить команду:
srun -c 8 --mem 10000 --pty bash
В результате мы попадём на один из вычислительных узлов, на котором можно выполнять сборку. Команда сборки запускается из каталога, где находится Dockerfile и должна иметь примерно следующий вид:
docker build -t <tag> <directory>
Пример
docker build -t hello_docker .
Важно понимать, что после сборки контейнер будет находиться в каталоге /tmp на узле, на котором производилась сборка. Чтобы контейнер можно было использовать на других узлах, его необходимо скопировать в общественное хранилище на кластере с помощью следующей команды:
docker push --tls-verify=false localhost/hello_docker 172.16.0.1:5000/hello_docker
Также обе команды можно выполнить за одной задачей, выполнив:
srun -c 8 --mem=10000 bash -c 'docker build -t hello_docker . && docker push --tls-verify=false localhost/hello_docker 172.16.0.1:5000/hello_docker
ВАЖНО. Так как на общественном хранилище не настроена авторизация, то при создании контейнеров необходимо использовать уникальные имена, например, используя в качестве префикса имя пользователя.
Минимальный Dockerfile приведен в приложении 1. Bash скрипт для сборки и загрузки контейнера в общее хранилища приведен в приложении 2.
Запуск образа
Запуск осуществляется следующей командой:
srun -c 8 --mem=10000 docker run -v ~:/work -t hello_docker ls /work
если образ на узле отсутствует, то он будет подтянут из реестра автоматически. При следующих запусках на том же узле будет повторно использована сохраненная на этом узле копия образа.
В данном случае опция -v ~:/work указывает на то, что домашний каталог пользователя будет смонтирован в каталог /work внутри контейнера. Если в вашей программе или скриптах используется путь к домашнему каталогу, то можно попробовать другой вариант -v $HOME:$HOME, который смонтирует домашний каталог в контейнере под тем же именем, под которым он виден вне контейнера.
Вместо команды ls /work может присутствовать любая другая команда с параметрами.
При запуске можно добавить в образ дополнительные библиотеки:
srun -c 8 --mem=10000 docker run -v ~:/work -v /common/user/gpu_libs:/gpu_libs -e LD_LIBRARY_PATH=/gpu_libs -t hello_docker ls /work
Bash скрипт для запуска контейнера с использованием GPU приведен в приложении 3.
Приложение 1. Минимальный Dockerfile
FROM ubuntu:18.04
VOLUME /work
WORKDIR /work
CMD ['ls']
Приложение 2. Bash скрипт для сборки контейнера
CONTAINER_NAME=hello_docker
docker build -t $CONTAINER_NAME .
docker push --tls-verify=false localhost/$CONTAINER_NAME 172.16.0.1:5000/$CONTAINER_NAME
Приложение 3. Bash скрипт для запуска контейнера
CONTAINER_NAME=hello_docker
docker pull --tls-verify=false 172.16.0.1:5000/$CONTAINER_NAME
CUDA=""
if [ -e /dev/nvidiactl ]; then
DEVICES=(/dev/nvidia*)
CUDA=${DEVICES[@]/#/--device }
fi
docker run $CUDA -v ~:/work -t $CONTAINER_NAME ls /work
Приложение 4. Пример сообщений при загрузке образа
$> srun -n 1 --mem=10000 --output=quad.txt docker run -v $HOME:$HOME -ti tkralphs/coinor-optimization-suite cbc $HOME/coin-or/Cbc/examples/quad.mps
$> less quad.txt
Trying to pull 172.16.0.1:5000/tkralphs/coinor-optimization-suite...
manifest unknown: manifest unknown
Trying to pull registry.access.redhat.com/tkralphs/coinor-optimization-suite...
name unknown: Repo not found
Trying to pull docker.io/tkralphs/coinor-optimization-suite...
Getting image source signatures
Copying blob sha256:14f491cdf5e5dfff3f9296e85ea5f0ed7ed792a0df58fd753e5a53aa72dda67f
Copying blob sha256:53e3366ec435596bed2563cc882ba47ec25df6be2b1027e3243e83589c667c1e
Copying blob sha256:ee690f2d57a128744cf4c5b52646ad0ba7a5af113d9d7e0e02b62c06d35fd14c
Copying blob sha256:e92ed755c008afc1863a616a5ba743b670c09c1698f7328f05591932452a425f
Copying blob sha256:c596d3b2f1a98fc3d58eb98ff4de80a9bd7c50f8118e89189ec25c1b4c9678cb
Copying blob sha256:b9fd7cb1ff8f489cf082781b0e1fe0c13b840e20147e8fc8204b4592da7c2f70
Copying blob sha256:891eb02d766a3e5408f240128347472983067be41493f1a10cf6216574f614f0
Copying blob sha256:42f559670afb72a15465e2a0785122587c284f0cbfb7b7883bc0f27e6e999a32
Copying blob sha256:87ef252adc7d4cab8eae16d70cc529d70c857d964309e13c3a9d64b6b49670d8
Copying blob sha256:8f85d5b3b6ecc7367bb8186917017bcba3d916c08ffcea240b896b2e562fe0fa
Copying blob sha256:38e446e2e1f2ec785a4ad5e49af8cfcd34027a915c3b5d40732eeb65f66b5019
Copying config sha256:c9697bd9dae0a80bf39e3feca37bc7b4ef9a6efa03269870cb7d15f51426999c
Writing manifest to image destination
Storing signatures
....
Python-скрипты на кластере
1. Структура python-скрипта
Здесь предполагается, что python-скрипт - это текст программы, написанной на языке, понимаемом интерпретатором python соответствующей версии, и начинающейся со строки следующего вида с заменой 'N.N' на номер версии (например, на 3 или на 3.9).
#!/usr/bin/env pythonN.N
В этом случае имя python-скрипта может быть непосредственно передано команде sbatch в качестве имени исполняемого файла для постановки задачи на выполнение на вычислительных узлах кластера. После первой строки могут быть добавлены строки вида #SBATCH ... с заказом требуемых задаче ресурсов (см. man sbatch).
2. Каталог ~/.local
При использовании python надо понимать, что на вычислительных узлах разрешено писать лишь в подкаталоги каталогов ~/_scratch и ~/_scratch2, а некоторые модули python используют каталог ~/.local
для записи временных подкаталогов и файлов. Значит, перед использованием python (в частности, до установки своих модулей) следует убедиться, что каталог ~/.local - это ссылка на ~/_scratch/.local, выполнив команду ls -l ~/.local. Если это не так, то нужно переместить каталог ~/.local в одну из указанных папок, выполнив, например, команды
mv ~/.local ~/_scratch/
ln -s ~/_scratch ~/.local
3. Установка новых модулей к имеющимся версиям python
На кластере "Уран" установлено несколько версий python. В силу того, что некоторые модули системы python требуют настройки на конкретные версии системного ПО кластера, установка необходимых дополнительных модулей python осуществляется самим пользователем в зависимости от потребностей запускаемых им программ.
При использовании менеджера пакетов pip (см. man pip) для установки недостающих пакетов следует указывать опцию --user, чтобы дополнительные пакеты устанавливались в специальный каталог конкретного пользователя и не влияли на работу других пользователей, и, вызывать версию pip, соответствующую используемой версии python.
Пример:
pip3.9 install --user mpi4py
4. Работа с именованными виртуальными средами выполнения (virtual environment)
Создание виртуальных сред выполнения (комплектов пакетов) и переключение на работу с ними рекомендуется осуществлять через менеджеры пакетов conda или mamba, а также с помощью специальных скриптов, обеспечивающих такую настройку.
Так команда
source /opt/intelpython39/bin/activate
переключает на работу с относительно свежей версией python3.9 с установленными дополнительно библиотеками pandas, jupyter, scikit-image, h5py, pillow, networkx, protobuf и opencv. Для работы программ, использующих видеокарты для машинного обучения, в этой версии python также установлены pytorch, tensorflow, keras, которые собраны на базе cuda 11.8. Кроме того, будет доступен менеджер пакетов mamba.
Написание и запуск параллельных python-скриптов
MPI
Модуль mpi4py делает возможным формирование нескольких mpi-процессов с обменом сообщениями (данными) между ними даже тогда, когда они выполняются на разных вычислительных узлах (см. https://mpi4py.readthedocs.io/en/stable/tutorial.html).
Например, команда
pip3.9 install --user mpi4py
установит пакет mpi4py в подкаталог .local домашнего каталога пользователя. После этого при выполнении python-скрипта со строкой
from mpi4py import MPI
утилита python3 найдёт установленный модуль (при условии, что python3 эквивалентно python3.9).
На вычислительных узлах модуль mpi4py будет правильно стыковаться с нужной реализацией MPI, если перед запуском выбрать (командами mpiset ... или module switch ...) конкретную реализацию стандарта MPI или задать предварительную загрузку соответствующей библиотеки, задав её имя в переменной LD_PRELOAD, например, выполнив команду
export LD_PRELOAD=/opt/mvapich2/lib/libmpich.so
Постановка в очередь таких python-скриптов осуществляется командами, подобными упрощённой
mqrun -n 4 -t 5 ./testmpi.py
или базовой
sbatch -n 4 -t 5 -J test --wrap='srun ./testmpi.py'
Здесь srun необходима для формирования группы из заданного числа MPI-процессов.
Предполагается, что предварительно было выполнено
cd ~/_scratch/tests
и скрипт ./testmpi.py находится в каталоге ~/_scratch/tests.
OpenMP
Модуль pymp устанавливается командой
pip install --user pymp-pypi
и позволяет, добавив специальные строки в python-скрипт по аналогии с декларациями OpenMP в C- и fortran-программах, образовать несколько подпроцессов с имитацией общих массивов данных, например, для ускорения выполнения длительного цикла за счёт привлечения дополнительных вычислительных ядер процессора (см. https://github.com/classner/pymp ).
Понятно, что такие python-скрипты должны выполняться лишь на одном вычислительном узле, так как массивы переменных (располагающиеся в оперативной памяти) должны быть доступны всем подпроцессам. В команде постановки в очередь необходимо указать дополнительно количество вычислительных ядер на подзадачу
sbatch -n 1 --cpus-per-task=4 -t 5 -J test ./testmp.py
Предполагается, что предварительно было выполнено
cd ~/_scratch/tests
и скрипт ./testmp.py находится в каталоге ~/_scratch/tests.
Ограничения по ресурсам
1. Размер дисковой квоты для пользователей ограничен 100 GB.
Уточнить размер квоты и места на диске, занимаемого пользователем, можно с помощью команд quotacheck и du (см. инструкцию Базовые команды ОС UNIX).
Внимание! Возможно появление ошибок при запуске задач, если квота дискового пространства исчерпана. Рекомендуется удалять ненужные файлы, а нужные результаты переписывать на свою машину. Так будет надежнее, т.к. гарантии сохранности файлов на кластере нет.
2. Одновременно считающиеся задачи пользователя могут занимать до 1024 CPU (вычислительных ядер).
3. Максимальное время, выделяемое для счета задачи:
20 часов - в будние дни,
84 часа - на выходные,
100 часов - на выходные с праздниками.
Если пользователь не закажет время, то по умолчанию для решения задачи будет выделено 30 минут. (Подробнее в инструкции Команды запуска SLURM) .
Замечание.
Дополнительная информация об ограничениях может выдаваться при входе на кластер.
Учёт источника финансирования
В системе SLURM предусмотрено деление пользователей на учётные группы (account). Каждая учётная группа - это совокупность пользователей, работающих над одним проектом. На основе активности учётной группы определяются приоритеты для всех её членов. Затраты машинного времени членов учётной группы автоматически суммируются в статистике.
С 2019 года в СКЦ ИММ УрО РАН введены учётные группы на основе источников финансирования, указанных в заявках и договорах. Такое деление позволяет уравнять приоритеты организаций, которые подали в заявках информацию об одном-двух пользователях суперкомпьютера, с группами, которые включают большое количество пользователей.
Пользователь может состоять в нескольких учётных группах и запускать задачи от их имени. Одна учётная группа пользователя считается группой по умолчанию и используется в тех случаях, когда пользователь не указывает явно группу при запуске задачи.
Для смены учётной группы, используемой по умолчанию командами запуска задач, можно выполнить команду macctmgr. Для явного указания учётной группы в командах srun и sbatch используйте опцию -A <имя_группы>.
Просмотр учётных групп производится командой sacctmgr, просмотр статистики работы - командой sreport.
Просмотр списка учётных групп
$ sacctmgr show -s user u9999 format=user,defaultaccount%30,account%30,qos
User Def Acct Account QOS
---------- ------------------------------ ------------------------------ --------------------
u9999 imm-2019-1 2019-99-19 restricted
u9999 imm-2019-1 imm-2019-2 normal
u9999 imm-2019-1 imm-2019-1 normal
u9999- имя пользователя.-sуказывает, что надо выдать связанные с пользователем учётные группыformat=задает список полей (и их ширину через%)
В данном случае, пользователь u9999 входит в три учетные группы - 2019-99-19, imm-2019-1, imm-2019-2. По умолчанию используется группа imm-2019-1.
Поле QOS (quality of service) описывает ограничения, накладываемые на сочетание пользователь + учётная группа. normal - обычные ограничения, restricted - запуск задач запрещён.
Просмотр своих учётных групп
sacctmgr show -s user $USER format=user,defaultaccount%30,account%30,qos
Запуск от имени учетной группы
Явно указать учётную группу при запуске через srun или sbatch можно с помощью опции-A или --account=
srun --account=2019-99-19 myprog
srun -A 2019-99-19 myprog
Просмотр описания учётной группы
$ sacctmgr show account imm-2019-1 format=account%15,description%30,organization
Account Descr Org
--------------- ------------------------------ ------
imm-2019-1 АААА-А19-999999999999-1 imm
В поле description вносится описание учётной группы, как правило в виде номера регистрации проекта в РосРИД или номера договора с ИММ УрО РАН.
Просмотр статистики по пользователю за определённый срок
$ sreport cluster AccountUtilizationByUser start=2019-01-01 end=2019-06-01 user=u9999
Usage reported in CPU Minutes
----------------------------------------------------------------
Cluster Account Login Proper Name Used Energy
--------- ----------- ------ --------------- -------- --------
umt imm-2019-2 u9999 TestUse+ 9437 0
umt imm-2019-1 u9999 TestUse+ 4442 0
В отчёт попадают только реально использовавшиеся группы.
Просмотр статистики по учётной группе за определённый срок
$ sreport cluster AccountUtilizationByAccount start=2019-01-01 end=2019-06-01 account=imm-2019-1
--------------------------------------------------------------------------------
Usage reported in CPU Minutes
--------------------------------------------------------------------------------
Cluster Account Login Proper Name Used Energy
--------- ----------- ------ ------------ ---------- --------
umt imm-2019-1 27411385 0
umt imm-2019-1 u9990 User1 266 0
umt imm-2019-1 u9991 User2 6098924 0
umt imm-2019-1 u9992 User3 7431731 0
umt imm-2019-1 u9999 User4 13880463 0
Выбор версии MPI и компилятора
Для выбора компиляторов, библиотек обмена сообщениями и пакетов прикладных программ, необходимых для работы программы пользователя, используются модули установки переменных окружения.
Команда mpiset позволяет выбрать модуль из списка основных модулей, задающих компилятор и версию библиотеки MPI.
Команда mpiset без параметров выдает пронумерованый список доступных вариантов. Строка, помеченная словом active, указывает на текущие настройки.
Для смены модуля (библиотеки MPI, компилятора) необходимо выполнить команду
mpiset <n>
где <n> – номер варианта настроек для данного кластера.
Пример. Список основных вариантов настроек, полученный в начале сеанса 28.12.2016 командой mpiset на кластере "Уран":
active 1 MVAPICH2 Intel 14.0, mvapich2/intel64
2 OpenMPI Intel 11.1, openmpi/intel64
3 OpenMPI 32bit GCC 4.4, openmpi/gcc32
4 OpenMPI 32bit Intel 14.0, openmpi/intel32
5 OpenMPI GCC v4.4, openmpi/gcc64
6 OpenMPI v1.10 GCC 4.8, openmpi/gcc64_1.10
7 MVAPICH2 2.1 PGI 16.5, mvapich2/pgi_16.5
8 Intel MPI Intel Compiler 17.0, intelmpi/intel64
Команда module - выбор окружения для решения задачи
При работе на кластере можно использовать различные компиляторы, библиотеки обмена сообщениями и пакеты прикладных программ (приложения), поэтому пользователь должен определить среду для решения своей задачи, выбрав нужное программное обеспечение. Выбор определяется модулем установки переменных окружения, требуемых для работы программы. Названия модулей содержат имена компиляторов, библиотек, пакетов, номера версий. Например, при загрузке модуля openmpi/intel64 программа пользователя будет откомпилирована 64-разрядным компилятором intel с библиотекой openmpi.
Список загруженных на настоящий момент модулей можно выдать с помощью команды module list.
Сервисная команда mpiset служит для быстрой смены модуля, задающего компилятор и версию библиотеки MPI.
Списки доступных модулей на кластерах могут отличаться и пополняться с введением нового программного обеспечения.
Пример. Список модулей, доступных на кластере umt на 01.07.2011, выданный с помощью команды module avail
OpenFoam/1.7.x matlab/R2010b openmpi/gcc64
dvm/current mpi/default openmpi/intel64
firefly/71g-openmpi music/4.0 paraview/3.10
matlab/R2010a mvapich2/intel64 towhee/6.2.15
В целом, работа с модулями обеспечивается командой module.
module avail- вывод на экран списка доступных модулей;module list- вывод на экран списка загруженных (на данный момент) модулей;module show <имя модуля из списка>- вывод на экран полного имени файла с описанием команд изменения окружения, выполняемых при загрузке модуля;module whatis <имя модуля из списка>- вывод на экран комментария к модулю;module whatis- вывод на экран списка модулей с комментариями;module load <имя модуля из списка>- загрузка модуля; после выполнения данной команды (из командной строки или конфигурационного файла) среда исполнения будет настроена на использование программного обеспечения, соответствующего указанному модулю;module unload <имя загруженного модуля>- выгрузка модуля отменит настройки переменных окружения, задаваемых данным модулем;module switch <имя загруженного модуля> <имя модуля>- замена загруженного модуля (первого) на указанный модуль (второй);module clear- выгрузка всех загруженных на текущий момент модулей.
Внимание!
- Настройка с помощью команд
mpisetилиmoduleимеет силу на текущий сеанс работы на кластере. - Для того, чтобы не настраивать заново в начале каждого сеанса работы среду исполнения для решения своей задачи, можно нужные настройки сохранить в файле
$HOME/.bash_profileпользователя, используя следующие команды:
module initadd <имя модуля из списка доступных>- меняет$HOME/.bash_profile, загружая указанный модуль для следующих сеансов работы;module initlist- выдаёт список загруженных в$HOME/.bash_profileмодулей для следующих сеансов работы;module initclear- чистит$HOME/.bash_profile, оставляя лишь модульnull, который не содержит никаких настроек.
Компиляция и запуск приложений с OpenMP
OpenMP подключается опцией, соответствующей установленному компиляторy:
gcc/gfortran -fopenmp GNU
icc/ifort -openmp Intel (по умолчанию на umt)
pgcc/pgCC/pgf77/pgfortran -mp PGI
Так, компиляция файла exam.c на umt компилятором Intel (с учетом умолчания) выполняется командой
icc -openmp exam_omp.c -o exam_omp
или командой
mpicc -openmp exam_omp.c -o exam_omp
Число параллельных нитей OpenMP задается с помощью переменной окружения OMP_NUM_THREADS. Как правило, она устанавливается перед запуском программы из командной строки командой вида
export OMP_NUM_THREADS=8
Если число нитей больше числа выделенных процессу ядер, то, по крайней мере, одно ядро будет исполнять более одной нити, что целесообразно, например, в случае, когда часть нитей имеет меньшую вычислительную активность.
При запуске приложения пользователю необходимо указать число ядер (cpus) для каждого из процессов (task) с помощью опции --cpus-per-task=<ncpus>. При этом система предоставляет узел для процесса, если на нем имеется указанное число свободных ядер. Максимальное число ядер, равное 36, содержат узлы раздела apollo (см. Кластер "Уран"). Пусть задано export OMP_NUM_THREADS=12, тогда в результате выполнения команды интерактивного запуска
srun --cpus-per-task=6 exam_omp > exam_omp.out
одному (n=1 по умолчанию) процессу (task), т.е. задаче, пользователя будет выделено 6 ядер на узле и при вычислениях будет задействовано 12 нитей; результаты вычислений будут записаны в указанный пользователем файл exam_omp.out.
Если программе нужен запуск на узле с большим объёмом оперативной памяти, то надо добавить опцию --mem=<MB>, где <MB> - требуемый объём памяти на узле. Например, команда
srun --mem=48G --cpus-per-task=12 exam_omp > exam_omp.out
запустит один процесс на узле с оперативной памятью не меньшей, чем 48 GB (о типах узлов см. Кластер "Уран"). Для заказа памяти из расчета на одно ядро используется опция --mem-per-cpu=<MB>, например,
srun --mem-per-cpu=4G --cpus-per-task=12 exam_omp > exam_omp.out
В пакетном режиме соответствующий запуск может выглядеть так:
sbatch --mem-per-cpu=4G --cpus-per-task=12 mybat_omp
где файл mybat_omp содержит строки
#!/bin/sh
srun exam_omp > exam_omp.out
В качестве примера программы с OpenMP можно использовать pi_omp.c.
Возможен запуск гибридных MPI/OpenMP приложений с помощью опции --ntasks-per-node=<ntasks>, где <ntasks> - число процессов на узле. Например, для запуска на двух 36-ядерных узлах 6 процессов с 12 нитями каждый можно выполнить команду:
sbatch -N 2 --cpus-per-task=12 --ntasks-per-node=3 my_bat_omp
Запуск параллельного Matlab
ИММ УрО РАН предоставляет пользователям системы Matlab (Матлаб) возможность организации параллельных вычислений на кластере "Уран".
Подробная информация представлена в полной инструкции "Параллельный Matlab".
Число лицензий для вычислений на кластере в настоящее время равно 1000.
Запускать программы на кластере можно из командной строки или из системы Matlab. Для этого на своем компьютере следует установить программу PuTTY и какой-нибудь X-сервер.
Параллельные вычисления на кластере инициируются
1) запуском параллельных програм;
2) запуском частично параллельных программ (c parfor или spmd);
3) запуском программ с использованием GPU.
Программа пользователя должна быть оформлена как функция (не скрипт) и находиться в начале одноименного файла.
Файл должен иметь расширение "m"(например, my_function.m).
При запуске программы-функции указывается необходимое для счета число параллельных процессов и максимальное время выполнения в минутах.
Запуск программ на кластере из командной строки осуществляется с помощью команд:mlrun - для параллельных программ, например,
mlrun -np 8 -maxtime 20 my_parfunctionгде 8 - число копий функции my_parfunction, 20 - максимальное время счета в минутах;
mlprun - для частично параллельных программ (с parfor или spmd), например,
mlprun -np 8 -maxtime 20 my_poolfunctionгде один процесс будет выполнять программу-функцию, а оставшиеся 7 будут использованы в качестве пула для выполнения parfor и spmd;
mlgrun - для программ с использованием GPU, например,
mlgrun -np 8 -maxtime 20 my_gpufunctionгде 8 - число процессов (копий функции), каждый из которых может использовать свое GPU.
Запуск программ на кластере из окна системы Matlab осуществляется с помощью соответствующих служебных функций:imm_sch - для параллельных программ, например,
job1 = imm_sch(8,20,@my_parfunction);
imm_sch_pool - для частично параллельных программ (с parfor или spmd), например,
job2 = imm_sch_pool(8,20,@my_poolfunction);
imm_sch_gpu - для программ с использованием GPU, например,
job3 = imm_sch_gpu(8,20,@my_gpufunction);
В приведенных командах запускаются функции без параметров с использованием 8 процессов, 20 минут - максимальное время счета;
job1, job2, job3 - ссылки на созданные системой Matlab объекты Job (работа). Имя функции можно набрать с символом "@" или в кавычках.
Пример. Для функции с параметрами, например rand, вызываемой для генерации 2х3 матрицы случайных чисел с числом процессов 4 и максимальным временем счета 5 минут, следует соответственно набрать в командной строке
mlrun -np 4 -maxtime 5 rand '1,{2,3}'или в окне Matlab
job = imm_sch(4,5,@rand,1,{2,3});Подробнее в Параллельный Matlab/Запуск параллельной программы/Пример запуска программы.
В результате запуска программа ставится в очередь на счет и, если ресурсов кластера достаточно, входит в решение.
Пользователь может контролировать прохождение своей программы через систему запуска как в окне системы Matlab с помощью Job Monitor, так и из командной строки с помощью команд системы запуска.
Запуск программ из пакета ANSYS
ANSYS - это программный пакет конечно-элементного анализа, решающий задачи в различных областях инженерной деятельности (прочность конструкций, термодинамика, механика жидкостей и газов, электромагнетизм), включая связанные многодисциплинарные задачи (термопрочность, магнитоупругость и т.п).
ANSYS CFX, ANSYS Fluent – самостоятельные программные продукты от ANSYS,Inc., предназначенные для решения стационарных и нестационарных задач механики жидкостей и газов.
/common/runmvs/bin/ansysrun в настоящее время используется для запуска ansys145, cfx5solve и fluent.
Вызов ansysrun без параметров выдает краткую информацию об использовании.
Внимание!
Команды настройки переменных окружения содержатся в файле /common/runmvs/conf/ansys_env.sh, поэтому строка
. /common/runmvs/conf/ansys_env.shдолжна быть в ~/.bashrc.
При отсутствии этой строки выдается диагностика и постановки задания в очередь не происходит.
Примеры.
Запуск ansys145 с 12-ю процессами на 60 минут для выполнения ANSYS-скрипта ansys_s1:
ansysrun -np 12 -maxtime 60 -stdin ansys_s1 ansys145
Запуск на 30 минут ansys145 с 8-ю процессами и использованием GPU с соответствующим увеличением памяти до 3 ГБ (на один процесс) для выполнения ANSYS-скрипта ansys_s2:
ansysrun -np 8 -gpu 8 -m 3G -maxtime 30 -stdin ansys_s2 ansys145
Запуск cfx5solve по 6 (=np/nh) процессов на двух узлах на 100 минут для выполнения bench.def (def-файл ANSYS):
ansysrun -np 12 -nh 2 -maxtime 100 cfx5solve -def bench.def
Запуск fluent c 16 процессами на 400 минут для выполнения my.cav (cav-файл ANSYS) с дополнительным параметром 3ddp:
ansysrun -np 16 -maxtime 400 fluent 3ddp -i my.cavОбщие вопросы
Здесь собраны статьи, так или иначе связанные с работой на суперкомпьютере "Уран"
Отправка сообщений в telegram
Для оперативной связи с программой, запущенной на суперкомпьютере (сообщение о запуске или завершении, отладочные сообщения), можно использовать telegram.
Данная инструкция описывает создание минимального telegram-бота, который умеет отправлять сообщения хозяину.
Регистрируем бота в телеграмм
Для регистрации бота нужно начать чат с отцом ботов https://t.me/BotFather отправив в чат команду /start
Далее выбираем из меню или пишем в чат команду /newbot в ответ будет предложено ввести имя, под которым бот будет виден у вас в списке пользователей (не обязательно уникальное), и идентификатор, уникальный в рамках всего телеграма и заканчивающийся на _bot.
Если идентификатор отвечает этому требованию, то в ответ BotFather пришлет сообщение, содержащее ссылку на бота и token для доступа к API.
Что бы у бота появилась возможность писать вам, вы должны перейти на страничку бота и нажать кнопку "Запустить" (Start)
Как узнать свой ID
Что бы писать себе сообщения нужно знать свой уникальный идентификатор, это можно сделать запустив бота https://t.me/getmyid_bot
Установка бота на суперкомпьютере
Для запуска бота необходимо установить пакеты python3
pip install python-telegram-bot --upgrade --user
после чего можно скопировать пример бота в файл telegram_bot.py, подставив токен api_key и свой user_id. На файл необходимо дать право на выполнение chmod +x telegram_bot.py
#!/usr/bin/env python3.6
import telegram
import sys
api_key = "987654321:XyZwer45Un"
user_id = 1234567890
bot = telegram.Bot(token=api_key)
chunk = sys.stdin.read(4096)
while chunk:
bot.send_message(user_id, chunk)
chunk = sys.stdin.read(4096)
Отправка сообщения делается перенаправлением текста на стандартный ввод бота. Можно отправлять несколько строк, но не более 4096 символов за один раз. Более длинные сообщения разбиваются на части по границам кратным этой величине. В примере предполагается, что вы создали файл telegram_bot.py в домашнем каталоге (~).
echo "Test message" | ~/telegram_bot.py
ls | ~/telegram_bot.py
sbatch -n1 -t1 --wrap \
"bash -c \
'echo Start |~/telegram_bot.py;\
my_prog| ~/telegram_bot.py;\
echo Stop |~/telegram_bot.py'"
Средства визуализации данных
SciDAVis
![]() SciDAVis представляет собой интерактивное приложение, направленное на анализ научных данных и их визуализацию/публикацию. SciDAVis - многоплатформенное - Windows, Linux, MacOS X - свободное программное обеспечение. Данное программное обеспечение совмещает в себе широкую функциональность и интуитивно-понятный интерфейс. SciDAVis позволяет анализировать, обрабатывать и визуализировать экспериментальные данные и аппроксимировать кривые. Поддерживает большое количество аппроксимирующих функций, скрипты, базовые статистики с графиками и визуализацией и многое другое. Основные особенности программы SciDAVis:
SciDAVis представляет собой интерактивное приложение, направленное на анализ научных данных и их визуализацию/публикацию. SciDAVis - многоплатформенное - Windows, Linux, MacOS X - свободное программное обеспечение. Данное программное обеспечение совмещает в себе широкую функциональность и интуитивно-понятный интерфейс. SciDAVis позволяет анализировать, обрабатывать и визуализировать экспериментальные данные и аппроксимировать кривые. Поддерживает большое количество аппроксимирующих функций, скрипты, базовые статистики с графиками и визуализацией и многое другое. Основные особенности программы SciDAVis:
- Генерирование таблиц, матриц, графиков и заметок, собираемых в проекте с удобной организацией.
- Таблицы для ввода данных напрямую или импорта из ASCII-файлов.
- Встроенные операции по анализу статистики.
- Различные форматы публикаций в двухмерном и трехмерном пространствах (включая EPS и PDF). У SciDAVis еще есть функции для расчета корреляции, автокорреляции, свертки и деконволюции.
- Функции взятия прямого и обратного быстрого преобразования Фурье (БПФ, оно же FFT) и функции для работы со спектрами и сигналами.
- (С установленной программой Python у вас появляется доступ к объектам.)
Список встроенных стандартных функций для создания формул
Стандартные функции:
abs, acos, acosh, asin, asinh, atan, atanh, avg
bessel_i0, bessel_i1, bessel_in, bessel_in_zero, bessel_y0, bessel_y1, bessel_yn, beta
ceil, cos, cosh, erf, erfc, erfz, erfq, exp, floor, gamma, gammaln
hazard, if, ln, log, log10, log2, min, max, mod, pow, rint, sign
sin, sinh, sqrt, sum, tan, tanh, w0, wm1
Хранение
SciDAVis хранит все данные в файле своего проекта. В качестве исходных данных программа понимает текстовые файлы, в которых числа записаны столбцами, и файлы, в которых числа разделяются запятыми (CSV). При открытии текстовых файлов в SciDAVis есть возможность указать разделитель между столбцами, разделитель дробной части и символ, отделяющий в больших числах тысячи, миллионы и т.д. для более наглядного вида. Для SciDAVis основная рабочая область – таблица с данными, а графики не привязываются к их расположению на листе, а просто рисуются в отдельных окнах.
Графики могут быть сохранены в нескольких растровых графических форматах файлов, а также в форматах Portable Document Format PDF , Encapsulated PostScript EPS или SVG.
Типы графиков
Программа может рисовать разные типы графиков.
- • Исходные точки на графике могут отмечаться какими-нибудь символами. А можно оставить только эти символы без линий и получится так называемый Scatter.
- • Графики, у которых точки соединяются только горизонтальными и вертикальными линиями, получаются ступеньки.
- • Графики, представляющие собой вертикальные столбики, обычно их называют Bar. Есть отдельный тип графиков, когда кроме вертикального верхнего уровня столбиков задаются еще и нижние уровни.
- • Есть отдельные типы графиков для рисования гистограмм.
- • График, когда область под графиком закрашивается или заштриховывается.
- • Диаграмма в виде долек пирога – Pie Chart.
- • График, изобращающий набор векторов. Причем можно задавать координаты начала и конца вектора, а можно задавать координаты начала, его длину и угол поворота.
- • Так называемый Box Plot, используемый для отображения статистических данных.
- • Линии уровней.
- • Можно рисовать различные трехмерные графики.
- Трехмерные траектории
- Трехмерные Scatter’ы
- Графики в виде трехмерной ленты
- Трехмерные столбцы, положение на плоскости которых задается двумя координатами, а третья координата определяет их высоту.
- Трехмерные поверхности. Правда, у SciDAVis такой тип графиков получается угловатый. Трехмерные графики в SciDAVis’е можно вращать, приближать и удалять мышкой.
Как создать график в SciDAVis
-
Построим, например, график, используя функцию IF. Откроем меню Файл и выберем команду Новый/Новый график функции (Рис. №1)
В откывшемся диалоговом окне, зададим функцию и диапазон изменения аргумента х.
Результат:
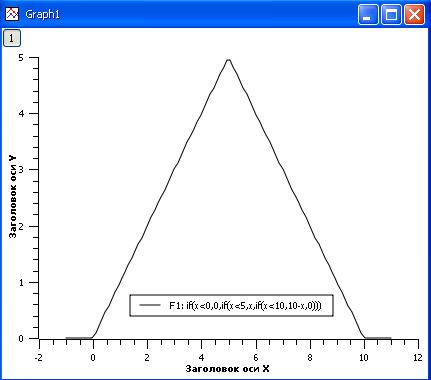
-
Создадим таблицу и на основе значений её ячеек построим график. Заполним первый столбец рядом чисел от 1 до 30 по возрастанию с шагом 1:
- a) Выделим 1-ый столбец
- b) Заполним выделенное с помощью Таблица/Fill Selection with/Row Numbers.
Ко второму столбцу таблицы, предварительно выделив его, применим формулу sin(col("1"))/col("1"), используя для задания формулы списки диалогового окна (см. Рис. №5)
Выбрав График/Линия вы построите график по табличным данным. К построенному графику добавим еще график с заданием функции (см. Рис. №2):
- a) Выделим 1-ый столбец
-
Построим график функции импортируя текстовый файл.
- Для построения графика по насчитанным данным, записанным в файл, выполним Файл/Импорт ASCII... и не забудем правильно задать десятичные разделители (Рис. №8). В результате данные заполнят столбцы (Рис. № 9).
- Ну а теперь знакомыми приёмами построим график, т.е.выделим 2-й столбик и График/Линия(Рис.№10). Далее вы можете делать с ним что угодно, например, сглаживать или сразу из точек вместо линии построитьсплайн (Рис. №11) т.д.
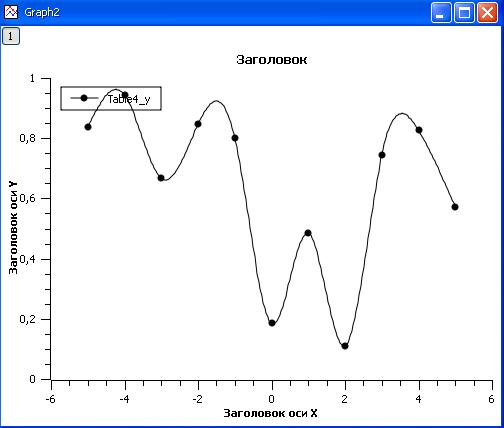
- Для построения графика по насчитанным данным, записанным в файл, выполним Файл/Импорт ASCII... и не забудем правильно задать десятичные разделители (Рис. №8). В результате данные заполнят столбцы (Рис. № 9).
- Построим поверхность. Выполним Файл/Новый/Новый график 3D поверхности , в открывшемся диалоговом окне определим поверхность (Рис. №12)
Трехмерные графики в SciDAVis’е можно вращать, приближать и удалять мышкой.
Перечень пунктов меню SciDAVis
Проиллюстрируем пункты меню. Состав пункта Файл мы уже приводили, приведём и другие пункты для знакомства с интерфейсом приложения:
|
|||
 |
|||
 |
|||
 |
|||
|
{kind=link}
Официальная страница SciDAVis находится – здесь.
Интерактивная среда построения графиков GNUPLOT
gnuplot — свободная программа для создания двух- и трёхмерных графиков. gnuplot - терминальное интерактивное приложение в среде ОС UNIX. Позволяет выполнять построение 2-х и 3-х мерных графиков функций. Функции могут задаваться как в аналитическом виде, так и в виде табличных данных, хранящихся в файлах. Набор команд для построения некоторого графика (или группы графиков) может быть записан в файл и выполнен одной командой. Для работы с gnuplot необходима установка на клиентской машине графической среды X-Window (В MS Windows можно установить NX Client или MobaXterm).
-
Вызовите
gnuplot:
После исполнения команды вы увидите, что установлен терминал 'X11':

- Следом за вызовом
gnuplotможно задавать команды и просматривать результаты их выполнения, например, команда:plot f(x)=sin(x*a),a=0.2,f(x),a=0.4,f(x)нарисует график:
-
, а команда
splot x*x+y*yсоздаст эллиптический параболоид :
- Можно использовать команды заливки, рисования сетки по всем осям,например, для
sin(sqrt(x*x+y*y))/sqrt(x*x+y*y
В современных версиях gnuplot, при использовании интерактивных терминалов (x11,wxt) точку зрения можно менять поворачивая изображение при нажатой кнопке мыши.
Работа в gnuplot осуществляется в двух режимах:
- Интерактивный. Пользователь общается с программой с помощью командной строки в режиме реального времени (см. рисунки №3, №4 и №5).
- Пакетный. Пользователь подготавливает файл, содержащий последовательный набор команд (новая команда начинается с новой строки). При работе в таком режиме командный файл должен находиться в одной директории с исполняемым файлом gnuplot. После установки gnuplot обработка команд содержащихся в файле, например, simpe1.graph, выполняется командой
$ gnuplot simpe1.graph- Пример содержимого файла simple1.graph:
set terminal windows
set parametric
set encoding koi8r
set size square
set xrange [-1:1]
set yrange [-1:1]
f(x)=sin(x) g(x)=cos(x)
plot f(t), g(t) with points ls 3
- Пример визуализации данных файла:
Содержимое командного файла:
set terminal windows
set encoding koi8r
set yrange [0:1]
set xrange [0:1]
plot "RMSresult" with lines and points
Содержимое файла данных
(RMSresult ):
0.1 0.61881100
0.2 0.55289577
0.3 0.71881100
0.4 0.55289577
0.5 0.61881100
0.6 0.55289577
0.7 0.61881100
0.8 0.55289577
0.9 0.61881100
1.0 0.55289577
-
Пример построения графика с помощью пакетного режима. gnuplot выполняет команды из файла и сохраняет график в файле, который можно просмотреть графическим редактором:
Содержимое командного файла:
set term postscript eps
set palette gray
set view 45,45
set isosamples 50
set output "primer1.eps"
splot (cos(5*acos(y/sqrt(x*x+y*y)))/(1+(x*x+y*y))**0.25) w pm3d
C сайта http://yurae.boom.ru/softest/GnuPlot.htm:
" GnuPlot может рисовать графики функций, заданных формулой или точками. Это могут быть функции одной (линия на плоскости) или двух (поверхность в пространстве) переменных. Можно строить графики функций, заданных параметрически, рисовать кривые в полярных координатах. Дополнительно можно наносить на рисунок надписи и стрелки. Поддерживаются различные стили линий и точек, шрифты. Возможен вывод на экран или в файлы различного типа. Кроме того, программа позволяет аппроксимировать экспериментальный набор точек кривыми заданного вида. Работать программа может как под управлением Windows, так и под управлением Unix-подобных ОС. При всем этом, программа абсолютно бесплатна".
Описание языка можно посмотреть на сайте http://jarosh.by.ru/gnuplot/gnuplot_rus.html
- Пример содержимого файла simple1.graph:
Инструменты программиста
Опции компиляторов
Компилятор G77
Компилятор G77 (GNU Fortran )основан на стандарте ANSI Fortran 77, но он включает в себя многие особенности, определенные в стандартах Fotran 90 и Fortran 95.
Синтаксис команды:
g77 [-c?-S?-E]
[-g] [-pg] [-Olevel]
[-Wwarn...] [-pedantic]
[-Idir...] [-Ldir...]
[-Dmacro[=defn]...] [-Umacro]
[-foption...] [-mmachine-option...]
[-o outfile] infile...
Все опции поддерживаемые gcc поддерживаются и g77. Компиляторы С и g77 интегрированы.
Обращение:
g77 [option | filename]...Исходные файлы:
source.f, source.for, source.FOR Значение некоторых опций:
| -c | создать только объектный файл (source.o) из исходного ( source.f, .source.for, source.FOR ) |
| -o file | создать загрузочный файл с именем file (по умолчанию создается файл с именем a.out) |
| -llibrary | использовать библиотеку liblibrary.a при редактировании связей |
| -Idir | добавить каталог dir в список поиска каталогов, содержащих include- файлы |
| -Ldir | добавить директорию dir в список поиска библиотек |
| -O | включить оптимизацию |
| -g | создать отладочную информацию для работы с отладчиком |
Для получения полного описания g77 следует смотреть документацию по GNU Fortran. Об опциях g77 можно также получить информацию с помощью команд:
info g77man g77
Компилятор GCC
GСС - это свободно доступный оптимизирующий компилятор для языков C, C++.
Программа gcc, запускаемая из командной строки, представяляет собой надстройку над группой компиляторов. В зависимости от расширений имен файлов, передаваемых в качестве параметров, и дополнительных опций, gcc запускает необходимые препроцессоры, компиляторы, линкеры.
Файлы с расширением .cc или .C рассматриваются, как файлы на языке C++, файлы с расширением .c как программы на языке C, а файлы c расширением .o считаются объектными.
Чтобы откомпилировать исходный код C++, находящийся в файле F.cc, и создать объектный файл F.o, необходимо выполнить команду:
gcc -c F.cc
Опция –c означает «только компиляция».
Чтобы скомпоновать один или несколько объектных файлов, полученных из исходного кода - F1.o, F2.o, ... - в единый исполняемый файл F, необходимо ввести команду:
gcc -o F F1.o F2.o
Опция -o задает имя исполняемого файла.
Можно совместить два этапа обработки - компиляцию и компоновку - в один общий этап с помощью команды:
gcc -o F <compile-and-link-options> F1.cc ... -lg++ <other-libraries><compile-and-link –options> - возможные дополнительные опции компиляции и компоновки. Опция –lg++ указывает на необходимость подключить стандартную библиотеку языка С++, <other-libraries> - возможные дополнительные библиотеки.
После компоновки будет создан исполняемый файл F, который можно запустить с помощью команды
./F <arguments> <arguments> - список аргументов командной строки Вашей программы.
В процессе компоновки очень часто приходится использовать библиотеки. Библиотекой называют набор объектных файлов, сгруппированных в единый файл и проиндексированных. Когда команда компоновки обнаруживает некоторую библиотеку в списке объектных файлов для компоновки, она проверяет, содержат ли уже скомпонованные объектные файлы вызовы для функций, определенных в одном из файлов библиотек. Если такие функции найдены, соответствующие вызовы связываются с кодом объектного файла из библиотеки. Библиотеки могут быть подключены с помощью опции вида -lname. В этом случае в стандартных каталогах, таких как /lib , /usr/lib, /usr/local/lib будет проведен поиск библиотеки в файле с именем libname.a. Библиотеки должны быть перечислены после исходных или объектных файлов, содержащих вызовы к соответствующим функциям.
Опции компиляции
Среди множества опций компиляции и компоновки наиболее часто употребляются следующие:
| Опция | Назначение |
| -c | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы в виде name.o. Компоновка не производится. |
| -Dname=value | Определить имя name в компилируемой программе, как значение value. Эффект такой же, как наличие строки #define name value в начале программы. Часть =value может быть опущена, в этом случае значение по умолчанию равно 1. |
| -o file-name | Использовать file-name в качестве имени для создаваемого файла. |
| -lname | Использовать при компоновке библиотеку libname.so |
| -Llib-path -Iinclude-path |
Добавить к стандартным каталогам поиска библиотек и заголовочных файлов пути lib-path и include-path соответственно. |
| -g | Поместить в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки. В сочетании –g рекомендуется использовать опцию отключения оптимизации –O0 (см.ниже) |
| -MM | Вывести зависимости от заголовочных файлов , используемых в Си или С++ программе, в формате, подходящем для утилиты make. Объектные или исполняемые файлы не создаются. |
| -pg | Поместить в объектный или исполняемый файл инструкции профилирования для генерации информации, используемой утилитой gprof. Опция должна быть указана и для компиляции, и для компоновки. Собранная с опцией -pg программа при запуске генерирует файл статистики. Программа gprof на основе этого файла создает расшифровку, указывающую время, потраченное на выполнение каждой функции. |
| -Wall | Вывод сообщений о всех предупреждениях или ошибках, возникающих во время компиляции программы. |
| -O1 -O2 -O3 |
Различные уровни оптимизации. |
| -O0 | Не оптимизировать. Если вы используете многочисленные -O опции с номерами или без номеров уровня, действительной является последняя такая опция. |
| -I | Используется для добавления ваших собственных каталогов для поиска заголовочных файлов в процессе сборки |
| -L | Передается компоновщику. Используется для добавления ваших собственных каталогов для поиска библиотек в процессе сборки. |
| -l | Передается компоновщику. Используется для добавления ваших собственных библиотек для поиска в процессе сборки. |
Компилятор GFortran
GFortran - это название компилятора языка программирования Фортран, входящего в коллекцию компиляторов GNU.
Сборка FORTRAN-программы:
Синтаксис
gfortran [-c?-S?-E]
[-g] [-pg] [-Olevel]
[-Wwarn...] [-pedantic]
[-Idir...] [-Ldir...]
[-Dmacro[=defn]...] [-Umacro]
[-foption...]
[-mmachine-option...]
[-o outfile] infile...GFortran опирается на GCC, и, следовательно, разделяет большинство его характеристик. В частности, параметры для оптимизации и генерации отладочной информации у них совпадают.
GFortran используется для компиляции исходного файла, source.f90, в объектный файл, object.o или исполняемый файл, executable. Одновременно он генерирует модуль файлов описания встречающихся модулей, так называемый nameofmodule.mod.
Для компиляции исходного файла source.f90, можно запустить: gfortran source.f90
Выходной файл будет автоматически имени source.o. Это объектный файл, который не может быть исполнен. После того как вы собрали некоторые исходные файлы, вы можете соединить их вместе с необходимыми библиотеками для создания исполняемого файла. Это делается следующим образом: gfortran -o executable object1.o object2.o..., где исполняемым будет executable, objectX.o - объектные файлы, которые могут быть созданы, как указано выше, или в равной степени другими компиляторами из источников в другом языке. Если опущено имя исполняемого файла, то исполняемый файл будет с названием a.out. Исполняемый файл может быть выполнен, как и в любой другой программе. Можно также пропустить отдельный этап компиляции и ввести такую команду: gfortran o executable source1.f90 source2.f90, которая будет осуществлять сбор исходных файлов source1.f90 и source2.f90, связь и создаст исполняемый файл. Вы также можете поместить объектные файлы в этой командной строке, они будут автоматически присоединены.
Опции компилятора GFortran
| Опция | Назначение |
| -c | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы в виде name.o. Компоновка не производится. |
| -Dname=value | Определить имя name в компилируемой программе, как значение value. Эффект такой же, как наличие строки #define name value в начале программы. Часть =value может быть опущена, в этом случае значение по умолчанию равно 1. |
| -o file-name | Использовать file-name в качестве имени для создаваемого файла. |
| -lname | Использовать при компоновке библиотеку libname.so |
| -Llib-path -Iinclude-path |
Добавить к стандартным каталогам поиска библиотек и заголовочных файлов пути lib-path и include-path соответственно. |
| -g | Поместить в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки. В сочетании –g рекомендуется использовать опцию отключения оптимизации –O0 (см.ниже) |
| -MM | Вывести зависимости от заголовочных файлов , используемых в Си или С++ программе, в формате, подходящем для утилиты make. Объектные или исполняемые файлы не создаются. |
| -pg | Поместить в объектный или исполняемый файл инструкции профилирования для генерации информации, используемой утилитой gprof. Опция должна быть указана и для компиляции, и для компоновки. Собранная с опцией -pg программа при запуске генерирует файл статистики. Программа gprof на основе этого файла создает расшифровку, указывающую время, потраченное на выполнение каждой функции. |
| -Wall | Вывод сообщений о всех предупреждениях или ошибках, возникающих во время компиляции программы. |
| -O1 -O2 -O3 |
Различные уровни оптимизации. |
| -O0 | Не оптимизировать. Если вы используете многочисленные -O опции с номерами или без номеров уровня, действительной является последняя такая опция. |
| -I | Использует для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки |
| -L | Передает компоновщику. Использует для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Использует для добавления ваших собственных библиотек поиска в процессе сборки. |
Компилятор PGCC
Компилятор Portland Group C (PGCC).
Компилятор PGCC для процессоров AMD64 и IA32/EM64T производит компиляцию программ C и линкует согласно опциям в командной строке.
Синтаксис команды:
pgcc [ -параметры ]... sourcefile...
- Параметры могут отсутствовать или содержать опции копилятора
- Суффиксы
sourcefileуказывают на вид файла:
.c - файл на C; обрабатывается препроцессором перед компиляцией; компилируется
.i - файл на C после обработки препроцессора; компилируется
.s - ассемблерный файл; передаётся ассемблеру
.S - ассемблерный файл; обрабатывается препроцессором; передаётся ассемблеру
.o -объектный файл; передаётся компоновщику
.a - библиотечный файл; передаётся компоновщику
Полный список опций компилятора можно посмотреть по команде man pgcc.
Некоторые важные опции компиляции для PGCC приведены ниже:
| Опция | Назначение |
| -с | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы. |
| -C | Включает проверки выхода индекса за границы массива |
| -O0 | Отключает оптимизацию. |
| -О1 | Оптимизация по размеру. Не использует методов оптимизации, которые могут увеличить размер кода. Создает в большинстве случаев самый маленький размер кода. |
| -O2 или -O | Оптимизация устанавливаемая по умолчанию. |
| -O3 | Задействует методы оптимизации из -O2 и, дополнительно, более агрессивные методы оптимизации, которые подходят не для всех программ. |
| -Os | Включает оптимизацию по скорости, но при этом отключает некоторые оптимизации, которые могут привести к увеличению размеров кода при незначительном выигрыше в скорости. |
| -fast | Включает в себя -O2 и ряд других опций, таких как использование векторизации с поддержкой SSE инструкций. Использование -fast понижает точность вычислений. |
| -g | Включает информацию об отладке. |
| -fastsse | То же самое что и -fast -Mipa=fast - включает межпроцедурный анализ. |
| -I | Использует для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки. |
| -L | Передает компоновщику. Использует для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Использует для добавления ваших собственных библиотек поиска в процессе сборки. |
Компилятор PGFortran
Компилятор The Portland Group Inc. Fortran (PGFortran).
Компилятор PGFortran для процессоров AMD64 и IA32/EM64T производит компиляцию программ на Фортране и линкует согласно опциям в командной строке. PGFortran является интерфейсом для компиляторов pgf90 и pgf95.
Синтаксис команды:
pgfortran [ -параметры ]... sourcefile...- Параметры могут отсутствовать или содержать опции копилятора
- Суффиксы
sourcefileуказывают на вид файла:
.f - файл на Фортране с фиксированным форматом; компилируется
.F - файл на Фортране с фиксированным форматом; после обработки препроцессором - компилируется
.f90 - файл на Фортране в свободном формате; компилируется
.F90 - файл на Фортране в свободном формате; после обработки препроцессором - компилируется
.f95 - файл на Фортране в свободном формате; компилируется
.F95 - файл на Фортране в свободном формате; после обработки препроцессором - компилируется
.for - файл на Фортране с фиксированным форматом; компилируется
.FOR - файл на Фортране с фиксированным форматом; после обработки препроцессором - компилируется
.fpp - файл на Фортране с фиксированным форматом; после обработки препроцессором - компилируется
.s - ассемблерный файл; передаётся ассемблеру
.S - ассемблерный файл; обрабатывается препроцессором; передаётся ассемблеру
.o - объектный файл; передаётся компоновщику
.a - библиотечный файл; передаётся компоновщику
Полный список опций компилятора можно посмотреть по команде man pgfortran.
Некоторые важные опции компиляции для PGFortran приведены здесь.
Опции компилятора PGFortran
| Опция | Назначение |
| -o file |
Использует file как имя выходного исполняемого файла программы, вместо имени по умолчанию - a.out. Если используется совместно с опцией -с или -S и с одним входным файлом, то file используется в качестве имени объектного или ассемблерного выходного файла. |
| -S |
Пропускает этапы ассемблирования и линкования. Для каждого файла с именем, например, file.f создает при выходе из компиляции файл с именем file.s . См. также -о. |
| -fastsse |
Выбирает основные оптимальные установки для процессора, который поддерживает SSE инструкции (Pentium 3 / 4, AthlonXP / MP, Opteron) и SSE2 (Pentium 4, Opteron). Используйте в pgf90 -fastsse -help чтобы просмотреть установки. |
| -C | Включает проверки выхода индекса за границы массива также как и -Mbounds |
| -i2 | Целые и логические переменные длиной 2 байта . |
| -i4 | Целые и логические переменные длиной 4 байта . |
| -i8 | Целые и логические переменные длиной 8 байт . Устанавливается по умолчанию. Для операций над целыми числами отводится 64 бита. |
| -O[N] | Устанавливает уровень оптимизации равным N. -O0 до -O4, по умолчанию устанавливается -O2. Если не указана опция -O и если не заказана -g, то устанавливается -O1 , но если заказана -g, то устанавливается -O0. Когда номер у -O не указан, то устанавливается -O2. |
| -O0 | Без оптимизации. |
| -О1 |
Оптимизация в рамках основных блоков. Выполняется некоторое распределение регистров. Глобальная оптимизация не выполняется. |
| -O2 | Выполняется оптимизация -O1. Кроме того, выполняются традиционные скалярные оптимизации, такие как признание индукции и инвариант цикла движения глобального оптимизатора. |
| -O3 |
Задействует методы оптимизации из -O1 и -O2 и, дополнительно, более агрессивные методы оптимизации циклов и доступа к памяти, такие как подстановка скаляров, раскрутка циклов. Эти агрессивные методы оптимизации могут, в ряде случаев, и замедлить работу приложений . |
| -O4 | Выполняет все уровни оптимизации -O1,-O2, -O3, кроме того, выполняет оптимизацию выражений с плавающей точкой. |
| -fpic |
Передаёт компилятору для генерации позиционно-независимого кода, который может быть использован при создании общих объектных файлов (динамически связываемых библиотек). |
| -gopt |
Сообщает компоновщику включение отладочной информации без отключения оптимизации |
| -s |
Использует линковщик; таблицы символьной информации, оптимизации. Использование может привести к неожиданным результатам при отладке с оптимизацией, она предназначена для использования с другими опциями , которые используют отладочную информацию. |
| -pg | Устанавливает профилирование; влечёт установку -Mframe |
| -r4 | Переменные DOUBLE PRECISION рассматриваются как REAL. |
| -r8 | Переменные REAL рассматриваются как DOUBLE PRECISION . Это тоже самое, что и указать -Mr8 и -Mr8intrinsics. |
| -fast | Обеспечивает ускоренный метод нескольких оптимизаций на время выполнения программы. Устанавливает параметры для повышения производительности в размере не менее 2, см.-O. Используйте pgf90 -fast -help для просмотра эквивалентных переключателей. |
| -g | Создаёт отладочную информацию. Опция устанавливает уровень оптимизации до нуля, если только заказана опция -O . Процесс может привести к неожиданным результатам, если заказан уровень оптимизации отличный от нуля. Сгенерированный код будет работать медленнее при -O0, чем при других уровнях оптимизации. |
| -I | Добавляет ваши собственные каталоги поиска заголовочных файлов в процессе сборки |
| -L | Передает компоновщику. Добавляет ваши собственные каталоги поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Добавляет ваши собственные библиотеки поиска в процессе сборки. |
Опции компилятора ICC
icc -команда для вызова компилятора Intel(R) (C или C++).
Синтаксис команды:
icc [параметры] file1 [file2] ...
- параметры могут отсутствовать или содержать опции компилятора
fileN– это файлы на языке C или C++, сборочные файлы, объектные файлы, библиотеки объектов или другие линкуемые файлы
Полный список опций можно посмотреть по команде man icc .
Некоторые важные опции компиляции для ICC приведены ниже:
| Опция | Назначение |
| -с | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы. |
| -C | Включает проверки выхода индекса за границы массива. |
| -O0 | Отключает оптимизацию. |
| -О1 | Оптимизация по размеру. Не использует методов оптимизации, которые могут увеличить размер кода. Создает в большинстве случаев самый маленький размер кода. |
| -O2 или -O | Оптимизация устанавливаемая по умолчанию. |
| -O3 | Задействует методы оптимизации из -O2 и, дополнительно, более агрессивные методы оптимизации, которые подходят не для всех программ. |
| -Os | Включает оптимизацию по скорости, но при этом отключает некоторые оптимизации, которые могут привести к увеличению размеров кода при незначительном выигрыше в скорости. |
| -fast | Обеспечивает ускоренный метод для нескольких оптимизаций на время выполнения программы. Устанавливает -xT -O3 -ipo -no-prec-div -static параметры для повышения производительности: • -O3 (см. выше) • -ipo (включает межпроцедурную оптимизацию между файлами) • -static (предотвращает линкование с общими библиотеками). Параметры задаются списком и не могут быть заданы по отдельности. |
| -g | Включает информацию об отладке. |
| -I | Используется для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки. |
| -L | Передается компоновщику. Используется для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передается компоновщику. Используется для добавления ваших собственных библиотек в процессе сборки. |
Опции компилятора Intel Fortran
ifort -команда для вызова компилятора Intel(R) Fortran.
Синтаксис команды:
ifort [параметры] file1 [file2] ...- параметры могут отсутствовать или содержать опции компилятора
fileN– это файлы на языке Fortran, сборочные файлы, объектные файлы, библиотеки объектов или другие линкуемые файлы
Полный список опций можно посмотреть по команде man ifort .
Команда ifort интерпретирует входные файлы по суффиксу имени файла следующим образом:
Имена файлов с суффиксом .f90 интерпретируются как файлы в свободной форме записи на Fortran 95/90.
Имена файлов с суффиксом .f, .for или .ftn интерпретируются как фиксированная форма записи для Fortran 66/77 файлов.
В Fortran 90/95, наряду с фиксированным форматом исходного текста программы, разрешен свободный формат. Свободный формат допускает помещение более одного оператора в строке, при этом в качестве разделителя используется точка с запятой. Признак продолжения оператора на строку продолжения - символ & - указывается в конце той строки, которую надо продолжить. Комментарии записываются после символа восклицательный знак в начале строки или в любой позиции строки после оператора. В свободном формате пробелы являются значащими.
Некоторые важные опции компиляции для Intel Fortran приведены ниже:
| Опция | Назначение |
| -free | Указывает, что исходные файлы находятся в свободном формате. По умолчанию, формат исходного файла определяется суффиксом файла |
| -fixed | Указывает, что исходные файлы находятся в фиксированном формате. По умолчанию, формат исходного файла определяется суффиксом файла |
| -с | Эта опция означает, что необходима только компиляция. Из исходных файлов программы создаются объектные файлы |
| -C | Включает проверки выхода индекса за границы массива |
| -i2 | Целые и логические переменные длиной 2 байта (тоже, что и опция -integer-size 16). По умолчанию целочисленный размер равен 32 разряда. |
| -i4 | Целые и логические переменные длиной 4 байта (тоже, что и опция -integer-size 32 ). Это значение устанавливается по умолчанию. |
| -i8 | Целые и логические переменные 8 байт (тоже , что и опция -integer-size 64). По умолчанию целочисленный размер равен 32 разряда. |
| -O0 | Отключает оптимизацию |
| -О1 | Оптимизация по размеру. Не использует методов оптимизации, которые могут увеличить размер кода. Создает в большинстве случаев самый маленький размер кода. |
| -O2 или -O | Максимизация скорости. Как правило, создает более быстрый код, чем -O1. Эта опция устанавливается по умолчанию для оптимизации, если не указана -g |
| -O3 | Задействует методы оптимизации из -O2 и, дополнительно, более агрессивные методы оптимизации циклов и доступа к памяти, такие как подстановка скаляров, раскрутка циклов, подстановка кода для избегания ветвлений, блокирование циклов для обеспечения более эффективного использования кэш-памяти и, только на системах архитектуры IA-64, дополнительная подготовка данных. Данная опция особенно рекомендуется для приложений, где есть циклы, которые активно используют вычисления с плавающей точкой или обрабатывают большие порции данных. Эти агрессивные методы оптимизации могут в ряде случаев, и замедлить работу приложений других типов по сравнению с использованием -O2. |
| -OpenMP | Включает поддержку стандарта OpenMP 2.0 Распараллеливает программу. Позволяет параллелизацию для создания многопоточного кода на основе команд OpenMP. Этот опция может быть выполнена в параллельном режиме на однопроцессорных и многопроцессорных системах. OpenMP-опция работает как с-O0 (без оптимизации) и c любым уровнем оптимизации -O. Указание с-O0 помогает для отладки OpenMP приложений. |
| -OpenMP-stubs | Включает выполнение программ OpenMP в последовательном режиме. Директивы OpenMP игнорируются, если стоят заглушки (stubs) для OpenMP |
| -p | Порождает дополнительный код для записи профилирующей информации, подходящей для анализирующей программы PROF. Вы должны использовать эту опцию при компиляции исходного файла, о котором вы хотите получить информацию, и вы также должны использовать ее при линковке. |
| -parallel | Включает автоматическое распараллеливание циклов, для которых это безопасно. Чтобы использовать эту опцию, вы также должны указать-O2 и-O3. |
| -r8 | Вещественные и комплексные переменные длиной 8 байт. Переменные REAL рассматриваются как DOUBLE PRECISION (REAL(KIND=8)) и комплексные рассматриваются в качестве DOUBLE COMPLEX (COMPLEX(KIND=8)). Это тоже самое, что и указать -real-size 64 или -autodouble. |
| -r16 | Вещественные и комплексные переменные длиной 16 байт. Переменные REAL рассматриваются как REAL (REAL(KIND=16), COMPLEX и DOUBLE COMPLEX рассматривается как COMPLEX (COMPLEX(KIND=16)). Это тоже самое, что и указать -real-size 128. |
| -save | Сохраняет переменные, за исключением тех, которые объявлены, как AUTOMATIC, в статической памяти (тоже, что и noauto-noautomatic). По умолчанию используется –autoscalar, однако, если Вы укажите -recursive или -OpenMP, то по умолчанию используется AUTOMATIC |
| -stand | Заставляет компилятор выдавать сообщения компиляции для нестандартных элементов языка. |
| -fast | Обеспечивает ускоренный метод для нескольких оптимизаций на время выполнения программы. Устанавливает следующие параметры для повышения производительности: • -O3 • -ipo (включает межпроцедурную оптимизацию между файлами) • -static (предотвращает линкование с общими библиотеками). |
| -g | Помещает в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки. В сочетании –g рекомендуется использовать опцию отключения оптимизации –O0 |
| -check bounds | Выполняет динамическую проверку выхода индекса за границы массива. Проверка может увеличить время выполнения программы. |
| -I | Использует для добавления ваших собственных каталогов поиска заголовочных файлов в процессе сборки |
| -L | Передает компоновщику. Использует для добавления ваших собственных каталогов поиска библиотек в процессе сборки. |
| -l | Передает компоновщику. Использует для добавления ваших собственных библиотек поиска в процессе сборки. |
Использование CUDA
Запуск задач на графических процессорах в системе SLURM задается опцией --gres=gpu:N, где N - число GPU.
Свежая версия библиотеки CUDA находится в каталоге /opt/cuda/.
/opt/cuda/include/ — заголовочные файлы;
/opt/cuda/lib /— библиотека CUDA;
/opt/cuda/doc/ — документация.
Чтобы использовать библиотеку CUDA, необходимо при компиляции программы заказать данную библиотеку, например:
gcc mytest.c -o mytest -lcuda -L/opt/cuda/lib -I/opt/cuda/includeМожно использовать компилятор nvcc:
nvcc <имя файла для компиляции> -o <имя выходного файла> На кластере "Уран" при выполнении данной команды по умолчанию подключается библиотека CUDA . Можно компилировать программы на языках C и C++ (файлы с расширением .c и .cpp) и программы, написанные с использованием технологии CUDA (файлы с расширением .cu), например:
u9999@umt:~$ nvcc main.c -o gputest
Пример
Пусть файл cuda_test.cu (из домашнего каталога) содержит программу на CUDA:
#include <cuda.h>
#include <stdio.h>
int main() {
int GPU_N;
int dev;
cudaGetDeviceCount(&GPU_N);
printf("Device count: %d\n", GPU_N);
for(dev=0;dev<GPU_N;dev++) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("PCI Bus id: %d\n",deviceProp.pciBusID);
}
return 0;
}Тогда компиляция программы и запуск задачи на кластере могут иметь вид:
u9999@umt:~$ nvcc cuda_test.cu -o cuda_test
u9999@umt:~$ srun --gres=gpu:1 ./cuda_test
Device count: 1
PCI Bus id: 8
u9999@umt:~$ srun --gres=gpu:2 ./cuda_test
Device count: 2
PCI Bus id: 10
PCI Bus id: 26
Поддержка CUDA есть в компиляторе Portland Group.
Инструкции по использованию CUDA в Фортране можно найти на сайте Portland Group (http://www.pgroup.com/resources/cudafortran.htm).
Для компиляции Fortran-программы с CUDA следует установить переменные окружения командой module или mpiset, выбрав связку MVAPICH+PGI, например:
module switch mpi/default mvapich2/pgi_12.10или соответственно
mpiset 7и откомпилировать программу компилятором pgfortran с опцией -Mcuda, указав при необходимости оптимизированные библиотеки, например:
pgfortran -o mytest test.cuf -Mcuda -lcublasСсылки на руководства по CUDA
Сообщество пользователей CUDA ВМК МГУ (выложены лекции в виде слайдов и есть активный форум, на котором можно задавать вопросы по CUDA. В работе форума активно участвуют сотрудники Nvidia)
https://sites.google.com/site/cudacsmsusu/home
CUDA zone: сборник приложений на CUDA, многие с документацией и исходными кодами
http://www.nvidia.ru/object/cuda_apps_flash_new_ru.html#state=home
Записи семинаров по CUDA:
a) введение в CUDA
http://www.gotdotnet.ru/blogs/parallel-computing/9966/
b) библиотеки с поддержкой CUDA
http://www.gotdotnet.ru/blogs/parallel-computing/10070/
c) отладка и профилировка CUDA приложений
http://www.gotdotnet.ru/blogs/parallel-computing/10362/
Чтобы быстро задействовать GPU (хотя и с меньшей эффективностью) можно использовать директивные средства распараллеливания, а именно PGI Accelerator, доступ к триальной версии которого можно получить на месяц бесплатно
http://www.nvidia.ru/object/openacc-gpu-directives-ru.html
вот ссылки на записи презентаций по применению данного ПО для C и Fortran кодов
http://youtu.be/5tDhWkSc4BI
http://youtu.be/MjGEcZ7LHAQ
25 июня по 7 июля 2012 в Москве в МГУ будет проходить Международная Летняя Суперкомпьютерная Академия, на которой будут курсы по CUDA.
http://academy.hpc-russia.ru/
PGI Accelerator и OpenACC
Компиляторы PGI (pgcc/pgCC/pgf77/pgfortran) позволяют создавать приложения для запуска на GPU (см. [1-3]). Поддержка стандарта OpenACC [4] добавлена в 2012 году с версии 12.6 (см. [5]; в частности, о переходе на OpenACC в [6]). Приложения могут быть запущены на узлах с графическими ускорителями кластера "Уран" (umt).
Настроиться на компиляторы PGI можно с помощью команды mpiset
(на текущую рабочую версию)
mpiset 7
или, загрузив модуль с нужной версией, с помощью команды module. Например, в начале сеанса
module switch mpi/default mvapich2/pgi_12.10
Для компиляции тогда можно использовать, например, команду pgcc или mpicc
mpicc -o exam_pgi exam.c -ta=nvidia -Minfo=accel -fast
где опция -ta=nvidia подключает компиляцию на GPU,
а необязательная опция -Minfo=accel служит для выдачи дополнительной информации о генерации кода для GPU (accelerator kernel).
Для версий компилятора с поддержкой OpenACC можно вместо опции -ta=nvidia использовать опцию -acc.
Опция -ta=nvidia,time (где time - подопция) используется для выдачи времени, потраченного на инициализацию GPU (init), перемещение данных (data) и вычисления на GPU (kernels).
Использование же -ta=nvidia,host задаст генерацию единого кода для host (CPU) и GPU: при наличии GPU программа будет выполняться на GPU, иначе на host.
Например,
mpicc -o exam_gh exam.c -ta=nvidia,host -Minfo
Можно узнать, выполняется ли программа на GPU, если установить переменную окружения ACC_NOTIFY в 1
export ACC_NOTIFY=1
и запустить программу. При каждом вызове функции GPU (kernel) будет выдаваться сообщение вида
launch kernel file=...
что полезно при разработке и отладке программы.
Примеры C и Fortran программ есть на umt, например в каталоге
/opt/pgi/linux86-64/11.1/EXAMPLES/accelerator
и рассматриваются в [2].
Замечания.
- Помните, что в С, по умолчанию, все константы с плавающей точкой имеют тип
double. Поэтому в [2, First Program] для вычислений с одинарной точностью используется 2.0f вместо 2.0. - Для безопасного распараллеливания в С программах (см. [2]) объявления указателей, ссылающихся на распределенную с помощью malloc() память, содержат квалификатор
restrict. Такие указатели ссылаются на непересекающиеся области памяти.
Запуск приложения на счет с использованием GPU можно осуществить с помощью команды
srun --gres=gpu:1 exam_pgi
Опция -C k40m (или -C m2090) позволяет указать желаемый тип GPU (см. Кластер "Уран"), например,
srun --gres=gpu:1 -C k40m exam_pgi
С помощью программы pgaccelinfo [2, Setting Up] можно получить информацию о технических характеристиках GPU конкретного узла, указав опцию -w, например
srun -w tesla52 --gres=gpu:1 pgaccelinfo
Возможно совместное использование OpenMP и GPU.
Общие замечания.
- Использование GPU может дать значительное ускорение для задач, где активно задействованы стандартные математические функции (sin, cos, …, см. [1]). При этом надо иметь в виду, что точность вычислений на GPU не та же самая, что на CPU (в частности, и для тригонометрических функций).
Рекомендуется (см., например, [2, 3]): - До первого запуска kernel осуществлять начальную инициализацию GPU с помощью вызова функции acc_init(acc_device_nvidia).
- Копировать массивы целиком (память host <---> память GPU).
Компилятор стремится минимизировать объём перемещаемых данных, не заботясь о количестве команд пересылки данных. Во многих случаях издержки на инициирование/завершение команд пересылки оказываются больше, чем экономия на времени самой пересылки, и более эффективно посылать один большой непрерывный кусок. - Если посчитанные GPU данные не используются в дальнейшем на host, то следует явно указать компилятору, что соответствующие переменные не надо передавать обратно. Компилятор обычно возвращает на host все модифицированные данные.
- Постараться избавиться от диагностики вида ‘Non-stride-1 accesses for array 'X'’, изменив или структуру массива, или порядок заголовков циклов, или параметры преобразования циклов (loop schedule). Эта диагностика означает, что для соответствующего массива не обеспечен непрерывный доступ к данным и может возникнуть задержка при выполнении групп нитей (threads in groups), которые NVIDIA называет warps. Упрощённо можно думать, что warp выполняется в SIMD или векторном виде с доступом к памяти порциями определённого размера.
- GPU Programming with the PGI Accelerator Programming Model
by Michael Wolfe/ PGI GPU Programming Tutorial. Mar 2011 - The PGI Accelerator Programming Model on NVIDIA GPUs. Part 1
by Michael Wolfe/ June 2009 - The PGI Accelerator Programming Model on NVIDIA GPUs. Part 2 Performance Tuning
by Michael Wolfe/ August 2009 - The OpenACC™ Application Programming Interface. Version 1.0. November, 2011
- PGI Accelerator Compilers with OpenACC Directives
- PGI Accelerator Compilers with OpenACC
by Michael Wolfe/ March 2012, revised in August 2012
Инструменты Intel для профилировки и отладки
На кластере установлено программное обеспечение (ПО) фирмы Intel для профилировки и отладки – Intel Parallel Studio XE. Это ПО позволяет находить наиболее нагруженные места в приложении, подсчитывать степень параллельности программы, находить тупики и гонки в параллельных программах и т.д.
Основные инструменты Advisor XE, Inspector XE и Vtune Amplifier XE находятся в соответствующих папках в каталоге /opt/intel.
Графический интерфейс (GUI) запускается командами
/opt/intel/advisor/bin64/advixe-gui/opt/intel/inspector/bin64/inspxe-gui/opt/intel/vtune_amplifier_xe/bin64/amplxe-gui
По умолчанию отлаживаемая программа будет запускаться на управляющей машине кластера и мешать другим пользователям. Как запустить последовательную/параллельную программу на узлах кластера подробно описано в справке, которая доступна по кнопке (?) в GUI (а в формате html на кластере в папках /opt/intel/*/documentation/), на сайте Intel https://software.intel.com/en-us/documentation, а также в инструкциях:
Использование Intel® VTune™ Amplifier XE
Intel VTune Amplifier – мощный инструмент для сбора и анализа данных о производительности кода (профилировки) последовательных и параллельных приложений (программ). Явное указание на участки кода, выполняющиеся дольше всего, и определенная детализация причин задержек могут помочь в модификации программы и тем самым существенно ускорить её исполнение. Можно профилировать код, написанный на C, C++, C#, FORTRAN, Java и Assembly. VTune Amplifier проектировался (и работает) для программ со взаимодействием через общую память, поэтому код с MPI и/или OpenMP может быть профилирован, если он выполняется на одном узле.
VTune Amplifier позволяет запустить удаленный анализ на вычислительном узле кластера и просмотреть результаты сбора данных на хосте (головном узле). Для сбора данных на кластере используется интерфейс командной строки amplxe-cl (Intel® VTune™ Amplifier Command Line Interface). Для просмотра результатов удобно использовать графический интерфейс (GUI), который вызывается командой amplxe-gui.
- Подготовка к работе с VTune Amplifier
- Сбор данных на вычислительном узле
- Визуализация результатов в графическом интерфейсе на хосте
- Пример
Подготовка к работе с VTune Amplifier
1. Построить приложение как обычно, с той же опцией оптимизации (-O), но с добавлением опции -g (отладочного режима компиляции) для команд icc, gcc, mpicc, ifort и т.д. Это позволяет профилировать на уровне исходного языка. Рекомендуется использовать (попробовать), например, -O3, чтобы сосредоточиться на оптимизации регионов, не учитываемых компилятором.
2. Установить VTune окружение, выполнив команду:
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh
Сбор данных на вычислительном узле
1. Для профилировки на кластере приложение должно запускаться исполняемым файлом amplxe-cl. Рекомендуется начать со сбора горячих точек (collect hotspots), т.е. с нахождения самых трудоемких функций в приложении. В этом случае запуск на кластере профилировки последовательной программы my_app может иметь вид:
srun amplxe-cl -collect hotspots ./my_appПо умолчанию в рабочем каталоге пользователя будет создан подкаталог с именем r000hs (при первом запуске), в который будет записан файл вида r000hs.amplxe с полученной информацией. При этом hs – аббревиатура типа анализа (hotspots), 000 – номер, который будет автоматически увеличиваться при следующих запусках.
Имя каталога может быть задано опцией -r (или -result-dir), например,
srun amplxe-cl -collect hotspots -r my_res ./my_appСбор данных (для чистоты эксперимента) желательно проводить на одном и том же узле или разделе кластера с одинаковыми узлами, используя соответствующие опции -w, -p.
2. Для приложений, использующих MPI, необходимо установить не только опцию -n для запроса количества процессов, но и -N 1, чтобы задача полностью находилась на одном вычислительном узле. VTune не способен собирать данные по нескольким узлам!
Опция -gtool (только в Intel MPI, устанавливается по команде mpiset 8) позволяет запускать анализ лишь на выбранных процессах, последовательных или многопоточных (см., например, Профилировка гибридных кластерных приложений MPI+OpenMP).
3. Поскольку основным на кластере является пакетный режим, то запуск приложения для профилировки лучше осуществлять командой sbatch.
Замечания.
1) Для доступа к полной документации команды amplxe-cl в используемой версии VTune следует набрать
amplxe-cl -help
amplxe-cl -help collect - уточнить информацию для конкретного действия (action) collect
amplxe-cl -help collect hotspots - дополнительно о типе анализа hotspots и т.п.
2) Можно получить образец нужной команды amplxe-cl, используя возможность генерации этой команды в VTune Amplifier GUI. Следует создать проект, выбрать нужный тип анализа и нажать на клавишу Command Line (подробнее command generation feature на сайте Intel).
Не рекомендуется нажимать на клавишу Start, так как это вызовет запуск приложения на хосте, что может замедлить обслуживание задач других пользователей. Запуск на хосте допустим в крайнем случае для очень коротких задач, не более нескольких минут.
3) Документацию по команде amplxe-cl можно посмотреть на сайте Intel в разделе Intel® VTune™ Amplifier Command Line Interface или найти в GUI в разделе Help, обозначенным в меню вопросительным знаком (?).
Визуализация результатов в графическом интерфейсе на хосте
Для просмотра результатов можно запустить GUI командой
amplxe-gui &и в открывшемся окне нажать на кнопку меню ≡ (вверху справа), выбрать пункт Open/Result... и найти файл-результат (например, my_res.amplxe в каталоге my_res).
Из рабочего каталога задачи достаточно запустить GUI командой
amplxe-gui my_res &где my_res - каталог с результатами профилировки.
Замечания.
1) VTune Amplifier GUI можно запустить из MobaXterm или X2Go Client.
2) Предполагается, что запуску GUI предшествовала установка VTune окружения.
3) & – не обязательный символ. Он используется для запуска с освобождением командной строки.
Окно с результатами откроется на вкладке Summary (итоговая страница).
Раздел Top Hotspots укажет на наиболее трудоемкие (затратные по времени) функции/подпрограммы приложения пользователя.
Гистограмма использования CPU (CPU Usage Histogram) показывает загрузку одновременно работающих процессоров (CPUs). Она предназначена для параллельных кодов.
Дополнительную информацию можно увидеть, щелкнув на вкладках Bottom-up или Top-down Tree.
Двойной щелчок на строке с именем функции на вкладке Bottom-up приведет к исходному коду приложения и покажет использование CPU относительно отдельных строк. Это укажет на области, на которых следует сфокусировать усилия по оптимизации приложения.
После модификации кода и запуска приложения можно сравнить результаты, полученные до и после оптимизации.
Для этого удобнее воспользоваться GUI
amplxe-gui &Затем в открывшемся окне нажать на кнопку меню ≡, выбрать пункт New/Compare Results..., указать нужные файлы и нажать кнопку Compare.
Опробовать Intel VTune Amplifier можно на примере приложения ray-tracer с именем tachyon из каталога /opt/intel/vtune_amplifier_xe/samples/en/C++.
Соответствующий файл tachyon_vtune_amp_xe.tgz следует
1) скопировать в свой домашний каталог,
2) распаковать архиватором tar
tar zxf tachyon_vtune_amp_xe.tgz3) получить исполняемый файл tachyon_find_hotspots, выполнив команду
make4) запустить его на кластере из текущего рабочего каталога
srun ./tachyon_find_hotspotsдля получения baseline (показателя производительности), с которым в дальнейшем будет проводиться сравнение.
В данном примере это строка вида
CPU Time: 15.211 seconds.Заметим, что диагностика Can't open X11 display выдается, поскольку задача выполняется на вычислительном узле.
5) далее можно перейти к профилировке программы tachyon_find_hotspots на кластере, как описано выше.
Использование Intel® Advisor XE
Intel® Advisor XE предназначен помочь в достижении максимальной производительности Fortran, C и C ++ приложений, упрощая и улучшая параллелизацию вычислений.
Intel Advisor XE объединяет 2 инструмента оптимизации кода:
1) Vectorization Advisor – инструмент векторизации кода.
Vectorization Advisor позволяет идентифицировать циклы, которые в наибольшей степени выиграют от векторизации; определить, что блокирует (мешает) эффективную векторизацию; исследовать преимущества альтернативной реорганизации данных и повысить уверенность в том, что векторизация безопасна. Vectorization Advisor не только показывает расширенные (по сравнению с компилятором) отчеты по оптимизации, делая это удобным для пользователя способом, но и выдает рекомендации по оптимизации.
2) Threading Advisor – инструмент проектирования многопоточного кода.
Threading Advisor позволяет анализировать, проектировать, настраивать и проверять варианты проектирования потоков без реальной модификации программы.
Intel Advisor XE позволяет запустить удаленный анализ приложения на вычислительном узле кластера, используя интерфейс командной строки (CLI), а именно команду advixe-cl, и просмотреть результаты сбора данных на управляющей машине, используя более удобный по сравнению с CLI графический интерфейс (GUI), который вызывается командой advixe-gui. Из главного окна GUI доступна справочная информация для текущей версии (например, из пункта меню Help (?)).
- Начальные действия
- Сбор данных на вычислительном узле
- Просмотр результатов в GUI на хосте
- О примерах
1. Анализ с помощью Advisor XE предназначен для работающих приложений (программ).
Для проведения анализа, прежде всего, следует построить приложение с опциями -g и -O2 (или выше) и проверить его работоспособность.
Замечание. Опция -g используется для запроса полной отладочной информации.
Опция –O[n] задает уровень оптимизации. Для компиляторов Intel при значении -O2 (или выше) возможна векторизация (включены опции –vec и -simd). При этом опция -O2 установлена по умолчанию.
Запускать приложение с Advisor XE следует в том же окружении, т.е. используя ту же команду mpiset (или соответствующий модуль установки переменных окружения).
Для MPI программ следует устанавливать окружение командой
mpiset 8
2. До использования любой из команд advixe-cl или advixe-gui должно быть установлено Intel Advisor XE окружение командой
source /opt/intel/advisor/advixe-vars.sh
Сбор данных на вычислительном узле
Каждому виду оптимизации в Intel Advisor (vectorization/threading) соответствуют определенные этапы анализа приложения, которые объединены в так называемые рабочие процессы (workflows), а именно: Vectorization workflow и Threading workflow. Шаг за шагом выполняя пункты workflows, анализируя возможности распараллеливания кода и оценивая предполагаемую выгоду, пользователь реализует рекомендованные предложения и продвигается в понимании того, что препятствует дальнейшей оптимизации приложения, можно ли её достичь и как.
Подробная информация об этапах анализа приложения приведена в документации Intel, в частности проиллюстрирована в Get Started with Intel Advisor , а также может быть получена по команде
advixe-cl -help workflow
Анализ приложения на кластере следует начать с профилировки (поиска горячих точек) с помощью команды advixe-cl. Запуск её на кластере может иметь вид
srun advixe-cl -collect survey -project-dir ./surv -search-dir src:r=./src -- ./my_appгде-collect survey означает собрать данные с учетом указанного типа анализа (survey);-project-dir ./surv задает каталог surv для записи данных в текущем каталоге;-search-dir src:r=./src обеспечивает доступ к исходным текстам (рекомендуется);./my_app – исполняемый файл приложения в текущем каталоге.
Запуск анализа MPI приложения на 4-х ядрах одного узла осуществляется командой
sbatch myrun.shсо скриптом myrun.sh вида:
#!/bin/bash
#SBATCH -t 30 -n 4 -N 1 -L intel --mem-per-cpu 4950 --input /dev/null --job-name mpi.adv --output output --error errors
/opt/intel/compilers_and_libraries/linux/mpi/bin64/mpirun "advixe-cl" "--collect" "survey" "--project-dir" "./mpi_surv" "--search-dir" "src=./my_src" "--" "./my_mpi_app"Для импорта результатов анализа, полученного например 3 процессом, следует выполнить команду вида:
advixe-cl -project-dir ./mpi_surv_3 -import-dir ./mpi_surv -search-dir src=./my_src -mpi-rank=3Эта команда в текущем рабочем каталоге создает каталог проекта mpi_surv_3, доступный для просмотра в GUI.
Каталоги, задаваемые опцией -project-dir (surv, mpi_surv в примерах выше), – это для собранных данных каталоги верхнего уровня. Результаты для последовательных и OpenMP приложений хранятся в каталоге surv/e000, а для n-го процесса MPI приложения – в каталоге mpi_surv/rank.n. В этих каталогах можно увидеть подкаталоги hsxxx, trcxxx, stxxx, dpxxx и mpxxx в зависимости от использованного типа анализа .
Замечание. Полная информация (синтаксис с примерами) об advixe-cl может быть выдана по команде
advixe-cl -helpУточнить информацию о действии collect позволяет команда
advixe-cl -help collect
Типы анализа:
survey – помогает найти затратные по времени циклы и функции, так называемые «горячие точки» (hotspots), а также дает рекомендации по устранению проблем векторизации и советует, где добавить эффективную векторизацию и/или многопоточность.
tripcounts – собирает статистику по итерациям циклов, что позволяет принять лучшее решение о векторизации одних циклов или о стратегии потоков для других. Этот анализ проводится после survey, т.к. его результаты отражаются в отчете survey.
suitability – предсказывает максимальное ускорение приложения при моделировании многопоточного исполнения. Предсказание строится на основе вставленных аннотаций и ряда параметров моделирования «что-если», с которыми можно экспериментировать для выбора лучших участков при распараллеливании потоками.
dependencies – проверяет зависимости реальных данных в циклах, которые компилятор не векторизовал из-за предполагаемой зависимости, а также предсказывает проблемы совместного использования параллельных данных, базирующихся на вставленных аннотациях. В случае векторизации следует лучше характеризовать зависимости реальных данных, которые могут сделать принудительную векторизацию небезопасной. В случае предполагаемого использования многопоточного распараллеливания исправить проблемы с совместным использованием данных имеет смысл, если прогнозируемая выгода от максимального ускорения оправдает усилия.
Для этого типа анализа приложение строится с опциями -g и -O0. Входные данные следует сократить настолько, насколько возможно, чтобы минимизировать время счета.
map (Memory Access Patterns) – для отмеченных циклов проверяет наличие проблем с доступом к памяти, таких как несмежный (non-contiguous) или неединичный (non-unit stride) доступ.
Просмотр результатов в GUI на хосте
Для просмотра результатов проведенного анализа можно выполнить команду вида:
advixe-gui surv &Для удобства команда выполняется с освобождением командной строки (символ &). Использование & необязательно.
После запуска GUI в открывшемся окне следует выбрать Show My Result, после чего появится окно с панелями: Summary (открывается по умолчанию), Survey & Roofline, Refinement Reports, общими для вкладок Vectorization Workflow и Threading Workflow. По умолчанию открываются отчеты для Vectorization Workflow.
Summary показывает метрики программы (затраченное время, количество потоков) и циклов, выигрыш / эффективность векторизации, наиболее затратные по времени циклы, информацию о платформе.
Survey & Roofline детализирует информацию с учетом типа анализа, показывает исходный код, причины отсутствия векторизации циклов и рекомендации по улучшению кода.
Refinement Reports отображает отчет о шаблонах доступа к памяти (non-unit stride, …) и отчет о зависимостях.
Замечание. Можно получить образец с опциями нужной команды amplxe-cl -collect, используя возможность генерации этой команды в GUI. Выбрав нужный тип анализа, в строке Collect нажать на кнопку Get Command Line.
О примерах
Полезно познакомиться с Intel Advisor на предлагаемых разработчиками примерах. В частности, используя Threading Advisor, исследовать возможность распараллеливания кода для создания многопоточного приложения для программы Tachyon (/opt/intel/advisor/samples/en/C++/tachyon_Advisor.tgz).
Для этого надо скопировать её в свой домашний каталог, распаковать архиватором tar, используя команду
tar zxf tachyon_Advisor.tgzи дальше следовать рекомендациям из файла README.
Замечание. Анализ тестовой программы tachyon_Advisor проводится в рамках GUI, а следовательно, на управляющей машине кластера. В данном случае это допустимо, поскольку анализ занимает секунды. Полученный же начальный опыт работы в GUI может в дальнейшем пригодиться при анализе своих результатов, собранных на кластере с помощью команды advixe-cl.
Для погружения в тему, помимо обширной документации Intel, могут оказаться полезными (с поправкой на версию), например, следующие статьи:
1. От последовательного кода к параллельному за пять шагов c Intel® Advisor XE, где достаточно подробно описан и проиллюстрирован поэтапный (Survey Target, Annotate Sources, Check Suitability, Check Dependencies) анализ программы tachyon_Advisor.
2. Новый инструмент анализа SIMD программ — Vectorization Advisor, где пошагово (Survey Target, Find Trip Counts, Check Dependencies, Check Memory Access Patterns) проводится исследование кода на векторизацию.
Использование Intel® Inspector XE
Intel® Inspector XE – инструмент динамического анализа корректности кода, т.е. анализа исполняемого процесса. Inspector XE предназначен для поиска ошибок памяти и проблем, возникающих при взаимодействии потоков, в последовательных и многопоточных приложениях. Инспектировать можно код, написанный на C, C++, C# и Fortran.
Intel® Inspector XE позволяет запустить удаленный анализ на вычислительном узле кластера и просмотреть результаты сбора данных на хосте. Для сбора данных на кластере используется интерфейс командной строки inspxe-cl (Command Line Interface Support). Для просмотра результатов удобно использовать графический интерфейс (GUI), который вызывается командой inspxe-gui.
1. Intel Inspector XE проверяет весь исполненный код и не требует специальной перекомпиляции программ. Тем не менее рекомендуется включать в сборку приложения (его отладочной версии с -O0 или релиза) опцию -g для обеспечения связи исполняемого кода с исходным текстом.
Рекомендуется работать в окружении, устанавливаемом командой
mpiset 82. Для работы инспектора следует установить Intel Inspector XE окружение, выполнив команду:
source /opt/intel/inspector/inspxe-vars.shПримечание.
1. Поиск ошибок памяти (утечки, доступ к неинициализированной памяти и др.) связан с реально возникающими проблемами, поэтому рекомендуется использовать полный набор данных.
2. При поиске ошибок многопоточности (гонки данных, взаимные блокировки и др.) инспектор ищет потенциальные проблемы взаимодействия потоков, поэтому нагрузку на приложение для экономии времени лучше снизить, например уменьшить размер входных данных. При этом в процессе тестирования надо стремиться активизировать разные ветви кода, поскольку будет проанализирован только исполненный код. Так, взаимная блокировка будет найдена, даже если существует только потенциальная возможность её появления в исполнившихся ветках кода. Вот почему проверка потоков иногда сообщает об ошибках в программе, даже если программа выдает (имеет) правильный вывод.
Запуск Intel Inspector на вычислительном узле
Выполнение анализа инициируется командой inspxe-cl с указанием действия collect (сбор данных). Запустить её на кластере можно с помощью команд srun, sbatch или mqrun (см. Запуск задач на кластере). Например для последовательной программы (-n 1):
mqrun -n 1 inspxe-cl -collect mi1 -search-dir all:r=../ -- ./appгде
действие -collect mi1 означает собрать данные об ошибках памяти с учетом типа анализа mi1;
опция -search-dir all:r=../ задает родительский каталог в качестве начального для рекурсивного (r) поиска всех (all) типов файлов (bin, src, sym);app – исполняемый файл приложения в текущем рабочем каталоге (./).
Основные типы анализа:mi1 Detect Leaksmi2 Detect Memory Problemsmi3 Locate Memory Problemsti1 Detect Deadlocksti2 Detect Deadlocks and Data Racesti3 Locate Deadlocks and Data Races
Рекомендуется начать с первого уровня анализа (mi1, затем ti1), который характеризуется очень низкими накладными расходами (см. Collecting Result Data from the Command Line).
Замечания.
1. Для доступа к текущей документации о команде inspxe-cl следует набрать
inspxe-cl -helpУточнить информацию о действии collect позволяет команда
inspxe-cl -help collect2. Можно получить копию команды inspxe-cl -collect, которая будет выполнена в графическом интерфейсе Intel Inspector. Для этого, после вызова GUI:
inspxe-gui &создать, например, проект (выполнив New Project...), затем в главном окне выбрать New Analysis..., в открывшемся окне Configure Analysis Type выбрать тип анализа (например, Detect Leaks) и, нажав на кнопку Get Command Line, получить соответствующую команду.
Выдача результатов анализа
Собранные данные по умолчанию записываются в результирующий каталог с именем вида r@@@{at}, где
@@@ - следующий доступный номер для результата в текущем рабочем каталоге, 000 – начальный номер;
{at} – код типа анализа (analysis type).
Результирующий каталог, например r000mi1, содержит результирующий файл с тем же именем и расширением inspxe, например r000mi1.inspxe, а также краткий (суммарный, Summary) отчет в файле inspxe-cl.txt.
Краткий отчет включает общее число проблем, их типы, время старта и окончания анализа.
Замечание. Используя опцию -result-dir в команде inspxe-cl -collect, можно задать свой результирующий каталог. При этом к его имени можно приписать до 5-и знаков @. Это удобно в скриптах: не надо будет обновлять имя каталога каждый раз.
После каждого анализа следует посмотреть краткий отчет в файле inspxe-cl.txt. Если обнаружены проблемы, то можно открыть результат для визуализации в GUI или использовать команду inspxe-cl -report для генерации отчетов одного или более типов из полученного результата. Подробнее о команде см.:
inspxe-cl -help report
Для просмотра результатов проведенного анализа в GUI можно выполнить команду inspxe-gui с указанием результирующего каталога, например:
inspxe-gui r000mi1 &или выполнить вызов GUI:
inspxe-gui &и в открывшемся окне, выбрав Open Result, перейти в каталог с результатами анализа и открыть соответствующий файл, например файл r000mi1.inspxe в каталоге r000mi1.
Работа с MPI (ссылки)
- И.Евсеев MPI для начинающих.
- Вл.В.Воеводин Лекция об MPI.
- M.Snir, S.Otto, S.Huss-Lederman, D.Walker, J.Dongarra MPI: The Complete Reference (англ.)
- MPI-2: Extensions to the Message-Passing Interface (параллельный ввод-вывод) (англ.)
Прикладные пакеты
Здесь находятся рекомендации по установке, запуску и оптимизации для вычислений на кластере различных программных пакетов
Компиляция и запуск C2PK
C2PK — Программный пакет для квантовой химии и физики твердого тела. Репозиторий на github.
Последовательность сборки пакета в домашнем каталоге
#Выбор mpi - vapich4.1/gcc 8.5.0
module load mvapich4/gcc64
# Вспомогательная библиотека DBCSR от разработчиков C2PK
wget 'https://github.com/cp2k/dbcsr/releases/download/v2.9.1/dbcsr-2.9.1.tar.gz'
tar xf dbcsr-2.9.1.tar.gz
mkdir dbcsr-2.9.1/build
cd dbcsr-2.9.1/build
# каталог установки ~/dbcsr
cmake .. -DUSE_MPI=ON -DCMAKE_C_COMPILER=mpicc -DCMAKE_CXX_COMPILER=mpic++ -DCMAKE_Fortran_COMPILER=mpif90 -DCMAKE_INSTALL_PREFIX=${HOME}/dbcsr
make -j 8
make install
# Возвращаемся в исходный каталог
cd ../..
# Сборка CP2K
wget https://github.com/cp2k/cp2k/releases/download/v2026.1/cp2k-2026.1.tar.bz2
tar xf cp2k-2026.1.tar.bz2
mkdir cp2k-2026.1/build
cd cp2k-2026.1/build
# каталог установки ~/cp2k
cmake .. -DCMAKE_C_COMPILER=mpicc -DCMAKE_CXX_COMPILER=mpic++ -DCMAKE_Fortran_COMPILER=mpif90 -DCP2K_USE_MPI=ON -DCMAKE_INSTALL_PREFIX=${HOME}/cp2k
make -j 8
make install
cd ../..
Установка примеров (при желании):
git clone https://github.com/cp2k/cp2k-examples.git
Пример запуска из подкаталога _scratch/work домашнего каталога:
module load mvapich4/gcc64
export LD_LIBRARY_PATH="${HOME}/cp2k/lib64/:$LD_LIBRARY_PATH"
export PATH="${HOME}/cp2k/bin/:$PATH"
mkdir ~/_scratch/work
cd ~/_scratch/work
cp ~/cp2k-examples/gw/1_H2O_GW100/H2O_GW100_def2-QZVP.inp test.inp
export OMP_NUM_THREADS=8
export OMP_PLACES=cores
export OMP_PROC_BIND=true
srun --ntasks-per-node=2 --cpus-per-task=8 -N 1 cp2k.psmp -i test.inp > test.out
Оптимизация запуска LAMMPS
Сгенерировано ИИ
Выбор оптимального числа узлов кластера для LAMMPS — это процесс поиска баланса между скоростью счета и эффективностью использования ресурсов. Не существует единственного "правильного" числа, так как оно зависит от размера вашей системы, аппаратного обеспечения и физической модели. Вот пошаговая стратегия, которая поможет вам найти этот оптимум.
1. Проведите тест масштабирования
Это главный метод для определения лимитов масштабируемости. Суть в том, чтобы взять фиксированную задачу (вашу систему с определенным количеством атомов) и запускать её на нарастающем количестве ядер (например, N=1, 2, 4, 8, 16, 32, 64, 128...).
Что делать: Запустите вашу систему на 100-200 шагов для каждого количества ядер. Используйте команды balance или fix balance для распределения нагрузки .
На что смотреть:
- Время расчета (
Loop time): Сравните, во сколько раз ускорился расчет. Идеальное ускорение (100%) — это когда на 64 ядрах расчет идет в 64 раза быстрее. - Эффективность: Рассчитайте эффективность как
(T1 / TN) / N * 100%. Как правило, LAMMPS показывает эффективность >50%, пока на одно ядро приходится несколько сотен атомов .
Где предел: Вы увидите, что после определенного числа ядер время перестает значительно сокращаться. Это и есть точка насыщения, где накладные расходы на коммуникацию (обмен данными между узлами) начинают доминировать над вычислениями.
2. Используйте анализ профайлера (Timing Data)
После каждого прогона LAMMPS выводит детальную статистику. Это ваш главный инструмент диагностики. В конце файла log.lammps вы увидите таблицу:
| Section | %varavg | %total |
|---|---|---|
| Pair | ... | ... |
| Neigh | ... | ... |
| Comm | ... | ... |
| Other | ... | ... |
Следите за Comm (Communication): Если процент времени, потраченный на коммуникацию (Comm), при увеличении числа узлов становится слишком большим (например, >30-40%), дальнейшее добавление узлов неэффективно. Прирост производительности будет минимальным .
Следите за %varavg: Высокое значение (близкое к 100%) указывает на сильную несбалансированность нагрузки. Это значит, что одни ядра простаивают в ожидании других. В этом случае стоит сначала попробовать балансировку (fix balance) .
3. Учитывайте геометрию и разбиение (Domain Decomposition)
LAMMPS использует пространственное разбиение: симуляционный ящик режется на прямоугольные блоки, каждый из которых отдается одному MPI-процессу .
Проблема "блинов": Если вы используете "неудобное" число MPI-процессов (например, простое число, такое как 7 или 11), разбиение может получиться несбалансированным (например, длинные и тонкие "слайсы").
Что делать: Используйте команду processors в скрипте, чтобы вручную задать раскладку сетки (например, processors 4 4 4 для 64 ядер), чтобы блоки были максимально кубическими. Это минимизирует площадь поверхности обмена данными .
4. Учитывайте тип потенциала и системы
Разные задачи масштабируются по-разному :
Потенциалы малого радиуса (LJ, EAM): Обычно хорошо масштабируются. Ограничением часто становится сетка для дальнодействия (PPPM).
Дальнодействие (Kspace, PPPM): Если в системе есть кулоновские взаимодействия (вода, ионы), расчеты PPPM включают быстрые преобразования Фурье (FFT). FFT требует глобальной коммуникации, что сильно ухудшает масштабируемость за пределы одного узла. В таких системах "золотой серединой" часто является 1-4 узла, даже если у вас много ядер.
Связанные списки (Neigh): Если в профайлере Neigh занимает >50% времени, попробуйте увеличить параметр every в команде neigh_modify (например, с 1 на 10), чтобы реже перестраивать списки соседей .
5. Настройка гибридного параллелизма (MPI + OpenMP)
Для многоядерных узлов часто эффективнее использовать гибридный режим вместо "чистого" MPI.
Правило: Запускайте 1 MPI-процесс на сокет (физический чип) или на группу ядер, используя OpenMP для распараллеливания внутри узла.
Зачем: Это уменьшает количество MPI-сообщений, которыми обмениваются узлы, и снижает нагрузку на коммуникационную сеть .
Резюме: Пошаговый алгоритм действий
- Оцените размер: Для хорошей производительности на одно ядро должно приходиться от 500 до 10 000 атомов.
- Балансировка: Если система неоднородна (например, жидкость с пузырьками или мембрана), обязательно используйте
fix balance 10 1.1 rcb. - Тест: Начните с 1 узла, увеличивая количество ядер (но не выходя за пределы 500–1000 атомов/ядро).
- Проверка узлов: Когда эффективность на одном узле упадет ниже 70-80% (смотрите на рост
Comm), начните добавлять второй, третий и четвертый узлы. - Стоп-критерий: Как только время расчета перестает уменьшаться пропорционально количеству добавленных ядер (например, добавили 10 ядер, а расчет стал быстрее только на 5%), вы нашли оптимум.
Важное примечание
Официальная документация LAMMPS подчеркивает: "Нет замены определению узких мест производительности и опробованию различных вариантов" . Всегда проверяйте гипотезы короткими прогонами (100-200 шагов) на вашей конкретной системе и вашем конкретном кластере.
Параллельный Matlab
Система Matlab (Matrix Laboratory) - разработка компании The MathWorks, предназначенная для выполнения математических расчетов при решении научных и инженерных задач.
Достоинства Matlab – это, прежде всего, простота матричных операций и наличие многочисленных пакетов программ (Toolbox-ов), среди которых
Parallel Computing Toolbox, расширяющий Matlab на уровне языка операциями параллельного программирования.
Parallel Computing Toolbox достаточно для написания и запуска параллельной Matlab программы на локальной машине (Product Documentation).
Вычисления с Matlab на кластере требуют уже 2 продукта:
Parallel Computing Toolbox и
Matlab Distributed Computing Server
В ИММ имеются все 3 основных продукта для параллельных вычислений с Matlab на кластере "Уран" (версия Matlab R2011b и старше):
1) Matlab: 10 лицензий,
2) Parallel Computing Toolbox: 10 лицензий
(прежнее название Distributed Computing Toolbox),
3) Matlab Distributed Computing Server: 1000 лицензий
(прежнее название Matlab Distributed Computing Engine);
а также большое количество специализированных Toolbox-ов: по 10 лицензий на SIMULINK, Signal_Blocks, Image_Acquisition_Toolbox, Image_Toolbox, MAP_Toolbox, Neural_Network_Toolbox, Optimization_Toolbox, PDE_Toolbox, Signal_Toolbox, Statistics_Toolbox, Wavelet_Toolbox и 2 лицензии на Filter_Design_Toolbox.
Список всех установленных на кластере продуктов Matlab и количество доступных лицензий на них можно уточнить командой
/opt/matlab-R2010a/etc/lmstat -aНазвание текущей рабочей версии Matlab можно узнать, набрав, например, в командной строке
echo 'exit' | matlab -nodisplayили выполнив в окне Matlab команду ver.
Замечания.
1. При работе в Matlab следует ориентироваться на документацию используемой версии.
2. Для смены текущей версии следует воспользоваться командой module.
Можно запускать программы из командной строки или из системы Matlab.
Для запуска программ на кластере из командной строки пользователю необходимо установить на своем компьютере программу PuTTY.
Запуск параллельных Matlab-программ из командной строки осуществляется с помощью разновидностей команды mlrun.
Для работы в диалогом окне Matlab на компьютере пользователя предварительно должен быть установлен и запущен какой-нибудь X-сервер (MobaXterm, X2Go).
Из командной строки вызвать Matlab
matlab или
matlab & (с освобождением командной строки)
и дождаться появления оконного интерфейса Matlab.
Запуск параллельных программ на кластере из системы Matlab осуществляется с помощью разновидностей служебной функции imm_sch.
Замечание. Можно работать в системе Matlab, запустив её в интерактивном текстовом режиме командой
matlab -nodisplayВыход осуществляется по команде exit.
Параллельные вычисления на кластере инициируются
1) запуском параллельных програм;
2) запуском частично параллельных программ (c parfor или spmd);
3) запуском программ с использованием GPU.
Подробнее на нижеследующих страницах.
В разделе "Запуск задач на кластере" находится краткая инструкция "Запуск параллельного Matlab".
Использование русских букв в Linux версии Matlab
Для работы с русскими буквами в Matlab'е необходимо правильно настроить кодировку файла с программой, и, при необходимости, настроить ввод русских букв в клиентской программе.
Возможны два варианта настройки кодировки файла с программой:
- Если в основном вы работаете в Windows, то рекомендуется использование кодировки CP1251.
- Если вы создаёте, редактируете и запускаете программы в основном в Linux, то рекомендуется использование кодировки UTF-8 (кодировка на кластере по умолчанию).
Вариант 1
На кластере "Уран" при запуске Matlab'а можно включить Windows-кодировку CP1251. Для этого необходимо запускать Matlab в окне терминала следующей командой:
LANG=ru_RU.CP1251 matlabПосле этого можно нормально работать с файлами, подготовленными в Windows.
Внимание. Данный вариант может не сработать при запуске счётной задачи на узлах кластера.
Как минимум, в начало счетной программы надо вставить команду:
feature('DefaultCharacterSet', 'cp-1251');
После этого строки, выводимые функцией fprintf(), будут сохраняться в правильной кодировке. Строки на русском языке, выводимые функцией disp(), к сожалению, будут испорчены в любом случае.
Если в программе для вывода результатов используется функция disp(), выполняются операции сравнения или сортировки строк с русскими буквами, то стоит попробовать второй вариант.
Вариант 2
После передачи файла из Windows на кластер можно перекодировать его в кодировку UTF-8. Следует помнить, что перекодированный файл будет некорректно отображаться в Windows, зато он без проблем будет обрабатываться на кластере.
2.a Перекодирование файла на кластере в командной строке. Файл перекодируется с помощью команды
iconv -c -f WINDOWS-1251 -t UTF-8 winfile.m > unixfile.m где winfile.m - имя исходного файла, а unixfile.m - перекодированного (подставьте вместо winfile.m и unixfile.m имена ваших файлов, главное, помните - они должны быть различными). Затем можно открыть новый файл в Matlab'е.
2.b Перекодирование файла на кластере в текстовом редакторе. Для перекодирования файла необходимо запустить текстовый редактор KWrite (Linux'овская кнопка "Пуск", затем ввести в строке поиска имя редактора). При открытии файла с программой указать кодировку cp1251, убедиться, что русские буквы читаются правильно, затем выбрать пункт меню "Файл ->Сохранить как" и указать при сохранении кодировку UTF-8.
Если есть необходимость перекодировать файлы, полученные с кластера, то это также можно сделать с помощью KWrite. При открытии файла надо выбрать кодировку UTF-8, а потом сохранить файл в кодировке cp1251.
В командной строке перекодирование из Linux в Windows выглядит так:
iconv -c -f UTF-8 -t WINDOWS-1251 unixfile.m > winfile.m
Примечание для администраторов
В дистрибутиве RHEL и его производных (CentOS, Scientific Linux) отсутствует файл локализации ru_RU.CP1251. Поэтому "Вариант 1" не сработает (Matlab не запустится с сообщением о невозможности установить указанный язык).
Для генерации файла с кодировкой администратор должен выполнить в Linux'е команду:
localedef -i ru_RU -f CP1251 ru_RU.CP1251
Историческое примечание
Старые версии Matlab'а (до 2010 года) умели работать с единственной кодировкой русских букв ISO-8859-5. Для того, чтобы ее настроить на серверной стороне, необходимо установить переменную окружения LANG в значение ru_RU.8859-5 .
1) Для корректной обработки русских букв на вычислительных узлах
в файл ".bashrc" из домашнего каталога пользователя (~/.bashrc) необходимо вставить следующую строку:
export LANG=ru_RU2) в настройках сессии программы PuTTY, в разделе Translation, установить кодировку ISO-8859-5:1999 (Latin/Cyrillic) и сохранить эту сессию для работы с системой Matlab в дальнейшем.
Запуск параллельной программы
Основные сведения
Параллельная программа - это программа, копии которой, запущенные на кластере одновременно, могут взаимодействовать друг с другом в процессе счета.
Программа пользователя должна быть оформлена как функция (не скрипт) и находиться в начале запускаемого файла, т.е. предшествовать возможным другим вспомогательным функциям. Имя файла должно совпадать с именем первой (основной) функции в файле. Одноименная с файлом функция, не являющаяся первой, никогда не будет выполнена, так как независимо от имени всегда выполняется первая функция файла. Файл должен иметь расширение "m" (Пример параллельной программы).
Для выполнения программы пользователя всегда вызывается программа MatLab.
При запуске программы пользователя на кластере в программе MatLab создаётся объект Job (работа) с описанием параллельной работы, которое включает определение объекта Task (задача), непосредственно связанного с заданной программой. Можно сказать, что копия работающей программы представлена в системе MatLab объектом Task.
Каждый объект Job получает идентификатор (ID) в системе MatLab, равный порядковому номеру. Нумерация начинается с 1.
Соответствующее имя работы вида Job1, выдаваемое при запуске, хранится в переменной окружения MDCE_JOB_LOCATION и может быть использовано в программе, а сам объект доступен пользователю во время сеанса MatLab.
Аналогично пользователь имеет доступ и к объектам Task (задача), которые также нумеруются с 1. Идентификатор или номер задачи (1,2,...) - это номер соответствующего параллельного процесса (lab) и его можно узнать с помощью функции labindex, а общее число запущенных копий с помощью функции numlabs.
Имена работы (Job1), задач (Task1, Task2,…) используются в процессе вычислений для формирования имен файлов и каталогов, связанных с заданной программой. Так, каталог вида Job1 содержит наборы файлов с информацией по задачам. Имена этих файлов начинаются соответственно с Task1, Task2, … Например, файлы вывода имеют вид Task1.out.mat, Task2.out.mat, … и содержат, в частности, выходные параметры функции пользователя (массив ячеек argsout).
Программа пользователя, оформленная в виде объекта Job, поступает в распоряжение системы запуска, которая ставит её в очередь на счет с присвоением своего уникального идентификатора.
Система запуска создает каталог вида my_function.1, например для файла my_function.m. В этом каталоге пользователю может быть интересен, в частности, файл errors (см. Возможные ошибки). Заметим, что пользователь должен сам удалять ненужные каталоги вида имя_функции.номер (номера растут, начиная с 1).
Если ресурсов кластера достаточно, то на каждом участвующем в вычислении процессоре (ядре для многоядерных процессоров) начинает выполняться копия программы-функции пользователя при условии наличия достаточного числа лицензий (в настоящее время система запуска не контролирует число лицензий, доступность лицензий определяется в начале счета).
Пользователь может контролировать прохождение своей программы через систему запуска как в окне системы Matlab, например, с помощью Job Monitor (см. п. Доступ к объекту Job ), так и из командной строки с помощью команд системы запуска (запросить информацию об очереди, удалить стоящую в очереди или уже выполняющуюся программу).
Действия пользователя
Войти на кластер (с помощью PuTTY или MobaXterm) и запустить программу-функцию из командной строки или в окне системы Matlab, указав необходимое для счета число параллельных процессов и максимальное время выполнения в минутах.
В ответ пользователь должен получить сообщение вида:
Job output will be written to: /home/u1303/Job1.mpiexec.out где Job1 - имя сформированной работы, 1 - идентификатор работы
(/home/u1303 - домашний (личный) каталог пользователя).
Замечание. Для локализации результатов вычислений рекомендуется осуществлять запуск программы (даже в случае запуска встроенных функций Matlab ) из рабочего каталога, специально созданного для данной программы в домашнем каталоге.
Запуск параллельной программы из командной строки
Команда запуска mlrun имеет вид
mlrun -np <number_of_procs> -maxtime <mins> <func> ['<args>']где<number_of_procs> - число параллельных процессов (копий программы)<mins> - максимальное время счета в минутах<func> - имя файла с одноименной функцией (например, my_function)<args> - аргументы функции (не обязательный параметр) берутся в одиночные кавычки и представляются в виде
k,{arg1,...,argn}
где k - число выходных аргументов функции, а в фигурных скобках список ее входных аргументов. При отсутствии аргументов у функции, что соответствует "0,{}", их можно опустить. Например, для файла my_function.m с одноименной функцией без параметров запуск имеет вид:
mlrun -np 8 -maxtime 20 my_functionгде 8 - число процессов, 20 - максимальное время счета в минутах.
Запуск параллельной программы в окне Matlab
В командном окне Matlab (Command Window) вызвать служебную функцию imm_sch, которой в качестве параметров передать число процессов, время выполнения и предназначенную для параллельных вычислений функцию с аргументами или без, сохраняя (рекомендуется) или не сохраняя в переменной (например, job) ссылку на созданный объект Job (имя функции набирается с символом "@" или в одиночных кавычках):
job = imm_sch(np,maxtime,@my_function,k {arg1,...,argn});или
job = imm_sch(np,maxtime,'my_function',k,{arg1,...,argn});Так, для примера выше запуск в окне Matlab будет иметь вид:
job = imm_sch(8,20,@my_function);Доступ к объекту Job, состояние работы
Все работы хранятся на кластере. При необходимости доступа к работе, на которую в текущий момент отсутствует ссылка, можно (1) в окне Job Monitor правой кнопкой мыши выделить нужную работу и выбрать соответствующую опцию в контекстном меню или (2) по идентификатору (ID) определить ссылку на работу (обозначенную ниже job), используя, например, команды:
c = parallel.cluster.Generic
job = c.findJob('ID',1)Состояние работы (State) можно:
(1) увидеть в окне Job Monitor или
(2) выдать в окне Command Window, набрав
job.State
Основные значения состояния работы следующие:
pending (ждет постановки в очередь)
queued (стоит в очереди)
running (выполняется)
finished (закончилась)
Окончания счета (состояние finished) можно ждать с помощью функции wait, wait(job) или job.wait()
Примечание.
Вышеприведенные команды предназначены для версий MatLab с профилем кластера, т.е. начиная с R2012a. В ранних версиях (с конфигурацией кластера) следует набирать:
s = findResource('scheduler', 'type', 'generic')
job = findJob(s,'ID',1)При этом в поле DataLocation структуры s должен быть текущий каталог (тот, в котором ищем работу). Если каталог другой, то можно выполнить
clear allи повторить предыдущие команды.
В окне Matlab (с R2012a) для работы job и любой ее задачи (Task) с номером n=1,2,... можно выдать (далее для удобства n=1)
1) протокол сеанса:
job.Tasks(1).Diary2) информацию об ошибках (поле ErrorMessage):
job.Tasks(1) или job.Tasks(1).ErrorMessage
3) результаты (значения выходных параметров) работы job в целом (по всем Task-ам):
out = job.fetchOutputsТогда для 1-ой задачи (Task) значение единственного выходного параметра:
res = out{1}
В случае нескольких выходных параметров соответственно имеем для 1-го, 2-го, ... :
res1 = out{1,1}
res2 = out{1,2}
Другой способ выдачи результатов по задачам
out1 = job.Tasks(1).OutputArgumentsЗамечания.
1. Эту же информацию можно выдать, запустив Matlab в интерактивном текстовом режиме (matlab -nodisplay) и набирая затем упомянутые команды.
2. Если ссылка на работу (job) отсутствует, то ее можно найти по идентификатору.
3. Для ранних версий (до R2012a) следует использовать следующие команды, чтобы выдать
1) протокол сеанса:
job.Tasks(1).CommandWindowOutput 3) результаты (значения выходных параметров) работы job в целом (по всем Task-ам):
out = job.getAllOutputArguments1. Начать работу на кластере рекомендуется с запуска своей последовательной программы в тестовом однопроцессном варианте, например,
mlrun -np 1 -maxtime 20 my_functionгде my_function – функция без параметров, максимальное время счета 20 минут.
2. После преобразования последовательной программы в параллельную её работоспособность можно проверить, выполняя шаги, приведенные в пункте Как убедиться в работоспособности программы при рассмотрении примеров с распределенными массивами.
Пример запуска программы
Для запуска программы на кластере используем функцию rand, вызываемую для генерации 2х3 матрицы случайных чисел (традиционный вызов функции: y = rand(2,3)).
Для получения 4 экземпляров матрицы задаем число процессов, равное 4. Максимальное время счета пусть будет равно 5 минутам.
Запускать функцию будем на кластере "Уран" (umt) в каталоге test, специально созданном заранее в домашнем каталоге пользователя /home/u9999, где u9999 – login пользователя (см. Схема работы на кластере и Базовые команды ОС UNIX).
Для запуска функции rand из командной строки используется команда mlrun,
а из системы Matlab – служебная функция imm_sch.
Для запуска из командной строки войти на umt через PuTTY и выполнить команду
mlrun -np 4 -maxtime 5 rand '1,{2,3}'Для запуска из окна Matlab войти на umt из MobаXterm, вызвать Matlab командой
matlab &и в открывшемся окне набрать
job = imm_sch(4,5,@rand,1,{2,3});где job – ссылка на сформированную работу.
Можно работать в системе Matlab, войдя на umt через PuTTY и запустив её в интерактивном текстовом режиме командой
matlab -nodisplayВ ответ на приглашение (>>) следует соответственно набрать
job = imm_sch(4,5,@rand,1,{2,3});Выход из Matlab осуществляется по команде exit.
После выполнения mlrun или imm_sch выдается строка вида
Job output will be written to: /home/u9999/test/Job1.mpiexec.outгде Job1 - имя сформированной работы, 1 - идентификатор (номер) работы.
Если ресурсов кластера достаточно, задача войдет в решение (см. Запуск задач на кластере). Иначе для ускорения запуска на кластере небольших (отладочных) задач можно вместо выделенного задаче раздела назначить debug командой вида:
scontrol update job 8043078 partition=debugгде 8043078 — уникальный идентификатор (JOBID) задачи.
Дожидаемся окончания задачи, т.е. job.State должно быть finished.
В окне Matlab контролировать состояние задачи удобно с помощью Job Monitor.
Результаты выдаем с помощью команд:
со всех процессов
out = job.fetchOutputsа для выдачи матрицы, полученной 1-ым процессом (т.е. Task1)
out{1}и т.д.
Для выдачи результатов ранее посчитанной работы, на которую в текущий момент нет ссылки, следует обеспечить к ней доступ, например используя Job Monitor.
Запуск частично параллельной программы (c parfor или spmd)
- Введение
- 1. Запуск частично параллельной программы с неявным заданием пула
- 2. Запуск частично параллельной программы с явным заданием пула
на основе профиля кластера
Введение
Частично параллельной будем называть программу, при выполнении которой наряду с последовательными возникают параллельные вычисления, инициируемые параллельными конструкциями языка Matlab parfor и spmd.
Использование параллельного цикла parfor или параллельного блока spmd предполагает предварительное открытие Matlab пула, т.е. выделение необходимого числа процессов (Matlab workers или labs), на локальной машине или на кластере.
Запуск частично параллельных программ с открытием Matlab пула на кластере можно выполнять
(1) по аналогии с запуском параллельных программ из командной строки или в окне системы Matlab (запуск с неявным заданием пула) или
(2) на основе профиля кластера (с версии R2012a, ранее параллельной конфигурации) при работе в окне системы Matlab (запуск с явным заданием пула).
Пользователь может контролировать прохождение своей программы через систему запуска как в окне системы Matlab (с версии R2011b) с помощью Job Monitor (см. пункт меню Parallel), так и из командной строки с помощью команд системы запуска.
1. Запуск частично параллельной программы с неявным заданием пула
При запуске из командной строки вместо команды mlrun (для параллельных программ) следует использовать команду mlprun, например,
mlprun -np 12 -maxtime 20 my_function '1, {x1, x2}'а при запуске в окне вместо функции imm_sch использовать функцию imm_sch_pool, например,
job = imm_sch_pool(12,20,@my_function,1,{x1,x2});для функции, определенной как
function y = my_function(x1,x2)и запущенной на 12 процессах с максимальным временем счета 20 минут.
При этом один процесс будет выполнять программу-функцию, а оставшиеся будут использованы в качестве пула.
В результате запуска программа ставится в очередь на счет и, если ресурсов кластера достаточно, входит в решение.
Вывод результатов осуществляется так же, как и в случае параллельных программ.
2. Запуск частично параллельной программы с явным заданием пула
на основе профиля кластера
Явное задание пула возможно при работе в окне Matlab с помощью команды matlabpool (см. help matlabpool). Число выделенных процессов и время, в течение которого они будут доступны пользователю, зависят от заданного профиля кластера (см. пункт меню Help/Parallel Computing Toolbox/Cluster Profiles).
Команда
matlabpoolбез параметров открывает пул, используя профиль по умолчанию с указанным в нем размером пула. В ИММ УрО РАН по умолчанию Matlab пул открывается на узлах кластера (тип кластера Generic), поскольку управляющий компьютер, выступающий в роли локальной машины (Matlab client), не должен использоваться для длительных вычислений.
Пользователь может выбрать профиль по умолчанию из уже существующих профилей или создать новый, используя пункт меню Parallel окна Matlab.
Команда matlabpool с указанием размера пула, например
matlabpool open 28открывает пул, переопределяя размер, заданный по умолчанию. При этом следует иметь в виду, что существует ограничение на максимальное число доступных пользователю процессов на кластере.
В результате открытия пула сформированная для кластера работа с именем вида JobN (где N=1,2,...) поступает в распоряжение системы запуска и ставится в очередь на счет. Если свободных процессов достаточно, то пул будет открыт на время, заданное в профиле по умолчанию, с выдачей сообщения вида:
Starting matlabpool using the 'imm_20mins' profile ... Job output will be written to: /home/u1303/my_directory/Job1.mpiexec.out
connected to 28 labs.Размер пула можно узнать, набрав
matlabpool sizeПо завершении вычислений, связанных с пулом, его следует закрыть
matlabpool closeВнимание. Пул закрывается по истечении времени с диагностикой вида:
The client lost connection to lab 12.
This might be due to network problems, or the interactive matlabpool job might have errored.
Запуск частично параллельной программы на Matlab клиенте
(не разрешается для длительных вычислений)
Итак, схема использования параллельных конструкций parfor и spmd в окне Matlab такова:
matlabpool
...
% вычисления с использованием parfor или spmd,
% выполняемые построчно или
% собранные в программу (частично параллельную)
% и запущенные из файла
...
matlabpool closeПри этом все вычисления, кроме параллельных, выполняет Matlab client (см., например, Introduction to Parallel Solutions/Interactively Run a Loop in Parallel.)
Запуск частично параллельной программы с помощью команды batch
В системе Matlab существует команда (функция) batch, которая позволяет запускать программы в пакетном режиме, разгружая Matlab client (см., например, Introduction to Parallel Solutions/Run a Batch Job). Эта команда выполняется асинхронно, т.е. интерактивная работа пользователя не блокируется.
Где будет выполняться программа и максимально сколько времени, определяется планировщиком (scheduler), заданным в профиле кластера по умолчанию: в ИММ на кластере, тип планировщика generic. Для выполнения программы создается объект Job (работа). Команда batch вида
job = batch('my_mfile')(job - ссылка на объект работа)
запускает программу (скрипт или функцию) my_mfile в однопроцессном варианте. В ответ на команду batch выдается сообщение вида
Job output will be written to: /home/u1303/my_directory/Job1.mpiexec.outсодержащее идентификатор работы (ID), равный здесь 1. Сформированная для кластера работа ставится в очередь и при наличии свободных процессов входит в решение с именем очереди вида my_mfile.1.
Для запуска на кластере частично параллельной программы можно использовать команду batch с открытием пула. При этом выделяемое на кластере число процессов будет на 1 больше заданного размера пула.
Так, например, для выполнения команды
job = batch('my_mfile','matlabpool',11)потребуется 12 процессов: 1 для программы my_mfile, 11 для пула (см., например, Introduction to Parallel Solutions/Run a Batch Parallel Loop). Время счета здесь определяется временем, заданным в профиле по умолчанию (в аналогичной команде imm_sch_pool все аргументы задаются явно).
По завершении работы job можно выдать
1) протокол сеанса
job.diary2) результаты работы
out=job.fetchOutputs
celldisp(out)
(fetchOutputs вместо getAllOutputArguments в ранних версиях, использовавших конфигурацию кластера, а не профиль)
3) информацию об ошибках (поле ErrorMessage)
job.Tasks(1)или
job.Tasks(1).ErrorMessageЗапуск программ с использованием GPU
Программа с использованием GPU - это параллельная программа, каждая ветвь (копия, процесс), которой может использовать своё GPU.
Поэтому к программе с GPU применимо почти все, что относится к параллельной программе (в частности, это должна быть программа-функция). Особенности запуска программ с GPU отмечены ниже.
Программа с использованием GPU в результате запуска ставится в очередь на счет в системе SLURM. Пользователь может контролировать прохождение своей программы через эту систему с помощью соответствующих команд или в окне системы Matlab (с версии R2011b) с помощью Job Monitor (см. пункт меню Parallel).
При запуске программы-функции, как обычно, указывается необходимое для счета число параллельных процессов и максимальное время выполнения в минутах, но используются другие команды.
Запуск программы на счет осуществляется по аналогии с запуском параллельных программ:
из командной строки с помощью команды mlgrun, например,
mlgrun -np 8 -maxtime 20 my_gpufunction
или в окне системы Matlab с помощью служебной функции imm_sch_gpu, например,
job = imm_sch_gpu(8,20,@my_gpufunction);
В приведенных командах запускается функция без параметров с использованием 8 процессов, 20 минут - максимальное время счета.
При этом каждый из 8 процессов (копий функции) может использовать своё GPU.
При наличии параметров у функции они указываются по тем же правилам, что и в случае параллельной программы.
Возможные ошибки
1) Если не хватает лицензий для запуска на кластере функции my_function из одноименного файла my_function.m, то информация об ошибке находится в файле вида my_function.1/errors. При этом, как правило, файл my_function.1/output содержит MPIEXEC_CODE=123. Число свободных лицензий, кто и какие лицензии занимает, можно узнать, используя команду lmstat.
Внимание. В настоящее время система запуска не контролирует число лицензий, доступность лицензий определяется только в начале счета.
2) ErrorMessage содержит ошибки трансляции, например:
Undefined function or variable 'my_function'.Имя или расширение файла, имя функции или переменной отсутствует или указано неверно. Имя может отсутствовать по причине случайного запуска из другого каталога.
Invalid function name 'j-cod'.В именах файлов и функций не должно быть минуса ("-"), только подчерк ("_").
Invalid file identifier. Use fopen to generate a valid file identifier.Возможно, имя файла задано русскими буквами.
Внимание. В случае таких ошибок в файле my_function.1/errors обычно содержится строка
[0]application called MPI_Abort(MPI_COMM_WORLD, 42) - process 0Помните: имя файла должно совпадать с именем первой функции в файле, так как
(1) при запуске программы ищется файл с именем, указанным в команде запуска, и
(2) в нем выполняется, прежде всего, первая функция.
Если они не совпадают и при запуске указано имя функции (например, my_function), то файл не будет найден и будет выдана ошибка вида:
Undefined function or variable 'my_function'. Если они не совпадают и при запуске указано имя файла (например, my_code), то выполнится первая функция файла независимо от ее имени. При этом наличие одноименной с файлом функции, не являющейся первой, приведет к выдаче в протоколе сеанса предупреждения вида:
Warning: File: my_code.m Line: 25 Column: 14
Function with duplicate name "my_code" cannot be called.
3) Если выполнение программы прервано принудительно, например, по истечению времени, то выходная информация отсутствует (т.е. файлы вывода вида Task1.out.mat будут пусты). При этом состояние работы (поле State) будет running, в то время как состояния её задач (поля State для Tasks(n), где n=1,2,...) могут быть как running, так и finished, если часть копий программы успела финишировать до окончания заказанного времени.
В случае исчерпания времени соответствующая информация попадает в файл my_function.1/errors.
4) В случае аварийного завершения работы программы в домашнем каталоге пользователя (~) могут оставаться файлы вида mpd.hosts.123456 и mpd.mf…
Их следует периодически удалять вручную.
Завершение работы
Работу, в которой нет больше необходимости, следует уничтожить, используя Job Monitor (Delete в контекстном меню) или функцию delete, освобождая тем самым ресурсы кластера
job.deleteтакже удалить файл вида Job1.mpiexec.out (где Job1 - имя удаляемой работы),
а затем почистить Workspace
clear job
Если эти действия не выполняются пользователем регулярно, то при очередных запусках будут создаваться и накапливаться файлы новых работ Job2, Job3 и т.д.
Не все работы заканчиваются с признаком finished. Так, по истечении времени счета работа будет прервана в состоянии running.
Для уничтожения в текущем каталоге всех или только завершившихся (finished) работ можно воспользоваться написанной в ИММ УрО РАН функцией job_destroy.
Вызов job_destroy без параметра
из командной строки:
echo 'job_destroy, exit' | matlab -nodisplayв окне:
job_destroyуничтожает только завершившиеся работы.
Вызов job_destroy с параметром (тип и значение параметра не существенны)
из командной строки:
echo 'job_destroy(1), exit' | matlab -nodisplayили
echo "job_destroy('all'), exit" | matlab -nodisplayв окне:
job_destroy(1)или
job_destroy('all')уничтожает все работы в текущем каталоге.
Внимание! В состоянии running, разумеется, находятся выполняющиеся в текущий момент работы, поэтому выполняйте команду job_destroy(1) только тогда, когда Вы твердо уверены, что все работы закончились (нормально или аварийно).
После выполнения этой команды нумерация работ начинается с 1.
После уничтожения ненужных работ следует удалить на них ссылки в Workspace с помощью команды clear.
Важные замечания.
1. Нумерация работ (Job) в каталоге пользователя начнется с 1 в новом сеансе Matlab при отсутствии каталогов и файлов предыдущих работ (Job...).
2. Каталог вида my_function.1 не удаляется при использовании команды job_destroy. При новых запусках одной и той же программы образуются аналогичные каталоги с возрастающими номерами: my_function.2, my_function.3…
Пользователь должен сам удалять ненужные каталоги.
Пример параллельной программы
Пример взят с сайта MathWorks и иллюстрирует основные (базовые) принципы программирования параллельной программы-функции.
Копия работающей функции, т.е. задача (Task), для которой значение labindex равно 1, создает магический квадрат (magic square) с числом строк и столбцов равным числу выполняющихся копий (numlabs) и рассылает матрицу с помощью labBbroadcast остальным копиям. Каждая копия вычисляет сумму одного столбца матрицы. Все эти суммы столбцов объединяются с помощью функции gplus, чтобы вычислить общую сумму элементов изначального магического квадрата.
function total_sum = colsum
if labindex == 1
% Send magic square to other labs
A = labBroadcast(1,magic(numlabs))
else
% Receive broadcast on other labs
A = labBroadcast(1)
end
% Calculate sum of column identified by labindex for this lab
column_sum = sum(A(:,labindex))
% Calculate total sum by combining column sum from all labs
total_sum = gplus(column_sum)
endСуществуют альтернативные методы получения данных копиями функций, например, создание матрицы в каждой копии или чтение каждой копией своей части данных из файла на диске и т.д.
В прикрепленном файле ml_session.PNG (см. ниже) демонстрируется запуск функции colsum в окне системы Matlab с использованием 4-х вычислительных процессов и максимальным временем счета 1 минута.
Функция хранится как файл colsum.m в каталоге ng5 пользователя (полный путь: /home/u1303/ng5). После запуска imm_sch_f(4,1,'colsum',1,{});, а в более поздних версиях (с учетом переименования служебной функции в imm_sch)
job = imm_sch(4,1,@colsum,1);выдается сообщение вида:
Job output will be written to: /home/u1303/ng5/Job1.mpiexec.outв котором указано имя сформированной работы Job1.
Проверив состояние работы и убедившись, что она закончилась, можно выдать результаты счета.
| Прикрепленный файл | Размер |
|---|---|
| 73.66 КБ |
{kind=link}
Примеры с распределенными массивами
Введение
Распределение данных по процессам предназначено для ускорения счета и экономии памяти.
Параллельные вычисления с использованием распределенных массивов подробно описаны на сайте Matlab, в частности, в подразделе Working with Codistributed Arrays.
Распределенный массив состоит из сегментов (частей), каждый из которых размещен в рабочей области (workspace) соответствующего процесса (lab). При необходимости информацию о точном разбиении массива можно запросить с помощью функции getCodistributor (подробнее см. Obtaining information About the Array). Для просмотра реальных данных в локальном сегменте распределенного массива следует использовать функцию getLocalPart.
Возможен доступ к любому сегменту распределенного массива.
Доступ к локальному сегменту будет быстрее, чем к удаленному, поскольку последний требует посылки (функция labSend) и получения (функция labReceive) данных между процессами.
Содержимое распределенного массива можно собрать с помощью функции gather в один локальный массив, продублировав его на всех процессах или разместив только на одном процессе.
Использование распределенных массивов при параллельных вычислениях сокращает время счета благодаря тому, что каждый процесс обрабатывает свою локальную порцию исходного массива (сегмент распределенного массива).
Существует 3 способа создания распределенного массива (см. Creating a Codistributed Array):
1) деление исходного массива на части,
2) построение из локальных частей (меньших массивов),
3) использование встроенных функций Matlab (типа rand, zeros, ...).
1) Деление массива на части может быть реализовано с помощью функции codistributed (Пример 1). При этом в рабочей области каждого процесса расположены исходный массив в своем полном объеме и соответствующий сегмент распределенного массива. Таким образом, этот способ хорош при наличии достаточного места в памяти для хранения тиражируемого (replicated) исходного массива.
Размерности исходного и распределенного массивов совпадают.
Деление массива может быть произведено по любому из его измерений.
По умолчанию в случае двумерного массива проводится горизонтальное разбиение, т.е. по столбцам, что выглядит естественно с учетом принятого в системе Matlab размещения матриц в памяти по столбцам (как в Фортране).
2) При построении распределенного массива из локальных частей в качестве сегмента распределенного массива берется массив, хранящийся в рабочей области каждого процесса (Пример 2). Таким образом, распределенный массив рассматривается как объединение локальных массивов. Требования к памяти в этом случае сокращаются.
3) Для встроенных функций Matlab (типа rand, zeros, ...) можно создавать распределенный массив любого размера за один шаг (см. Using MATLAB Constructor Functions).
Вверх
Как можно использовать распределенные массивы
В приводимых ниже примерах решение задачи связано с вычислением значений некоторой функции, обозначенной my_func. При этом вычисление одного значения функции требует длительного времени.
Даются возможные схемы решения таких задач с использованием распределенных массивов. Показан переход от исходной последовательной программы к параллельной с распределенными вычислениями. Соответствующие изменения выделены.
Замечание.
Хотя дистрибутивные массивы совместимы (в отличие от цикла parfor и GPU) с глобальными переменными, необходимо тщательно следить за тем, чтобы изменения глобальных переменных в процессе обработки одной порции данных не влияли на результаты обработки других порций, тем самым обеспечивая независимость вычислений частей дистрибутивных массивов.
Там, где допустимо, проще использовать цикл parfor или вычисления на GPU.
Вверх
Пример 1. Деление массива на части
Пусть требуется вычислить значения некоторой функции 10 вещественных переменных. Аргументом функции является 10-мерный вектор.
Значение функции необходимо вычислить для n точек (значений аргумента), заданных 10хn матрицей. Вычисление матрицы производится по некоторому заданному алгоритму и не требует много времени.
Обозначения.my_func - вычисляемая функцияМ - массив для аргументов функции my_funcF - массив для значений функции my_funcM_distr - распределенный массив для M (той же размерности)F_distr - распределенный массив для F (той же размерности)
Исходная программа
Результирующая программа
function test_1()
% инициализация данных
n=1000;
...
% резервирование памяти
M = zeros(10,n);
F = zeros(1,n);
% заполнение матрицы М
...
function test_1()
% инициализация данных
n = 1000;
...
% резервирование памяти
M = zeros(10,n);
F = zeros(1,n);
% заполнение матрицы М
...
% создание распределенных массивов
% разбиение по умолчанию проводится
% по столбцам (2-му измерению)
M_distr = codistributed(M);
F_distr = codistributed(F);
% вычисление функции
for i = 1:n
F(1,i) = my_func(M(:,i));
end
% вычисление функции
for i = drange(1:size(M_distr,2))
F_distr(1,i) = my_func(M_distr(:,i));
end
% сбор результатов на 1-ом процессе
F = gather(F_distr,1);
save ('test_res_1.mat', 'F', 'M');
if labindex == 1
save ('test_res_1.mat', 'F', 'M');
end
return
end
return
end
Пример 2. Построение массива из частей.
Распределенный массив как объединение локальных массивов
Сформировать таблицу значений функции 2-х вещественных переменных ((x,y) --> F) на прямоугольной сетке размера 120x200, заданной векторами (x1:x2:x3 и y1:y2:y3). Существует алгоритм вычисления значения функции в точке , обозначенный my_func.
Обозначения.my_func - вычисляемая функция 2-х переменныхF - массив для значений функции my_funcF_loc - локальный массив, который заполняется соответствующими значениями функции на каждом процессе и затем берется за основу (рассматривается как сегмент) при построении распределенного массива F_distrF_distr - распределенный массив, содержимое которого собирается в массиве F на 1-ом процессе
Вариант 1.
Распараллеливание проводится по внешнему циклу (по x - первому индексу).
Предполагается, что число строк 120 кратно numlabs - числу процессов, заказанных при запуске программы на счет.
Исходная программа
Результирующая программа
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
m_x = x1:x2:x3;
n = 120/numlabs;
% выделение памяти
F = zeros(120,200);
% вычисление функции
i = 1;
for x = x1:x2:x3
...
% выделение памяти
F_loc = zeros(n,200);
% вычисление функции
% i = 1;
for i = 1:n
k = (labindex-1)*n + i;
x = m_x(k);
...
j = 1;
for y = y1:y2:y3
F(i,j) = my_func(x,y);
j = j + 1;
end
i = i + 1;
end
j = 1;
for y = y1:y2:y3
F_loc(i,j) = my_func(x,y);
j = j + 1;
end
% i = i + 1;
end
% распараллеливание проведено по строкам
% (1-му измерению) => codistributor1d(1, ...)
codist = codistributor1d(1, [], [120 200]);
F_distr = codistributed.build(F_loc, codist);
F = gather(F_distr, 1);
save ('test_res_2.mat', 'F');
if labindex == 1
save ('test_res_2.mat', 'F');
end
return
end
return
end
Вариант 2.
Распараллеливание проводится по внутреннему циклу (по y - второму индексу).
Предполагается, что число столбцов 200 кратно numlabs - числу процессов, заказанных при запуске программы на счет.
Исходная программа
Результирующая программа
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
function test_2()
% инициализация данных,
% в частности,
% x1, x2, x3, y1, y2, y3
...
m_y = y1:y2:y3;
n = 200/numlabs;
% выделение памяти
F = zeros(120,200);
% вычисление функции
i = 1;
for x = x1:x2:x3
...
j = 1;
for y = y1:y2:y3
% выделение памяти
F_loc = zeros(120,n);
% вычисление функции
i = 1;
for x = x1:x2:x3
...
% j = 1;
for j = 1:n
k = (labindex-1)*n + j;
y = m_y(k);
F(i,j) = my_func(x,y);
j = j + 1;
end
i = i + 1;
end
F_loc(i,j) = my_func(x,y);
% j = j + 1;
end
i = i + 1;
end
% распараллеливание проведено по столбцам
% (2-му измерению) => codistributor1d(2, ...)
codist = codistributor1d(2, [], [120 200]);
F_distr = codistributed.build(F_loc, codist);
F = gather(F_distr, 1);
save ('test_res_2.mat', 'F');
if labindex == 1
save ('test_res_2.mat', 'F');
end
return
end
return
end
Замечание. Эту задачу, если памяти достаточно, можно запрограммировать и первым способом, т.е. путем деления большого массива на части. В этом случае распределение данных по процессам будет сделано автоматически (требование кратности исчезает).
Вверх
Как убедиться в работоспособности программы
Перед первым запуском программы-функции на кластере ее стоит проверить сначала в однопроцессорном варианте с отладчиком Debug (см.,например, Debug a MATLAB Program), а затем в параллельном режиме pmode. Поскольку политика использования вычислительных ресурсов ИММ УрО РАН не предполагает длительных вычислений на управляющем компьютере, запускать программу в режимах Debug и pmode следует с тестовым набором данных.
Итак, рекомендуется следующая последовательность выхода на счет:
Debug
pmode
кластер
Запуск параллельной программы с отладчиком Debug (в однопроцессорном режиме) можно осуществить, например, предварительно открыв текст программы в редакторе (Editor), установив необходимые контрольные точки (щелкая, к примеру, левой клавишей мыши справа от номера нужной строки) и нажав клавишу F5 (см. пункт меню Debug).
Стартовать режим pmode на 4-х процессах (для наглядности) можно в окне Matlab (Command Window) с помощью команды
pmode start 4Затем в командной строке открывшегося параллельного окна (Parallel Command Window) вызвать свою программу.
Закрыть параллельный режим можно или из Parallel Command Window командой
exitили из окна Matlab командой
pmode exitДля контроля за данными полезна функция getLocalPart.
Запуск на кластере можно осуществить в окне Matlab с помощью функции imm_sch.
Использование параллельного профилирования
Основные понятия
Профилирование предназначено для выявления наиболее затратных по времени мест в программе с целью увеличения ее быстродействия (см. Profile to Improve Performance).
Профилирование параллельных программ определяет как затраты на вычисление функций, так и затраты на коммуникации (см. Profiling Parallel Code).
Профилирование в Matlab осуществляется с помощью инструмента, называемого профилировщик или профайлер (profiler).
Результатом профилирования являются суммарный и детальный отчеты о выполнении программы.
Суммарный отчет о профилировании параллельной программы содержит для каждого параллельного процесса (lab) информацию о времени вычисления функций и частоте их использования, а также о времени, затраченном на обмены (коммуникации) и ожидание обменов с другими процессами.
Для проблемных функций полезно выдавать детальный отчет, в котором содержится статистика по строкам функций, а именно: время выполнения и частота использования.
Код программы можно считать достаточно оптимизированным, если в результате изменения алгоритма большая часть времени выполнения программы будет приходиться на обращения к нескольким встроенным функциям.
Вверх
Действия пользователя
Действия пользователя иллюстрируются на примере функции colsum() по аналогии с функцией foo() из раздела Examples описания команды (функции) mpiprofile.
Внесение изменений в текст программы
1) В заголовок функции добавить выходной параметр для информации о профилировании, назовем его p:
function [p, total_sum] = colsum2) В тело функции добавить команду mpiprofile, а именно:
mpiprofile onдля включения профилирования (начала сбора данных)
mpiprofile offдля выключения профилирования при необходимости (или желании)
p = mpiprofile('info');для доступа к сгенерированным данным и сохранения собранной информации в выходном параметре p.
Пример скорректированной программы приведен ниже в файле ml_prof_colsum.PNG.
Запуск программы на профилирование
1) При запуске функции указать увеличенное соответственно на 1 число выходных параметров.
2) Запустить программу-функцию из командной строки:
mlrun -np 9 -maxtime 5 colsum '2'или в окне Matlab:
j = imm_sch(9,5,@colsum,2);Замечание. Окончания счета при желании можно ждать с помощью команды wait(j).
Просмотр результатов профилирования
Пусть программа запущена в окне Matlab. Тогда по окончании счета следует
1) получить результаты:
out = j.fetchOutputs;2) выделить вектор с информацией о профилировании:
p_vector = [out{:, 1}];3) запустить вьюер:
mpiprofile('viewer', p_vector);Подобные действия для ранних версий приведены ниже в файле ml_prof_session.PNG.
Для повторного использования полученные переменные можно сохранить командой:
save ('res_prof', 'out', 'p_vector')(в файле res_prof.mat) и загрузить при необходимости в другом сеансе:
load ('res_prof')
Вверх
Некоторые советы
Первая реализация программы должна быть настолько проста, насколько возможно, т.е. не рекомендуется ранняя оптимизация.
Профилирование может быть использовано
- в качестве инструмента отладки;
- для изучения (понимания) незнакомых файлов.
При отладке программы детальный отчет даст представление о том, какие строки выполнялись, а какие нет. Эта информация может помочь в расширении набора тестов.
Для очень длинного файла с незнакомым матлабовским кодом можно использовать профайлер, чтобы посмотреть, как файл в реальности работает, т.е. посмотреть вызываемые строки в детальном отчете.
При использовании профилирования копию 1-го детального отчета рекомендуется сохранить в качестве основы для сравнения с последующими, полученными в ходе улучшения программы.
Замечание. Существуют неизбежные отклонения времени, не зависящие от кода, т.е. при профилировании идентичного кода дважды можно получить слегка различные результаты.
| Прикрепленный файл | Размер |
|---|---|
| 38.44 КБ | |
| 85.25 КБ |
{kind=link}
{kind=link}
О реализации работы системы Matlab на кластере
Запуск параллельной программы пользователя на кластере организован в соответствии с рекомендациями разработчиков Matlab в разделах
Programming Distributed Jobs и
Programming Parallel Jobs
с учетом используемого в ИММ планировщика (типа Generic Scheduler в терминологии Matlab).
Замечание. Ссылки на сайт разработчика Matlab даны на момент подключения системы Matlab (~2010).
Для осуществления такого запуска необходимо:
Со стороны системы Matlab
1) Обеспечить наличие функций Submit и Decode.
Функция Submit выполняется Matlab клиентом на хосте (управляющей машине) и основное ее назначение - установить необходимые переменные окружения, в том числе для функции Decode, перед обращением к планировщику (Scheduler).
Функция Decode выполняется автоматически Matlab сервером (worker) на каждом узле и основное ее назначение – забрать переданные планировщиком через переменные окружения значения, которые Matlab worker использует для проведения вычислений на узлах кластера.
2) Задать последовательность действий для описания параллельной работы (Job, точнее ParallelJob), в рамках которой и будут проводиться программой Matlab вычисления функции пользователя на кластере. Основные действия описаны на сайте Matlab и продемонстрированы, в частности, на примере. В ИММ с учетом пакетной обработки эти действия дополнены перехватом stdout и stderr, т.е. установкой свойства CaptureCommandWindowOutput в значение true для всех задач (Task) программируемой работы (Job) (коротко о Job и Task см. в пункте Основные сведения).
С целью дальнейшего многократного использования все необходимые для программирования параллельной работы действия были оформлены в виде служебной функции imm_sch_f (позднее переименованной в imm_sch), обозначенной на рисунке ниже как scheme function. Этой функции в качестве параметров передаются число параллельных процессов, время счета, имя и параметры функции пользователя, предназначенной для распараллеливания вычислений.
Функция imm_sch_f служит для запуска параллельных программ.
При запуске параллельной программы в окне системы Matlab пользователь явно обращается к этой функции.
3) Для своевременного удаления информации о завершенных работах предоставить в распоряжение пользователя функцию job_destroy.
Со стороны планировщика
1) Обеспечить пользователя командой запуска параллельной программы из командной строки, аналогичной mpirun (заменённой впоследствии на mqrun). Эта команда получила название mlrun. При вызове mlrun пользователь указывает число необходимых для счета процессов, максимальное время счета и имя, а при наличии и параметры, программы-функции. Команда mlrun в интерактивном текстовом режиме (-nodisplay) вызывает программу matlab для выполнения функции imm_sch_f (scheme function на рисунке), передавая ей все необходимые аргументы.
2) Обеспечить наличие скрипта, реализующего механизм постановки в очередь программы пользователя, сформированной для запуска на кластере в рамках Matlab. Этот скрипт назван matlab_run.
Используем предлагаемую на сайте Matlab схему запуска программы пользователя на кластере для демонстрации получаемой у нас цепочки вызовов (для определенности на um64 в системе пакетной обработки заданий СУППЗ, 2009 г.).
Источниками для написания собственных функций и скриптов послужили:
1) Ориентированные на Generic Scheduler примеры:
- функций Submit и Decode,
- схемы программирования параллельной работы на хосте в клиентской части Matlab и
- действий по удалению (разрушению, destroy) законченной и ненужной уже работы (Job).
2) Документация (скрипты типа pbsParallelWrapper) в каталогах вида:
/opt/matlab-R2009b/toolbox/distcomp/examples/integration/{pbs|ssh|lsf} где R2009b - название версии
3) Скрипты запуска, такие как mvarun_p2 из каталога
/common/runmvs/binСписок наших служебных функций и скриптов приведен в таблице:
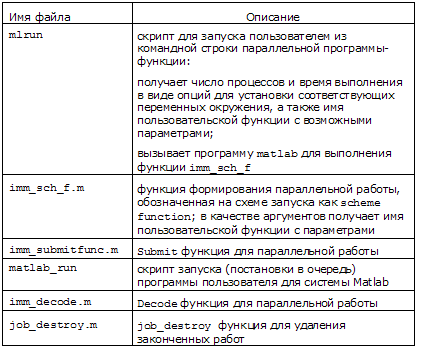
При переходе на новую версию Matlab, например R2010a, следует
- добавить одноименные ссылки в каталог /opt/matlab-R2010a/toolbox/local
на наши служебные Matlab функции, хранящиеся в каталоге /opt/matlab-imm, а именно: imm_sch_f.m, imm_submitfunc.m, imm_decode.m, job_destroy.m ;
- скорректировать файл /etc/profile.d/matlab.sh.
Администрирование кластера
Учетные записи в Slurm
Пользователи и учёт
В Slurm есть две системы учёта пользователей. Первая система основана на системных учётных записях, хранит в служебных файлах обобщённую статистику истории запуска задач и используется для простой системы вычисления приоритетов - share. Вторая система - полноценная система биллинга использует БД для хранения полной истории запуска задач, системы учётных групп (account), ограничений ресурсов (QOS) и т.п.
Первая система не требует использования БД и сохраняет текущую информацию в файлах в каталоге, заданном параметром StateSaveLocation:
assoc_mgr_state, assoc_usage, clustername, dbd.messages,
fed_mgr_state, job_state, last_config_lite, layouts_state_base,
node_state, part_state, priority_last_decay_ran, qos_usage, resv_state, trigger_state
Для запуска задач в первой системе достаточно завести пользователя на уровне ОС. Для второй системы необходимо зарегистрировать его в БД:
sacctmgr -i add user testuser DefaultAccount=root
Ассоциация (Association)
Учёт ресурсов в Slurm ведётся на основе учётных ассоциаций, каждая из которых объединяет четыре понятия:
- кластер;
- учетную группу (account);
- имя пользователя;
- необязательное имя раздела (partition).
Существует порядок создания учетных ассоциаций. Сначала описываются кластеры, потом учетные группы, и лишь потом пользователи. Пользователь при создании ассоциируется с существующей учетной группой, и эта ассоциация применяется по умолчанию для учета его задач.
Создание кластера
Кластер описывается в двух местах: в конфигурации Slurm и в учётной базе данных.
slurm.conf
AccountingStorageType=accounting_storage/slurmdbd
AccountingStoreJobComment=YES
ClusterName=uran
Создание записи в базе:
sacctmgr add cluster uran
Создание учетных групп
- Учетная группа (account) используется для подсчёта ресурсов, использованных для запуска задач в рамках какого-либо договора, проекта и т.п.;
- Накопленные данные об использованных ресурсах влияют на приоритет задач, запускаемых от имени учетной группы;
- Учетная группа может быть использована для установки уровня обслуживания (QOS) задач, запускаемых от имени учетной группы;
- С учетной группой может быть связано произвольное количество пользователей, в том числе ни одного;
- Учетные группы могут быть организованы в иерархическое дерево путём назначения группе родительской группы;
- Верхний уровень иерархии имеет стандартное имя root;
- Имя учетной группы должно быть уникальным и не может быть использовано повторно в другой ветви иерархии учетных групп;
- При подсчете приоритетов учитывается положение группы в иерархии;
- Пользователь может связан с несколькими учетными группами, но должен иметь группу по умолчанию (DefaultAccount).
Примеры команд для создания иерархии организации и иерархии внешних пользователей, работающих по договорам:
sacctmgr add account imm Description="Институт математики и механики" Organization=imm
sacctmgr add account imm_opo Description="Отдел программного обеспечения" Organization=imm_opo parent=imm
sacctmgr add account imm_opo_sector_1 Description="Сектор системного программирования" Organization=imm_opo parent=imm_opo
sacctmgr add account external Description="Внешние пользователи" Organization=external
sacctmgr add account dogovor_10 Description="Договор N10" Organization=external
sacctmgr add account dogovor_11 Description="Договор N11" Organization=external
Отображение созданных учетных записей:
sacctmgr show account format=Account%30,Description%60
sacctmgr show account -s # Показывает ассоциации связанные с аккаунтами
При добавлении или изменении учетной группы доступны следующие параметры:
- Cluster= добавить учетную группу в указанные кластеры. По умолчанию учетная группа добавляется ко всем существующим кластерам.
- Description= описание учетной группы. (По умолчанию - имя учетной группы)
- Name= имя учетной записи.
- Organization= организация на которую зарегистрирована учетная группа. По умолчанию это организация родительской учетной группы, если родительская учетная группа не является корневой. Если родитель root, то при создании по умолчанию используется имя учетной группы.
- Parent= сделать эту учетную группу дочерним элементом другой учетной группы (уже существующей).
Создание пользователей
Создание пользователя Slurm с именем xxx и учетной группой по умолчанию (обязательно) yyy:
sacctmgr create user name=xxx DefaultAccount=yyy
При необходимости пользователи могут также добавляться в дополнительные учетные группы, например:
sacctmgr add user xxx Account=zzzz
Имя учетной группы может указываться в пакетных заданиях пользователя, например, с помощью sbatch :
-A <account> или --account=<account>
Список пользователей:
sacctmgr show user #показывает пользователей и их учетные группы по умолчанию
sacctmgr show user -s #показывает пользователей и все их ассоциации
sacctmgr show user -s test_user #выдает учетные группы пользователя test_user
При добавлении или изменении пользователя доступны следующие параметры:
- Account= Учетная группа(ы) для добавления пользователя (см. также DefaultAccount ).
- AdminLevel= Это поле используется, чтобы позволить пользователю добавлять учетные привилегии этому пользователю. Возможные варианты:
- None
- Operator - может добавлять/изменять/удалять любой объект базы данных (пользователь, учетная запись и т. Д.) и добавлять других операторов. На SlurmDBD, обслуживаемом slurmctld, эти пользователи могут: просматривать информацию, которая блокируется для регулярного использования флагом PrivateData; создавать/изменять/удалять бронирование.
- Admin - эти пользователи имеют тот же уровень привилегий, что и оператор в базе данных. Они также могут изменять что-либо в slurmctld, как если бы они были пользователем slurm или root.
- Cluster= добавлять к ассоциациям только на этих кластерах (по умолчанию все кластеры)
- DefaultAccount= учетная группа по умолчанию. (обязательный параметр).
- DefaultWCKey= пользовательский ключ по умолчанию для пользователя, используемый, когда не указан WCkey при отправке задания. (Используется только при отслеживании WCkey .)
- Name= имя пользователя
- Partition= Название раздела Slurm, к которому относится данная ассоциация.
Изменение и удаление объектов
При изменении свойств объектов и при их удалении можно задавать параметры в стиле SQL, используя ключевые слова WERE и SET. Некоторые параметры, например имя объекта, изменить нельзя. Типичная команда имеет следующий вид:
sacctmgr modify <entity> set <options> where <options>
Например:
sacctmgr modify user set DefaultAccount=none where DefaultAccount=test
меняет у пользователей учетную группу по умолчанию "test" на "none".
Удаление пользователя из учетной группы:
sacctmgr remove user brian where Account=imm_opo
Удаление пользователей означает, в первую очередь, удаление ассоциаций.
После того, как объект был добавлен, изменен или удален, соответствующие изменения отправляются соответствующим демонам Slurm и мгновенно становятся доступными для использования.
Примечание. В большинстве случаев удаленные объекты сохраняются, но помечены как удаленные. Если объект существовал менее 1 дня, то он будет удален полностью. Такое поведение предназначено для защиты от опечаток.
Печать объектов
sacctmgr show cluster|account|user [-s] format=account%20,description%40 [<name>]
sacctmgr show cluster|account|user [-s] [-n] -p [<name>]
- -s показывает связанные объекты
- format= задает список полей и количество символов, отводимых на поле
- -n - без строки заголовка
- -p - формат удобный для программного разбора
Использованы материалы со страницы https://wiki.fysik.dtu.dk/niflheim/Slurm_accounting
Ограничение ресурсов в Slurm
Для ограничения ресурсов необходимо включить в slurm.conf строку:
AccountingStorageEnforce=limits
TRES
Ресурсы, который можно отслеживать и использовать для ограничения, называются TRES. TRES - это комбинация типа и имени. В настоящий момент используются следующие типы TRES:
- пакетные буферы - burst buffers (BB)
- ЦПУ (CPU)
- энергия (Energy)
- GRES
- лицензии (License)
- память (Mem)
- узлы (Node)
- вычисляемый (Billing)
Вычисляемый TRES рассчитывается из TRESBillingWeights раздела. Он предварительно вычисляется во время планирования для каждого раздела, чтобы обеспечить соблюдение лимитов. После завершения задачи он пересчитывается по реально использованным ресурсам. Пример TRESBillingWeights:
TRESBillingWeights="CPU=1.0,Mem=0.25G,GRES/gpu=2.0"
Установка ограничений на пользователя:
sacctmgr modify user xxx set MaxTRES=cpu=1000 MaxTRESMinsPerJob=6000 GrpTRESMins=60000
Ограничения с префиксом Max - обозначают максимальный ресурс на одну задачу, с префиксом Grp - суммарное количество ресурсов на все задачи, когда либо запущенные пользователем (на самом деле, история потихоньку очищается и предел не является абсолютным) . В данном примере задано ограничение счёта одной задачи в 100 часов на 1000 процессорах и суммарное время в 1000 часов.
QOS
Качество обслуживания (QOS) объединяет несколько ограничений на TRES. Конфигурация QOS должна иметь как минимум стандартное значение QOS с названием normal. Дополнительные QOS'ы могут переопределять ограничения.
Например, QOS high256 с высоким приоритетом и ограничением на количество ЦПУ :
sacctmgr add qos high256 priority=10 MaxTRESPerUser=cpu=256
Просмотр существующих QOS:
sacctmgr show qos
Назначение пользователю DefaultQOS:
sacctmgr -i modify user where name=XXXX set DefaultQOS=normal
Назначение дополнительных QOS пользователю:
sacctmgr -i modify user where name=XXXX set QOS=normal,high
sacctmgr -i modify user where name=XXXX set QOS+=high
Для того, чтобы воспользоваться дополнительным QOS пользователи должны указывать его в параметрах sbatch, например:
sbatch --qos=high256 ...
Иерархия ограничений
Ограничения Slurm применяются в следующем порядке:
- QOS раздела (partition)
- QOS задания
- Ограничение ассоциации пользователя (user+account+cluster)
- Ограничение ассоциации учетной группы (account+cluster), по возрастанию иерархии
- Ассоциация root_account+cluster
- Ограничения раздела
- Нет ограничений
Выдача отчётов в Slurm
Запросить информацию по заданиям, используя следующие команды:
- sacct - отображает данные всех заданий (завершившихся/считающихся/ждущих очереди);
- sreport [options] - генерирует отчеты из данных учета Slurm;
- sstat <JobID> - отображает информацию (использование памяти, ЦПУ и т.д) о считающейся задаче по её JobID ;
- seff <JobID> - отображает эффективность использования ЦПУ и памяти завершившейся задачей по её JobID ;
- scontrol show jobs - отображает состояние запущенных задач;
- scontrol show assoc_mgr - отображает текущее содержимое внутреннего кэша slurmctld для пользователей, ассоциаций и/или qos.
sacct
Просмотр задач конкретного пользователя:
sacct -u user
Просмотр задач всех пользователей:
sacct -a
Начало и конец периода:
sacct --start=2018-07-01 --end=2018-07-15
sreport
Примеры использования sreport для создания отчетов:
sreport cluster UserUtilizationByAccount
sreport cluster AccountUtilizationByUser
Показать статистику в виде дерева учетных карточек (accounts):
sreport cluster AccountUtilizationByUser tree
Выбрать один аккаунт
sreport Accounts=extusers
Вывести отчета в виде таблицы с разделителем '|' для дальнейшей обработки скриптами:
sreport -p ...
Выбор диапазонов дат:
sreport ... start=2018-06-01 end=2018-06-30
sreport ... start=`date -d "last month" +%D` end=`date -d "this month" +%D`
Изменение формата даты/времени в заголовке отчета (форматы в man strftime):
env SLURM_TIME_FORMAT = "%d-%b-%Y_%R" sreport ...
Задание единиц времени, отображаемых в потреблении ресурсов (по умолчанию - минуты):
sreport -t hourper ...
Задание TRES, отображаемых в потреблении ресурсов -T, tres= (по умолчанию - cpu):
sreport -T cpu,mem,gres/gpu ...
Выдача биллинга в У.Е.:
sreport --tres=billing ...
Показать учетные записи пятидесяти самых активных пользователей за 2017 год:
sreport user top start=2017-01-01 end=2017-12-31 TopCount=50 -t hourper --tres=cpu,GRES/gpu
Отчет об использовании кластера:
sreport -t hourper cluster Utilization
Отчет об использовании кластера по пользователям, сгруппированным в ассоциации:
sreport cluster AccountUtilizationByUser start=2019-04-01 end=2019-05-21 --tres=cpu,GRES/gpu,billing
Конфигурационный файл slurm.conf
Проверка синтаксиса slurm.conf без запуска slurm
slurmctld -c
Логирование событий в syslog
Ошибки при логировании Windows в syslog
evtsys.exe выдаёт ошибку OpenPublisherMetadata failed for Publisher: "ПРИЛОЖЕНИЕ"
Сообщение об ошибке означает, что evtsys.exe не удалось интерпретировать часть сообщения журнала с помощью API Windows. Журнала событий Windows (EVTX) сохраняет не всё сообщение, а только его идентификатор. Чтобы иметь возможность прочитать сообщение, необходим файл DLL, который содержит все сообщения журнала ПРИЛОЖЕНИЯ с их идентификаторами.
При пересылке сообщений с другого компьютера возможна ситуация, когда нужная DLL отсутствует.
Решение
На компьютере источнике сообщений найти имя DLL в реестре по адресу: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\EventLog\ найти нужное приложение, а в нем параметр с именем DLL — EventMessageFile. Также потребуется файл MUI, с дополнительным расширением .mui к имени файла DLL. Например, для WindowsDefender имя подраздела будет System\WinDefend, файл DLL — %ProgramFiles%\Windows Defender\MpEvMsg.dll, а файл MUI %ProgramFiles%\Windows Defender\ru_RU\MpEvMsg.dll.mui.
Файлы DLL и MUI надо скопировать в какой-нибудь каталог на сервере с evtsys.exe и зарегистрировать командой:
New-EventLog -Source "Microsoft-Windows-Search" -LogName "Windows_Defender" -MessageResourceFile "SOME_PATH\MpEvMsg.dll"
Ограничение доступа к ANSYS (ansyslmd.opt)
Файл ansyslmd.opt
Разрешение на запуск программ из семейства ANSYS выдаётся сервером лицензий. Правила доступа задаются в файле ansyslmd.opt. Файл расположен на сервере лицензий в каталоге /opt/ansys_inc/shared_files/licensing/license_files/.
Права доступа задаются для пользователя (USER), группы пользователей (GROUP), хоста (HOST) или группы хостов (HOST_GROUP). Имена пользователей, хостов и групп регистрозависимы.
Группы описываются в этом же файле. Пользователь или хост должны входить только в одну группу.
GROUP Users1 alice bob john
GROUP Users2 Jane Mary
HOST_GROUP Cluster_Hоsts host1 host2 host 3
Права доступа
Разрешения и запрещения определяются директивами INCLUDE, INCLUDEALL, EXCLUDE, EXCLUDEALL. INCLUDE и EXCLUDE задают доступ к отдельным лицензируемым функциям (features). INCLUDEALL и EXCLUDEALL включают/выключают все доступные функции.
Доступ разрешён только тем пользователям/хостам, которые указаны в директиве INCLUDE. EXCLUDE позволяет вычеркнуть кого-то из тех, кто перечислен в INCLUDE. Порядок написания правил не важен. В любом случае сначала составляется список INCLUDE, тем, кто в него не попал, доступ запрещён. Потом применяются правила EXCLUDE. Тем, кто попал под эти правила, доступ тоже запрещён.
Пример. Все пользователи, кроме перечисленных в Users2, имеют право использовать все функции, на которые есть лицензии, с хостов перечисленных в группе Cluster_Hоsts.
Пользователи из группы Users1 могут использовать все функции на любых компьютерах, имеющих доступ к серверу лицензий, за исключением пользователя alice, которой запрещён доступ к лицензии на aa_r.
Пользователи группы Users2 не имеют доступа к ANSYS.
INCLUDEALL Cluster_Hоsts
INCLUDEALL GROUP Users1
EXCLUDEALL GROUP Users2
EXCLUDE aa_r USER alice
Ограничение числа лицензий и времени их использования
Пользователи из группы Users1 не могут захватить больше чем две лицензии aa_r одновременно.
Пользователь bob не может удерживать лицензию aa_r дольше чем двадцать часов.
MAX 2 aa_r GROUP Users1
MAX_BORROW_HOURS USER bob 20
Резервирование лицензий
Если лицензии зарезервированы за пользователем, хостом или группой, то они не могут быть выданы никому другому
Например, все сто доступных лицензий на кластерные вычисления aa_r_hpc зарезервированы за узлами кластера Cluster_Hоsts и не могут использоваться на других хостах.
RESERVE 100 aa_r_hpc Cluster_Hоsts
Структура БД Slurm
Большинство таблиц содержат колонки: время создания, время модификации, признак удаления - creation_time, mod_time, deleted.
tres_table Словарь ресурсов TRES
- creation_time
- deleted
- id Числовой идентификатор - ключ
- type Тип ресурса
- name Имя
Для резервирования первых 999 id под системные нужды в таблицу внесена запись id=1000, type=dynamic_offset, помеченная как удаленная. При обращении из sreport к пользовательским TRES, tres type пишется заглавными буквами:
sreport cluster AccountUtilizationByUser start=2019-04-01 end=2019-05-21 --tres=GRES/gpu
acct_table Таблица учетных групп
- name,description,organization
user_table Таблица пользователей
- name, admin_level
super_assoc_table Таблица ассоциаций пользователь-учетная группа на кластере
- id_assoc - уникальный номер
- deleted - операция acctmgr remove удаляет запись, если она была создана несколько минут назад, иначе помечает, как удаленную.
- user,acct - пара пользователь-учетная группа. У учетной группы поле user пустое, поле acct пустым не бывает.
- parent_acct - родительская учетная группа. Бывает только у учетной группы.
- lft,rgt - загадочные поля.
super_job_table Таблица заданий на кластере super
- job_db_inx - уникальный индекс. Введён, поскольку id_job назначается за пределами DB.
- id_job - числовой id задачи
- account - текстовое имя учетной группы. Используется sacct при формировании списка заданий учетной группы.
- id_assoc - номер ассоциации
- id_user, id_group - системные UID,GID без привязки к assoc_table
- nodelist - список узлов в формате slurm (node[3-5,7]). Есть особое значение 'None assigned'
- nodes_alloc - число узлов
- node_inx - список узлов в виде их числовых индексов (3-5,108-212)
- work_dir - рабочий каталог. Поле появилось с какой то версии Slurm. До того пустой.
- time_submit, time_start, time_end - времена в формате unix timesatmp.
В SQL функция UNIX_TIMESTAMP('2018-09-01 12:00:00'). Обратное преобразование FROM_UNIXTIME(1447430881); - state - числовое значение состояния задачи
Значения state
enum job_states {
JOB_PENDING, /* queued waiting for initiation */
JOB_RUNNING, /* allocated resources and executing */
JOB_SUSPENDED, /* allocated resources, execution suspended */
JOB_COMPLETE, /* completed execution successfully */
JOB_CANCELLED, /* cancelled by user */
JOB_FAILED, /* completed execution unsuccessfully */
JOB_TIMEOUT, /* terminated on reaching time limit */
JOB_NODE_FAIL, /* terminated on node failure */
JOB_PREEMPTED, /* terminated due to preemption */
JOB_BOOT_FAIL, /* terminated due to node boot failure */
JOB_DEADLINE, /* terminated on deadline */
JOB_OOM, /* experienced out of memory error */
JOB_END /* not a real state, last entry in table */
};
super_step_table Таблица параллельных задач (step), сформированных командами srun в рамках одного задания. Один srun - одна задача (step).
- job_db_inx - связь с таблицей job_table
- id_step - номер шага от 0 и далее, -2 - особый случай batch - формируется через sbatch.
- time_start, time_end - индивидуальные времена шагов. job.time_start=min(step.time_start), job.time_end=max(step.time_end).
- task_cnt - количество запущенных srun процессов (каждый из которых может занимать несколько ядер).
Извлечение задач на кластере super по номеру задания
select j.id_job,j.job_name,s.step_name,j.nodelist,s.nodelist,j.nodes_alloc,s.nodes_alloc,s.id_step
from super_job_table as j
join super_step_table as s
on j.job_db_inx=s.job_db_inx
where j.id_job=24747;
Задания на кластере super, не сумевшие стартовать задачу
select j.id_job
from super_job_table as j
left join super_step_table as s
on j.job_db_inx=s.job_db_inx
where s.job_db_inx IS NULL
super_assoc_usage_month/day/hour_table Агрегированные данные по использованию кластера super. Используются при выдаче статистики через sreport. Похоже, что в основном используется таблица super_assoc_usage_day_table
- creation_time
- mod_time
- deleted
- id - фактически это id_assoc - номер ассоциации
- id_tres - код ресурса. Берется из таблицы tres_table
- time_start - время старта задачи, округленное до месяца/дня/часа
- alloc_secs - выделенное время
Интеграция Linux и Active Directory
Существует несколько путей для интеграции Linux компьютеров в домен. Часть из них построена на использовании специализированной программ winbind из пакета Samba, а часть использует автономные PAM и NSS модули для непосредственного взаимодействия с сервером домена.
Общие настройки OpenLDAP
Пути к файлам, использованные на этой странице, относятся к дистрибутивам Linux CentOS 6/7.
Основные файлы конфигурации
/etc/openldap/slapd.conf
Конфигурация LDAP-сервера slapd. Содержимое файла для запуска slapd в режиме прокси описано в статье"OpenLDAP в режиме прокси для Active Directory".
/etc/openldap/ldap.conf
Базовая конфигурация клиентов из пакета OpenLDAP (ldapsearch, ldapwhoami, slapd в режиме прокси). Параметры из этого файла могут быть перезаписаны в командной строке. Этот файл не влияет на демон nslcd - у того свои настройки LDAP в /etc/nslcd.conf.
/etc/nslcd.conf
Конфигурация демона nslcd, который обеспечивает доступ к LDAP кэширующему серверу имен nscd. Конфигурационный файл описан в разделе "Имена пользователей и групп из LDAP (nslcd)".
Создание баз slapd
Используется два основных каталога для хранения баз /etc/openldap/slapd.d и /var/lib/ldap. Первый каталог используется для хранения конфигурации в виде базы database config. Второй - для хранения локальной базы записей LDAP или (в режиме прокси) для хранения кэша модулем pcache. В каталоге /var/lib/ldap для корректного создания базы должен находиться файл DB_CONFIG.
cp /usr/share/openldap-servers/DB_CONFIG.example /var/lib/ldap/DB_CONFIG
Конфигурация slapd может храниться в двух форматах: в файле /etc/openldap/slapd.conf и в каталоге /etc/openldap/slapd.d. Конфигурация из каталога имеет больший приоритет, поэтому при изменениях файла /etc/openldap/slapd.conf надо удалить базу /etc/openldap/slapd.d и сгенерировать ее заново:
sudo rm -rf /etc/openldap/slapd.d/*; sudo -u ldap slaptest -f /etc/openldap/slapd.conf -F /etc/openldap/slapd.d -v -d -1
slaptest проверяет синтаксис slapd.conf, строит базу config в /etc/openldap/slapd.d и пытается создать bdb/hdb базы (если они описаны в slapd.conf) в /var/lib/ldap. Опция -d -1 - обеспечивает выдачу отладочной информации, что бывает полезно для поиска ошибок в файле конфигурации.
Иногда при генерации баз в /var/lib/ldap slaptest выдает ошибку:
Checking configuration files for : bdb_db_open:
db_open(/var/lib/ldap/id2entry.bdb) failed: No such file or directory (2)
В этом случае имеет смысл один раз запустить slapd от root'а (с опцией отладки, чтобы он не ушел в фоновый режим), а потом поменять владельца сгенерированых файлов.
slapd -d -1; chown -R ldap:ldap /var/lib/ldap
Целостность баз slapd
Для обеспечения целостности баз соответствующая библиотека ведёт логи транзакций, которые позволяют восстановить базу в случае сбоя на диске или аварийного отключения питания. Логи транзакций накапливаются в каталоге /var/lib/ldap/ с именами вида log.0000000001, log.0000000002 и т.д.
Для кеширующего прокси целостность баз не имеет значения, поэтому сохранение логов транзакций можно отключить, добавив в файл /var/lib/ldap/DB_CONFIG строку set_flags DB_LOG_AUTOREMOVE
Запись логов
Для записи логовов slapd в конфигурационный файл syslog/rsyslog необходимо добавить правило
local4.* /var/log/ldap.log
Отладка slapd
Для отладки slapd запускается с опцией -d N, где N - число, каждый бит которого включает определенный тип отладочной печати. При запуске с опцией отладки slapd не уходит в фоновый режим и выдает отладочную печать на stderr. slapd -d -1 включает вывод всей доступной отладочной печати. Запуск slapd с опцией -d \? выдает список допустимых значений отладочных режимов и мнемонические обозначения для них. В зависимости от подключенных модулей-оверлеев, список отладочных режимов может меняться. В частности, модуль pcache добавляет свой отладочный флаг. При запуске slapd -d pcache выдается предупреждение, что используется неверный флаг отладки, но работает как надо.
Если есть желание отлаживать slapd, запущенный в фоновом режиме, то вместо опции -d следует использовать -s - запись в syslog.
Список битов, используемых с опциями -d и -s
Any (-1, 0xffffffff)
Trace (1, 0x1)
Packets (2, 0x2)
Args (4, 0x4)
Conns (8, 0x8)
BER (16, 0x10)
Filter (32, 0x20)
Config (64, 0x40)
ACL (128, 0x80)
Stats (256, 0x100)
Stats2 (512, 0x200)
Shell (1024, 0x400)
Parse (2048, 0x800)
Sync (16384, 0x4000)
None (32768, 0x8000)
pcache (4096, 0x1000)
Мониторинг нагрузки
В slapd.conf включаем монитор и разрешаем доступ локальному root'у
database monitor
access to *
by dn.exact="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" read
by * none
Просмотр данных
#Просмотр разделов, доступных для опроса
ldapsearch -Y EXTERNAL -H ldapi:/// -b 'cn=Monitor'
#Просмотр конкретного раздела
ldapsearch -Y EXTERNAL -H ldapi:/// -b 'cn=Statistics,cn=Monitor' -s base '(objectClass=*)' '*' '+'
Пример использования ldapsearch
Для отладки можно формировать запросы к LDAP-серверу командой ldapsearch. Например:
ldapsearch -H ldap://localhost/ -x -b "dc=example,dc=com" -LLL '(sAMAccountName=testuser)'
Тестирование запроса nslcd:
ldapsearch -H ldap://localhost/ -x -b "ou=People,dc=example,dc=com" \
-LLL '(&(&(&(&(objectClass=user)(!(objectClass=computer)))(uidNumber=*)) \
(unixHomeDirectory=*))(sAMAccountName=testuser))'`
OpenLDAP в режиме прокси для Active Directory
Общие настройки slapd описаны в статье "Общие настройки OpenLDAP".
Предполагается, что slapd выступает кэширующим прокси между Linux компьютерами в локальной сети и внешним сервером AD, работающим под управлением Win2008R2 или старше. Задачей кэширующего сервера является обеспечение отказоустойчивости при кратковременных разрывах связи с сервером АД. Клиентом выступает Linux с сервером nslcd. Соответствующая конфигурация nslcd описана в отдельной статье.
Для доступа к LDAP в AD заведен пользователь Manager с паролем secret.
Изменение схемы LDAP
В поставке CentOS нет схемы LDAP из AD. Отсутствие необходимых атрибутов приводит к тому, что запросы с этими атрибутами не обрабатываются модулем pcache, причём без какой-либо диагностической информации.
Источником схемы может быть репозиторий https://github.com/dkoudela/active-directory-to-openldap + доработка схемы NIS, в которую для совместимости с AD добавлено имя атрибута 'unixHomeDirectory', причем, обязательно в первой позиции.
/etc/openldap/schema/nis.schema
attributetype ( 1.3.6.1.1.1.1.3 NAME ('unixHomeDirectory' 'homeDirectory')
DESC 'The absolute path to the home directory'
EQUALITY caseExactIA5Match
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26 SINGLE-VALUE )
Ещё один вариант (неполный) схемы AD в прикреплённом файле. Источник схемы.
Тестирование кэша
Для проверки работоспособности кэша необходимо запустить сервер в режиме отладки slapd -d 4096 и заставить nslcd обратиться к нему (например выполнив команду nscd -i passwd;id testuser).
В хорошем случае при первом запросе атрибутов пользователя в логе будут строки вида :
QUERY NOT ANSWERABLE
QUERY CACHEABLE
при повторных запросах будет выдаваться
QUERY ANSWERABLE (answered 3 times)
В плохом случае постоянно будут выдаваться строки
QUERY NOT ANSWERABLE
QUERY NOT CACHEABLE
Файлы конфигурации
Ниже перечислены конфигурационные файлы в которые надо внести изменения.
/etc/sysconfig/ldap
Файл содержит опции, которые используются при запуске slapd командой systemctl start slapd или service slapd start
#Явно перечисляем интерфейсы по которым будет доступен прокси
SLAPD_LDAP=no
SLAPD_LDAPI=no
SLAPD_LDAPS=no
SLAPD_URLS="ldapi:/// ldap://192.168.1.1/ ldap://192.168.2.1/ ldap://127.0.0.1/"
/etc/openldap/ldap.conf
В этом файле важен параметр TLS_REQCERT allow. Без него невозможно подключиться к серверу АД с самоподписанным сертификатом.
#URI - адрес сервера. Протокол доступа может быть ldap: и ldaps:
URI ldaps://ldapserver.example.com/
#BASE - ветка дерева LDAP в которой ведется поиск
BASE dc=example,dc=com
#TLS_CACERTDIR - путь к каталогу с сертификатами SSL для установки защищенного соединения с сервером
TLS_CACERTDIR /etc/openldap/certs
#TLS_REQCERT - что делать если сертификат сервера не найден. 'allow' - продолжить соединение
TLS_REQCERT allow
/etc/openldap/slapd.conf
Основной конфигурационный файл
# Схема из репозитория https://github.com/dkoudela/active-directory-to-openldap
# nis.schema с небольшой модификацией
include /etc/openldap/schema_ad/microsoftattributetype.schema
include /etc/openldap/schema_ad/microsoftattributetypestd.schema
include /etc/openldap/schema_ad/corba.schema
include /etc/openldap/schema_ad/core.schema
include /etc/openldap/schema_ad/cosine.schema
include /etc/openldap/schema_ad/duaconf.schema
include /etc/openldap/schema_ad/dyngroup.schema
include /etc/openldap/schema_ad/inetorgperson.schema
include /etc/openldap/schema_ad/java.schema
include /etc/openldap/schema_ad/misc.schema
include /etc/openldap/schema_ad/nis.schema
include /etc/openldap/schema_ad/openldap.schema
include /etc/openldap/schema_ad/ppolicy.schema
include /etc/openldap/schema_ad/collective.schema
include /etc/openldap/schema_ad/microsoftobjectclass.schema
#Источник данных
database ldap
suffix "DC=example,DC=com"
uri ldap://ldap.example.com/
rootdn "OU=People,DC=example,DC=com"
rebind-as-user yes
# От чьего имени подключаемся к АД
idassert-bind bindmethod=simple
binddn="CN=Manager,DC=example,DC=com"
credentials="secret"
mode=none
# Кто может подключаться к нам (все - анонимно и без авторизации)
idassert-authzFrom "*"
# Опциональное отображение атрибутов passwd на схему AD
# в нашем варианте оно делается на уровне nslcd
#moduleload rwm
#overlay rwm
#rwm-map attribute uid sAMAccountName
#rwm-map attribute dn distinguishedName
#rwm-map attribute homeDirectory unixHomeDirectory
#rwm-map attribute gecos displayName
# Кэширование
# Загрузка модуля и включение оверлея к базе LDAP
moduleload pcache.la
overlay pcache
# pcache <database> <max_entries> <numattrsets> <entry_limit> <cc_period>
# параметры базы:
# <database> for cached entries.
# <max_entries> when reached - cache replacement is invoked
# <numattrsets> = pcacheAttrset
# <entry_limit> limit to the number of entries returned
# <cc_period> Consistency check time to wait
# в базе в формате BerkleyDB хранится 2000 записей, один набор атрибутов/фильтров с индексом 0
pcache hdb 2000 1 1000 300
#кэшируем все атрибуты (0 - индекс)
pcacheattrset 0 *
#шаблон запроса должен в точности совпадать с указанным, иначе запрос не кэшируется
#нужные шаблоны запросов можно отследить, запустив slapd в отладочном режиме - slapd -d 4096
#ниже приведены шаблоны запросов nslcd в CentOS 7 с модификацией фильтра, описанной в http://parallel.uran.ru/node/408
#кэшируем перечисленные запросы и храним их 900 секунд (0 - индекс)
pcacheTemplate (&(&(objectClass=)(uidNumber=*)(unixHomeDirectory=*))(uidNumber=)) 0 900 120
pcacheTemplate (&(&(objectClass=)(uidNumber=*)(unixHomeDirectory=*))(sAMAccountName=)) 0 900 120
pcacheTemplate (&(objectClass=)(uidNumber=*)(unixHomeDirectory=*)) 0 900 120
pcacheTemplate (&(|(objectClass=)(objectClass=))(|(memberUid=)(member=))) 0 900 120
pcacheTemplate (&(|(objectClass=)(objectClass=))(gidNumber=)) 0 900 120
pcacheTemplate (&(|(objectClass=)(objectClass=))(memberUid=)) 0 900 120
pcacheTemplate (&(|(objectClass=)(objectClass=))(cn=)) 0 900 120
# максимальный размер запроса
sizelimit unlimited
# путь к базе
directory /var/lib/ldap
cachesize 200
# индексы для ускорения доступа
index objectClass eq,pres
index member
index ou,cn,mail,surname,givenname eq,pres,sub
index uidNumber,gidNumber,loginShell eq,pres
index uid,memberUid eq,pres,sub
index nisMapName,nisMapEntry eq,pres,sub
Ссылки
| Прикрепленный файл | Размер |
|---|---|
| 4.09 КБ |
Имена пользователей и групп из LDAP (nslcd)
Всё необходимое для получения имен пользователей из LDAP в CentOS 7 находится в пакете nss-pam-ldapd. Этот пакет добавляет модуль pam_ldap.so в библиотеку libpam, модуль libnss_ldap.so в библиотеку libnss и сервер nslcd (работающий в связке с кэширующим сервером nss - nscd), который и выполняет запросы к LDAP серверу.
В файле /etc/nsswitch.conf необходимо добавить ldap, как источник данных для баз passwd, group и shadow:
passwd: files ldap
shadow: files ldap
group: files ldap
В файле /etc/nslcd.conf гнобходимо настроить сервер LDAP и набор запросов к нему. Запросы включают фильтры, которые позволяют выбрать записи относящиеся к той или иной базе, и отображения стандартных имен в базе на эквивалентные по смыслу имена, которые использует схема LDAP на сервере. В примерах есть пара рабочих вариантов настроек для доступа к серверу Active Directory (AD). Для сервера slapd из OpenLDAP модификация запросов, скорее всего, не требуется.
# Выбираем записи имеющие атрибуты uidNumber и unixHomeDirectory
# При запросе к фильтру добавляется &(sAMAccountName=username)
#
# Не совсем понятно зачем явно отбрасываются записи для компьютеров.
# Возможно существуют сценарии с назначением компьютеру атрибута unixHomeDirectory.
filter passwd (&(objectClass=user)(!(objectClass=computer))(uidNumber=*)(unixHomeDirectory=*))
# Отображение полей passwd на атрибуты AD
map passwd uid sAMAccountName
map passwd homeDirectory unixHomeDirectory
map passwd gecos displayName
Сложнее с вариантом, когда для доступа к AD используется slapd в режиме кэширующего прокси, используемого для отказоустойчивости при кратковременных обрывах связи с сервером AD. Этот прокси не кэширует запросы с фильтром, использующим операцию "НЕ", а следовательно, и запрос из предыдущего примера. Для работы через кэширующий прокси рабочим оказался упрощённый вариант фильтра:
filter passwd (&(objectClass=user)(uidNumber=*)(unixHomeDirectory=*))
Авторизация пользователей в Kerberos (pam_krb5 и другие)
Ссылки:
Linux: SSH + LDAP(Kerberos) - http://xvoids.blogspot.ru/2008/09/linux-rhel-ssh-kerberos-ldapad.html
Аутентификация в apache используя Active Directory и kerberos - http://val-khmyrov.blogspot.ru/2011/04/apache-active-directory-kerberos.html
Прокси сервер Squid в Active Directory с Kerberos аутентификацией - http://www.theadmin.ru/linux/squid/proksi-server-squid-v-active-directory-s-kerberos-autentifikaciej/
Admin Guide for Mod_auth_kerb - http://www.its.mn/hp_docs/apache/mod_auth_kerb.admin.guide mod_auth_kerb - http://modauthkerb.sourceforge.net/configure.html
Kerberos Single Signon with Joomla! or other PHP apps - http://sammoffatt.com.au/knowledge-base-mainmenu/9-joomla/7-kerberos-single-signon-with-joomla-or-other-php-apps
Using mod_auth_kerb and Windows 2000/2003/2008R2 as KDC - http://www.grolmsnet.de/kerbtut/
Контакты
По всем вопросам, связанным с работой суперкомпьютерного вычислительного центра ИММ УрО РАН, можно обращаться в отдел системного обеспечения Института математики и механики УрО РАН.
тел: (343) 375-35-11, (343) 375-35-13, e-mail: parallel@imm.uran.ru